Contrastive Embedding for Generalized Zero-Shot Learning 제4-3부
Total loss
In our final hybrid GZSL framework, we replace the semantic embedding (SE) model in the basic hybrid framework in Eq.4 with the proposed contrastive embedding (CE) model.
최종 하이브리드 GZSL 프레임워크에서 Eq.4의 기본 하이브리드 프레임워크에 있는 SE(Semantic Embedding) 모델을 제안된 CE(Contrastive Embedding) 모델로 대체합니다.
As described above, the contrastive embedding model consists of an instance-level loss function and a class-level loss function .
위에서 설명한 바와 같이 대조 임베딩 모델은 인스턴스 수준 손실 함수 와 클래스 수준 손실 함수 로 구성됩니다.
Thus, the total loss of our final hybrid GZSL framework with contrastive embedding (CE-GZSL) is formulated as:
따라서 대조 임베딩(CE-GZSL)이 있는 최종 하이브리드 GZSL 프레임워크의 총 손실은 다음과 같이 공식화됩니다.
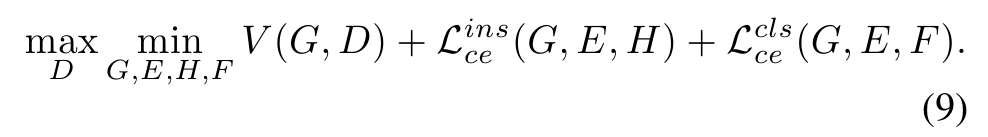
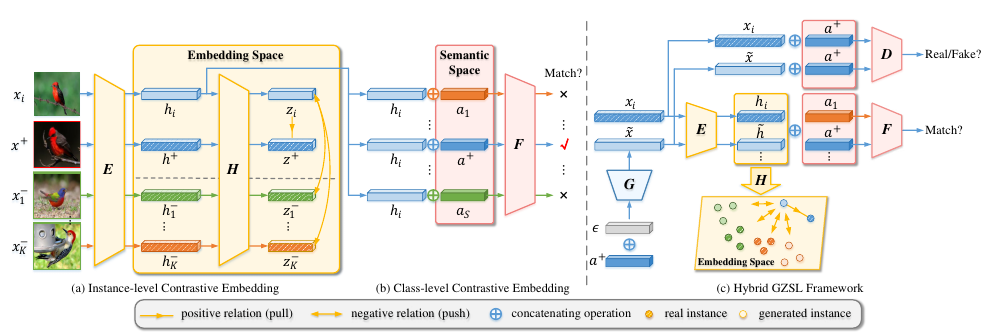

Illustration of our proposed hybrid GZSL framework with contrastive embedding (CE-GZSL).
그림 2: 대조 임베딩(CE-GZSL)이 있는 제안된 하이브리드 GZSL 프레임워크의 그림.
We learn an embedding function E that maps the visual samples into the embedding space as .
시각적 샘플 x_i를 임베딩 공간에 로 매핑하는 임베딩 함수 E를 배웁니다.
We further learn a non-linear projection H to better constrain the embedding space: .
임베딩 공간을 더 잘 제한하기 위해 비선형 투영 H를 더 학습합니다. .
We introduce a comparator network F that measures the relevance score between and the semantic descriptors.
와 의미 설명자 사이의 관련성 점수를 측정하는 비교기 네트워크 F를 소개합니다.
We learn the embedding function with both the instance-level and the class-level supervisions.
우리는 인스턴스 수준과 클래스 수준 감독 모두를 사용하여 임베딩 기능을 배웁니다.
We integrate the contrastive embedding model with the feature generation model.
우리는 대조적 임베딩 모델을 특징 생성 모델과 통합합니다.
In the feature generation model, the feature generator G learns to produce visual features based on a semantic descriptor a and a Gaussian noise ;
특징 생성 모델에서 특징 생성기 G는 의미 설명자 a와 가우스 잡음 을 기반으로 시각적 특징을 생성하는 방법을 학습합니다.
and the discriminator D aims to distinguish the fake visual features from real ones.
판별자 D는 가짜 시각적 특징을 실제 것과 구별하는 것을 목표로 합니다.
Figure 2 illustrates the whole structure of our method. In our method, we learn a feature generator G (together with a discriminator D) to synthesize the missing unseen class features;
그림 2는 우리 방법의 전체 구조를 보여줍니다. 우리의 방법에서, 우리는 누락된 보이지 않는 클래스 특징을 합성하기 위해 특징 생성기 G(판별자 D와 함께)를 배웁니다.
we learn an embedding function E to embed the samples, both real and synthetic, to a new embedding space, where we conduct the final GZSL classification;
실제 및 합성 샘플을 모두 새로운 임베딩 공간에 임베딩하기 위해 임베딩 함수 E를 배웁니다. 여기서 최종 GZSL 분류를 수행합니다.
to learn a more effective embedding space, we introduce a non-linear projection H in the embedding space which is used to define the instance-level contrastive embedding loss;
더 효과적인 임베딩 공간을 배우기 위해, 인스턴스 레벨 대조 임베딩 손실을 정의하는 데 사용되는 임베딩 공간에 비선형 투영 H를 도입합니다.
and to enforce the class-wise supervision, we learn a comparator network F to compare an embedding and a semantic descriptor.
클래스별 감독을 시행하기 위해 비교기 네트워크 F를 학습하여 임베딩과 의미론적 설명자를 비교합니다.
GZSL classification
We first generate the features for each unseen class in the embedding space by composing the feature generator network G and the embedding function , where and is the semantic descriptor of an unseen class.
먼저 기능 생성기 네트워크 G와 임베딩 함수 를 구성하여 임베딩 공간에서 보이지 않는 각 클래스에 대한 기능을 생성합니다. 여기서 및 는 보이지 않는 클래스의 의미론적 설명자입니다.
We map the given training features of seen classes in into the same embedding space as well: .
에서 본 클래스의 주어진 훈련 기능을 동일한 임베딩 공간에도 매핑합니다: .
In the end, we utilize the real seen samples and the synthetic unseen samples in the embedding space to train a softmax model as the final GZSL classifier.
결국, 우리는 최종 GZSL 분류기로 softmax 모델을 훈련시키기 위해 임베딩 공간에서 실제 본 샘플과 보이지 않는 합성 샘플을 사용합니다.
