Contrastive Embedding for Generalized Zero-Shot Learning 제5부
4. Experiments
Datasets
We evaluate our method on five benchmark datasets for ZSL: Animals with Attributes 1&2 (AWA1 [39] & AWA2 [69]), Caltech-UCSD Birds-200-2011 (CUB) [65], Oxford Flowers (FLO) [52], and SUN Attribute (SUN) [55].
우리는 ZSL에 대한 다섯 가지 벤치 마크 데이터 세트에 대한 우리의 방법을 평가합니다 : 속성 1 & 2 (AWA1 [39] 및 AWA2 [69]), Caltech-UCSD Birds-200-2011 (CUB) [65], Oxford Flowers (FLO) [52] 및 SUN 속성 (SUN) [55]을 가진 동물.
AWA1 and AWA2 share the same 50 categories and each category is annotated with 85 attributes, which we use as the class-level semantic descriptors. AWA1 contains 30,475 images and AWA2 contains 37,322 images; CUB contains 11,788 images from 200 bird species; FLO contains 8,189 images of 102 fine-grained flower classes; SUN contains 14,340 images from 717 different scenes and each class is annotated with 102 attributes.
AWA1과 AWA2는 동일한 50개의 카테고리를 공유하고 각 카테고리에는 85개의 속성으로 주석이 달려 있습니다. AWA1에는 30,475개의 이미지가 포함되어 있고 AWA2에는 37,322개의 이미지가 포함되어 있습니다. CUB에는 200종의 새에서 11,788개의 이미지가 포함되어 있습니다. FLO에는 102개의 세분화된 꽃 클래스에 대한 8,189개의 이미지가 포함되어 있습니다. SUN에는 717개의 서로 다른 장면에서 가져온 14,340개의 이미지가 포함되어 있으며 각 클래스에는 102개의 속성으로 주석이 달려 있습니다.
For the semantic descriptors of CUB and FLO, we adopt the 1024-dimensional class embeddings generated from textual descriptions [57].
CUB 및 FLO의 시맨틱 디스크립터에 대해 텍스트 설명에서 생성된 1024차원 클래스 임베딩을 채택합니다[57].
We extract the 2,048-dimensional CNN features for all datasets with ResNet-101 [27] pre-trained on ImageNet-1K [37] without finetuning.
우리는 ResNet-101[27]이 ImageNet-1K[37]에서 사전 훈련된 미세 조정 없이 모든 데이터 세트에 대해 2,048차원 CNN 기능을 추출합니다.
Moreover, we adopt the Proposed Split (PS) [69] to divide all classes on each dataset into seen and unseen classes.
또한 PS(Proposed Split)[69]를 채택하여 각 데이터 세트의 모든 클래스를 보이는 클래스와 보이지 않는 클래스로 나눕니다.
Implementation Details
We implement our method with PyTorch. On all datasets, we set the dimension of the embedding h to 2,048, and set the dimension of the non-linear projection’s output z to 512.
우리는 PyTorch로 방법을 구현합니다. 모든 데이터 세트에서 임베딩 h의 차원을 2,048로 설정하고 비선형 투영의 출력 z의 차원을 512로 설정했습니다.
The comparator network F is a multi-layer perceptron (MLP) containing a hidden layer with LeakyReLU activation.
비교기 네트워크 F는 LeakyReLU 활성화가 있는 은닉층을 포함하는 다층 퍼셉트론(MLP)입니다.
The comparator network F takes as input the concatenation of an embedding h and a semantic descriptor a, and outputs the relevance estimation between them.
concatenation 연결성
비교기 네트워크 F는 임베딩 h와 의미 설명자 a의 연결을 입력으로 취하고 이들 사이의 관련성 추정을 출력합니다.
Our generator G and discriminator D both contain a 4096-unit hidden layer with LeakyReLU activation.
생성기 G와 판별기 D는 모두 LeakyReLU 활성화가 있는 4096단위 은닉층을 포함합니다.
We use a random mini-batch size of 4,096 for AWA1 and AWA2, 2,048 for CUB, 3,072 for FLO, and 1,024 for SUN in our method.
우리의 방법에서는 AWA1 및 AWA2에 대해 4,096, CUB에 2,048, FLO에 3,072, SUN에 1,024의 임의 미니 배치 크기를 사용합니다.
In the mini-batch, the instances from the same class are positive instances to each other, while the instances from different classes are negative instances to each other.
미니 배치에서 동일한 클래스의 인스턴스는 서로에 대한 긍정적인 인스턴스이고 다른 클래스의 인스턴스는 서로에 대한 부정적인 인스턴스입니다.
The large batch size ensures a large number of negative instances in our method.
큰 배치 크기는 우리 방법에서 많은 수의 음수 인스턴스를 보장합니다.
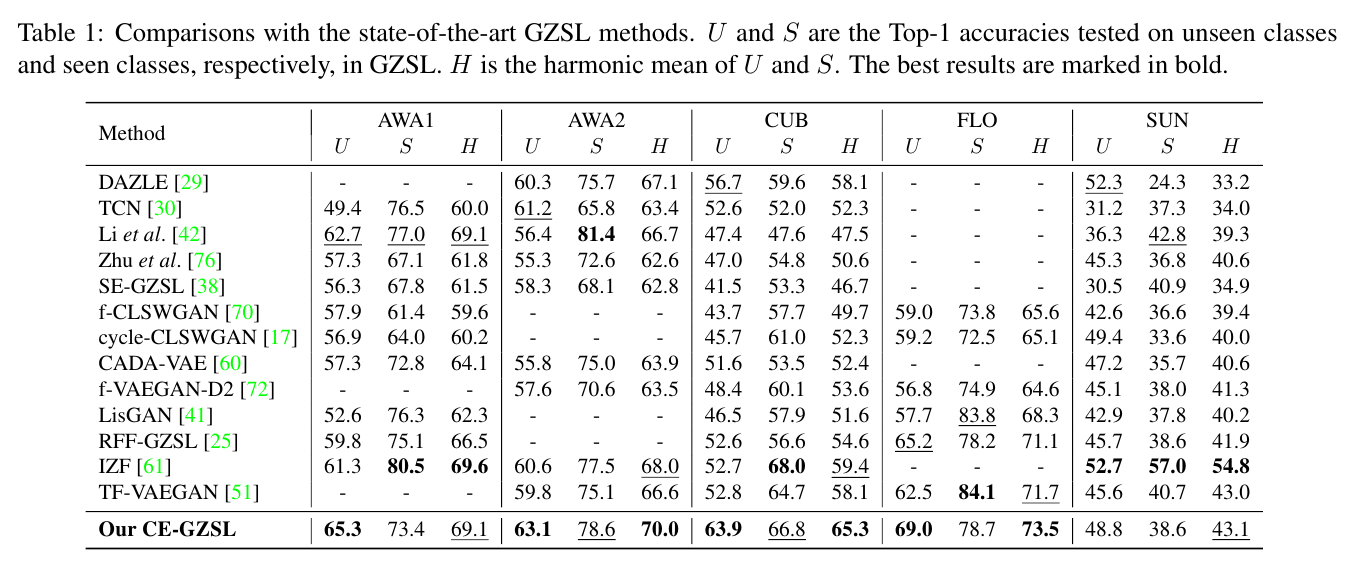
Comparisons with the state-of-the-art GZSL methods. U and S are the Top-1 accuracies tested on unseen classes and seen classes, respectively, in GZSL. H is the harmonic mean of U and S. The best results are marked in bold.
최신 GZSL 방법과의 비교. U와 S는 GZSL에서 각각 보이지 않는 클래스와 본 클래스에 대해 테스트된 Top-1 정확도입니다. H는 U와 S의 조화 평균입니다. 최상의 결과는 굵게 표시됩니다.

Results of conventional ZSL. The first six methods are early conventional ZSL methods and the following ten methods are recent proposed GZSL methods.
기존 ZSL의 결과. 처음 6가지 방법은 초기의 기존 ZSL 방법이고 다음 10가지 방법은 최근에 제안된 GZSL 방법입니다.
The best results and the second best results are respectively marked in bold and underlined.
가장 좋은 결과와 두 번째로 좋은 결과는 각각 굵게 표시되고 밑줄이 그어집니다.
4.1 Comparison with SOTA
In Table 1, we compare our CE-GZSL method with the state-of-the-art GZSL methods. Our method achieves the best U on four datasets and achieves the best H on AWA2, CUB, and FLO.
표 1에서는 CE-GZSL 방법과 최신 GZSL 방법을 비교합니다. 우리의 방법은 4개의 데이터 세트에서 최고의 U를 달성하고 AWA2, CUB 및 FLO에서 최고의 H를 달성합니다.
Notably, on CUB, our CE-GZSL is the first one that obtains the performances > 60.0 on U and H among the state-of-the-art GZSL methods.
notabley 특히
특히 CUB에서 당사의 CE-GZSL은 최첨단 GZSL 방식 중 U 및 H에서 60.0 이상의 성능을 얻은 최초의 제품입니다.
Especially, our hybrid GZSL method integrating with the simplest generative model still achieves competitive results compared with IZF [61], which is based on the most advanced generative model in GZSL.
히, 가장 단순한 생성 모델과 통합된 하이브리드 GZSL 방법은 GZSL에서 가장 진보된 생성 모델을 기반으로 하는 IZF[61]와 비교하여 여전히 경쟁력 있는 결과를 달성합니다.
Our CE-GZSL achieves the second best H on AWA1 and SUN, and is only lower than IZF [61], and on the other three datasets our CE-GZSL outperforms IZF [61] by a large margin.
CE-GZSL은 AWA1 및 SUN에서 두 번째로 우수한 H를 달성하고 IZF[61]보다 낮고 다른 세 데이터 세트에서 CE-GZSL은 IZF[61]보다 큰 차이로 성능이 뛰어납니다.
In Table 2, we report the results of our CE-GZSL under the conventional ZSL scenario.
표 2에서는 기존 ZSL 시나리오에서 CE-GZSL의 결과를 보고합니다.
We compare our method with sixteen methods, in which six of them are traditional methods and ten of them are the recent methods.
우리는 우리의 방법을 16가지 방법과 비교하는데, 그 중 6가지가 전통적인 방법이고 그 중 10가지가 최근 방법입니다.
Our method is still competitive in conventional ZSL. Our method performs the best on CUB and the second best on AWA1 and FLO in the conventional ZSL scenario.
우리의 방법은 기존 ZSL에서 여전히 경쟁력이 있습니다. 우리의 방법은 기존 ZSL 시나리오에서 CUB에서 최고 성능을 발휘하고
Specifically, on CUB, our method also achieves an excellent performance, and our CE-GZSL is the only method that can achieve the performance > 70.0 under conventional ZSL among the ten recent methods.
구체적으로 CUB에서도 우리의 방법이 우수한 성능을 보여주며, 우리의 CE-GZSL은 최근 10가지 방법 중 기존 ZSL에서 70.0 이상의 성능을 얻을 수 있는 유일한 방법이다.
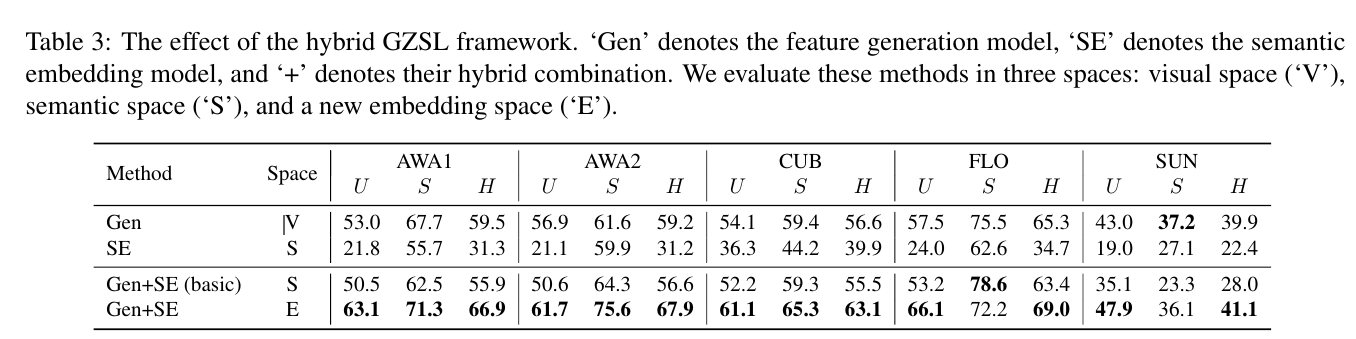
The effect of the hybrid GZSL framework. ‘Gen’ denotes the feature generation model, ‘SE’ denotes the semantic embedding model, and ‘+’ denotes their hybrid combination.
하이브리드 GZSL 프레임워크의 효과. 'Gen'은 기능 생성 모델을, 'SE'는 시맨틱 임베딩 모델을, '+'는 하이브리드 조합을 나타냅니다.
We evaluate these methods in three spaces: visual space (‘V’), semantic space (‘S’), and a new embedding space (‘E’).
우리는 이러한 방법을 시각적 공간('V'), 의미 공간('S'), 새로운 임베딩 공간('E')의 세 가지 공간에서 평가합니다.
4.2 Component Analysis
In Table 3, we illustrate the effectiveness of the hybrid strategy for GZSL. First, we respectively evaluate the performances of the single feature generation model (Gen) and the single semantic embedding model (SE).
표 3에서는 GZSL에 대한 하이브리드 전략의 효율성을 보여줍니다. 먼저 단일 기능 생성 모델(Gen)과 단일 의미적 임베딩 모델(SE)의 성능을 각각 평가합니다.
We evaluate them in their original space: visual space (V) for ‘Gen’ and semantic space (S) for ‘SE’.
우리는 그것들을 원래 공간인 'Gen'에 대한 시각적 공간(V)과 'SE'에 대한 의미 공간(S)에서 평가합니다.
‘Gen+SE (basic)’ denotes that we simply combine the feature generation model with the semantic embedding model and learn a softmax classifier in semantic space, corresponding to the basic hybrid GZSL approach defined in Eq.4.
'Gen+SE(basic)'는 단순히 기능 생성 모델을 시맨틱 임베딩 모델과 결합하고 의미 공간에서 소프트맥스 분류기를 학습하는 것을 의미하며, 이는 식 4에 정의된 기본 하이브리드 GZSL 접근 방식에 해당합니다.
Moreover, we introduce a new embedding space (E) in the hybrid GZSL method, which leads to the increased performance.
또한 하이브리드 GZSL 방법에 새로운 임베딩 공간(E)을 도입하여 성능을 향상시킵니다.
The results show that the hybrid GZSL strategy is effective, and the new embedding space is better than the semantic space.
결과는 하이브리드 GZSL 전략이 효과적이며 새로운 임베딩 공간이 의미 공간보다 우수함을 보여줍니다.
