Boosting Zero-shot Learning via Contrastive Optimization of Attribute Representations 제3-4부 method
and are defined in the visual space as a result of the semantic-to-visual mapping (from s to ).
및 는 의미론적 시각 매핑(에서 까지)의 결과로 시각 공간에서 정의됩니다.
Apart from them, we follow [12], [13] to define another loss in the semantic space as a result of the visual-to-semantic mapping (from to ).
그것들과는 별도로 우리는 [12], [13]에 따라 시각적-의미론적 매핑(에서 로)의 결과로 의미론적 공간에서 또 다른 손실을 정의합니다.
This loss helps different channel maps in AM focus on different attribute-related regions in image x: we apply Softmax and max-pooling to each feature map of and get vector in the semantic space whose j-th value indicates the maximum response of j-th attribute in the image.
이 손실은 AM의 다양한 채널 맵이 이미지 x의 다른 속성 관련 영역에 초점을 맞추는 데 도움이 된다. 우리는 의 각 특징 맵에 Softmax와 max-pooling을 적용하고 j번째 값이 이미지에서 j번째 속성의 최대 응답을 나타내는 의미 공간에서 벡터 를 얻는다.
Assuming x belongs to the class i, we minimize the L2 distance between and the ground truth class semantics :
x가 클래스 i에 속한다고 가정하면 와 실측 클래스 의미론 사이의 L2 거리를 최소화합니다.
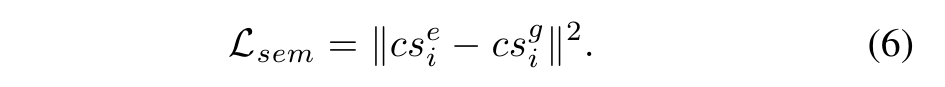
E. Loss function
The overall loss function for our framework is,

and are defined for one image, we use e to denote the corresponding average loss in one batch so as to match with and .
및 은 하나의 이미지에 대해 정의되며, 및 와 일치하도록 e를 사용하여 한 배치의 해당 평균 손실을 나타냅니다.
, , are corresponding loss coefficients.
, , 은 대응하는 손실 계수입니다
F. Alternative: Transformer-based architecture.
alternatvie 대체, 대안
Inspired by the success of vision transformer (ViT) [49], we provide an alternative backbone for our framework using the ViT.
ViT(Vision Transformer)[49]의 성공에 영감을 받아 ViT를 사용하여 프레임워크에 대한 대체 백본을 제공합니다.
This change affects the left part of the framework for class- and attribute-level feature embedding (see Fig. 2 bottom): given the input image x, it is sliced into P evenly squared patches of size Q × Q.
이 변화는 클래스 및 속성 수준 기능 임베딩을 위한 프레임워크의 왼쪽 부분에 영향을 미친다(그림 2 하단 참조). 입력 이미지 x가 주어지면 Q × Q 크기의 P 균등 제곱 패치로 잘린다.
evenly 균등하게
They are embedded via the transformer encoder to obtain the feature tensor .
특성 텐서 를 얻기 위해 트랜스포머 인코더를 통해 포함됩니다.
Positional embedding is added to patch embedding to keep the position information.
위치 정보를 유지하기 위해 패치 임베딩에 위치 임베딩이 추가됩니다.
Unlike the CNN-based architecture, the class-level feature is directly embedded by adding an extra learnable classification token [CLS].
CNN 기반 아키텍처와 달리 클래스 수준 기능 는 학습 가능한 분류 토큰[CLS]을 추가하여 직접 포함됩니다.
For attribute-level features, we adopt a similar attention-based attribute localization scheme to the CNN-based architecture: is passed through a convolutional layer to produce the attended feature tensor , whose j-th channel map serves as a soft mask for the j-th attribute localization.
속성 수준 기능의 경우 CNN 기반 아키텍처와 유사한 주의 기반 속성 현지화 방식을 채택한다. F는 컨볼루션 레이어를 통과하여 참석된 특징 텐서 를 생성하며, 그 j번째 채널 맵 는 j번째 속성 현지화를 위한 소프트 마스크 역할을 한다.
is bi-linearly pooled with F (see (3)) to obtain the attribute-level features .
은 속성 수준 특성 를 얻기 위해 F와 쌍선형으로 풀링됩니다((3) 참조).
