Boosting Zero-shot Learning via Contrastive Optimization of Attribute Representations 제3-3부 method
Contrastive optimization of attribute-level features against attribute prototypes.
속성 프로토타입에 대한 속성 수준 기능의 대조적 최적화.
Given the set of attribute-level features for the input image x, we first filter out those attributelevel features whose corresponding attention maps have low peak values, i.e. ; these attention maps normally fail to localize corresponding attributes.
입력 이미지 x에 대한 속성 레벨 특징 AF의 세트를 감안할 때, 먼저 해당 주의 맵 가 낮은 피크 값, 즉 를 갖는 속성 레벨 특징 를 필터링합니다. 이러한 주의 맵은 일반적으로 해당 속성을 지역화하지 못합니다.
For a batch of images, we denote the eligible set of attribute-level features after filtering as .
denote 나타내다 eligible 적합한
이미지 배치의 경우 필터링 후 적합한 속성 수준 기능 집합을 로 표시합니다.
Given any , we want to optimize it to be close to its corresponding attribute prototype and be far from the other attribute prototypes in the embedding space.
가 주어지면 해당 속성 프로토타입 에 가깝고 임베딩 공간에서 다른 속성 프로토타입 와 멀리 떨어지도록 최적화하려고 합니다.
A triplet loss function suits this purpose:
triplet 삼중항
삼중항 손실 함수는 다음과 같은 목적에 적합합니다:
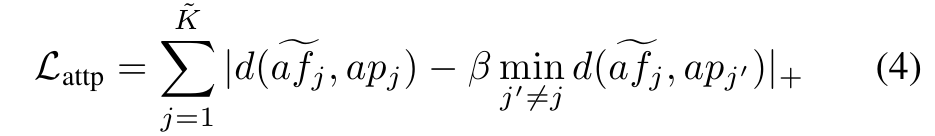
where d(·, ·) is the cosine distance (one minus cosine similarity), β is a hyperparameter to control the extent of pulling away from .
여기서 d(·,·)는 코사인 거리(1 - 코사인 유사도), β는 에서 가 멀어지는 정도를 제어하는 하이퍼파라미터입니다.
denotes the Relu function which enforces to be smaller than the minimal distance (times β) from to other .
는 가 에서 다른 까지의 최소 거리(β 곱하기)보다 작아지도록 강제하는 Relu 함수를 나타냅니다.
Hard example-based contrastive optimization of attribute features across images.
이미지 전반의 속성 특징에 대한 하드 예제 기반 대조 최적화.
Besides , we introduce a new hard-example based contrastive optimization loss to reinforce the attribute representation learning: it pulls attribute-level features across images corresponding to the same attribute to be close; corresponding to different attributes to be away.
외에, 우리는 속성 표현 학습을 강화하기 위해 새로운 하드 예제 기반 대조 최적화 손실을 소개합니다 : 동일한 속성에 해당하는 이미지에서 속성 수준 기능을 가까이 가져옵니다. 멀리 떨어져있을 다른 속성에 해당합니다.
Similar to above, instead of using all attribute-level features, we only keep those with high-peak values, i.e. .
위와 유사하게 모든 속성 수준 기능을 사용하는 대신 와 같이 피크 값이 높은 기능만 유지합니다.
Further more, for every in , we have other features correspond-ing to the same attribute to as its positives; we keep only hard positives whose cosine similarities to are smaller than .
더 나아가 의 모든 에 대해 의 긍정적인 속성과 동일한 속성에 해당하는 다른 기능이 있습니다. 에 대한 코사인 유사도가 보다 작은 hard positives 만 유지합니다.
Similarly, hard negatives are those features who correspond to different attributes to f and whose cosine similarities to are larger than 1 − t.
마찬가지로, 하드 네거티브 은 f 에 대한 다른 속성에 해당하고 에 대한 코사인 유사성이 1 - t보다 큰 특징입니다.
The reason of using hard examples is to leave certain space for the intra-attribute variation.
어려운 예제를 사용하는 이유는 속성 내 변형을위한 특정 공간을 남겨 두기 위해서입니다.
We use the SupCon loss [44] for the objective function:
목적 함수에 대해 SupCon 손실[44]을 사용합니다:
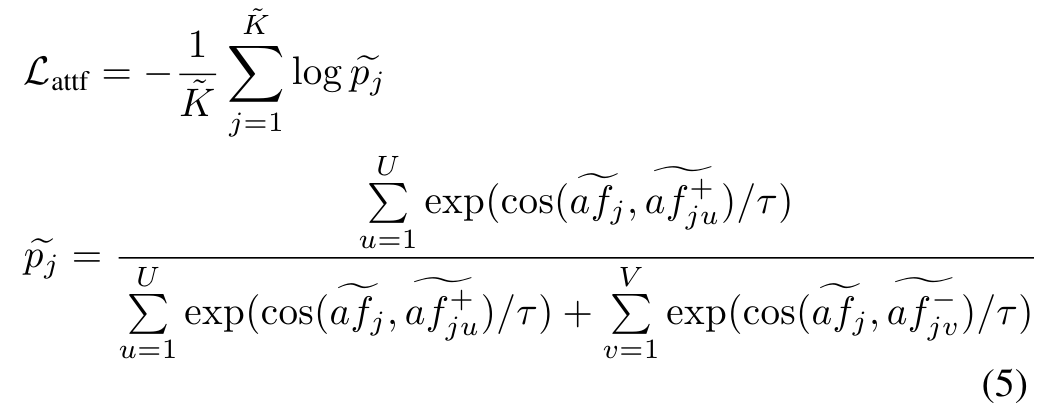
where we iterate in and average the loss values; τ is a scalar temperature.
여기서 우리는 에서 를 반복하고 손실 값을 평균화합니다. τ는 스칼라 온도입니다.
