facilitated 가능하게하다, 용이하게하다 ,촉진하다
3. Convolutional vision Transformer
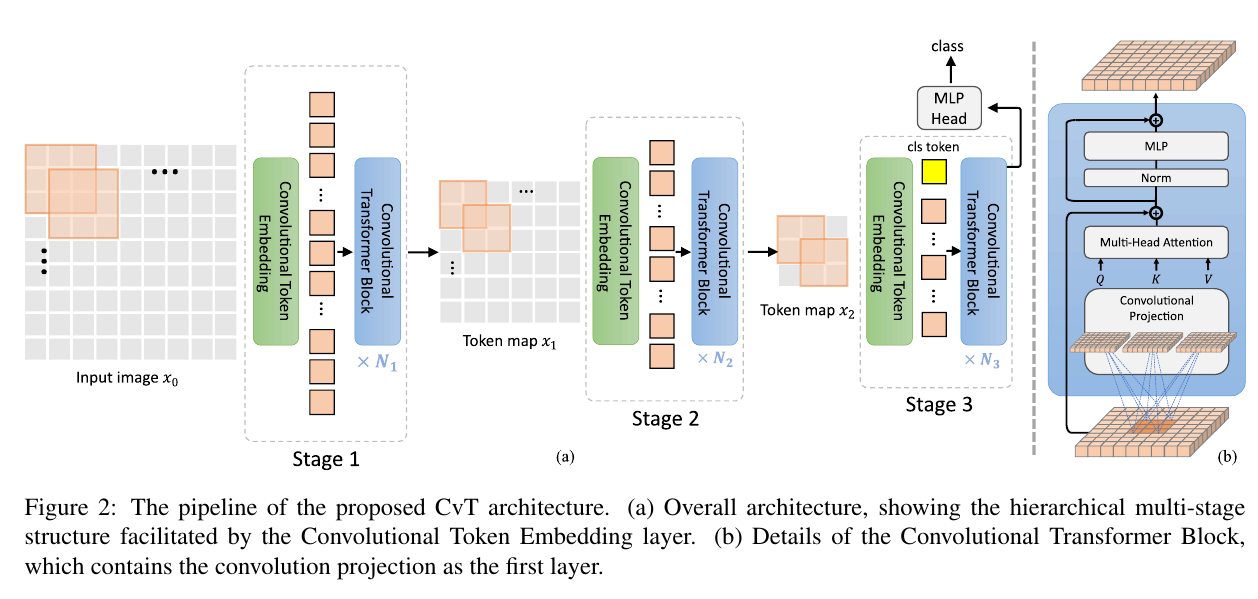
The overall pipeline of the Convolutional vision Transformer (CvT) is shown in Figure 2.
We introduce two convolution-based operations into the Vision Transformer architecture, namely the Convolutional Token Embedding and Convolutional Projection.
namely 즉 operations 작업
Convolutional Token Embedding과 Convolutional Projection이라는 두 가지 컨볼루션 기반 작업을 Vision Transformer 아키텍처에 도입합니다.
As shown in Figure 2 (a), a multi-stage hierarchy design borrowed from CNNs [20, 15] is employed, where three stages in total are used in this work.
borrowed from ~에서 차용한, 빌린
그림 2(a)와 같이 CNN[20, 15]에서 차용한 다단계 계층 구조 설계가 사용되며 이 작업에서는 총 3단계가 사용됩니다.
Each statge has two parts.
First, the input image (or 2D reshaped token maps) are subjected to the Convolutional Token Embedding layer, which is implemented as a convolution with overlapping patches with tokens reshaped to the 2D spatial grid as the input (the degree of overlap can be controlled via the stride length).
subject 받다, 지배하에 두다 implemented 이행하다 실행하다
먼저, 입력 이미지(또는 2D 재구성된 토큰 맵)는 컨볼루션 토큰 임베딩 레이어(Convolutional Token Embedding layer)를 받게 되는데, 이는 입력으로서 2D 공간 그리드로 재형상화된 토큰과 겹치는 패치와의 컨볼루션으로 구현된다(중첩의 정도는 스트라이드 길이를 통해 제어될 수 있다).
An additional layer normalization is applied to the tokens.
토큰에 추가 계층 정규화가 적용됩니다.
This allows each stage to progressively reduce the number of tokens (i.e. feature resolution) while simultaneously increasing the width of the tokens (i.e. feature dimension), thus achieving spatial downsampling and increased richness of representation, similar to the design of CNNs.
allows 허락하다, 가능하게하다
이를 통해 각 단계는 토큰 수를 점진적으로 줄이면서 동시에 토큰의 너비 (예 : 기능 차원)를 증가시켜 CNN의 설계와 마찬가지로 공간 다운 샘플링과 표현의 풍부함을 높일 수 있습니다.
Different from other prior Transformer-based architectures [11, 30, 41, 34], we do not sum the ad-hod position embedding to the tokens.
ad-hod 임시방편의
다른 이전 Transformer 기반 아키텍처[11, 30, 41, 34]와 달리 토큰에 대한 임시 위치 임베딩을 합산하지 않습니다.
Next, a stack of the proposed Convoluional Transformer Blocks comprise the remainder of each stage.
다음으로 제안된 Convolutional Transformer Block의 스택은 각 단계의 나머지 부분을 구성합니다.
Figure 2 (b) shows the architecture of the Convolutional Transformer Block, where a depth-wise separable convolution operation [5], referred as Convolutional Projection, is applied for query, key, and value embeddings respectively, instead of the standard position-wise linear projection in ViT [11].
respectively 각각의 referred as ~로 언급 appliy 적용되다
그림 2(b)는 Convolutional Transformer Block의 아키텍처를 보여줍니다. 여기서 Convolutional Projection이라고 하는 깊이별 분리 가능한 컨볼루션 연산[5]은 표준 위치 방식 대신 쿼리, 키 및 값 임베딩에 각각 적용됩니다. (표쥰 ViT의 선형 투영 [11].)
Additionally, the classification token is added only in the last stage.
또한 분류 토큰은 마지막 단계에서만 추가됩니다.
Finally, an MLP (i.e. fully connected) Head is utilized upon the classification token of the final stage output to predict the class.
utilized upon 에 활용
마지막으로, 클래스를 예측하기 위해 최종 단계 출력의 분류 토큰에 MLP(즉, 완전 연결) 헤드가 활용됩니다.
We first elaborate on the proposed Convolutional Token Embedding layer.
elaborate 자세히 설명하다
먼저 제안된 컨볼루션 토큰 임베딩 레이어에 대해 자세히 설명한다.
Next we show how to perform Convolutional Projection for the Multi-Head Self-Attention module, and its efficient design for managing computational cost.
다음으로 우리는 다중 헤드 셀프 어텐션 모듈에 대한 컨볼루션 투영 수행 방법과 계산 비용 관리를 위한 효율적인 설계를 보여준다.
3.1 Convolutional Token Embedding
This convolution operation in CvT aims to model local spatial contexts, from low-level edges to higher order semantic primitives, over a multi-stage hierarchy approach, similar to CNNs.
aim to v : v하는 것을 목표로 하다 primitives 원시, 초기의
CvT의 이 컨볼루션 연산은 CNN과 유사한 다단계 계층 접근 방식을 통해 저수준 에지에서 고차 의미론적 기본 요소에 이르기까지 로컬 공간 컨텍스트를 모델링하는 것을 목표로 합니다.
Formally, given a 2D image or a 2D-reshaped output token map from a previous stage 'as the input to stage i, we learn a function that maps into new tokens '' with a channel size ,
map 매핑한다
공식적으로, 이전 단계 의 2D 이미지 또는 2D 형상의 출력 토큰 맵이 단계 i에 입력으로 주어지면, 우리는 을 채널 크기 를 가진 새로운 토큰 에 매핑하는 함수 를 학습한다.
where f(·) is 2D convolution operation of kernel size s × s, stride s − o and p padding (to deal with boundary conditions).
여기서 f(·)는 커널 크기 s × s, 보폭 s − o 및 p 패딩(경계 조건을 처리하기 위해)의 2D 컨볼루션 연산입니다.
The new token map has height and width
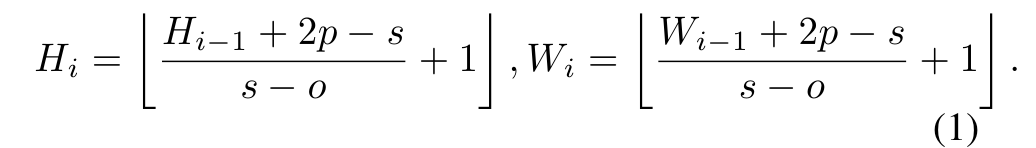
is then flattened into size and normalized by layer normalization [1] for input into the subsequent Transformer blocks of stage i.
는 크기 로 평면화되고 단계 i의 후속 변압기 블록에 입력하기 위해 계층 정규화 [1]에 의해 정규화됩니다.
The Convolutional Token Embedding layer allows us to adjust the token feature dimension and the number of tokens at each stage by varying parameters of the convolution operation.
varying 다양한
컨볼루션 토큰 임베딩 레이어를 사용하면 컨볼루션 작업의 다양한 매개 변수를 통해 각 단계에서 토큰 특징 치수와 토큰 수를 조정할 수 있다.
In this manner, in each stange we progressively decrease the token sequence length, while increasing the token feature dimension.
이러한 방식으로 각 단계에서 토큰 기능 차원을 늘리면서 토큰 시퀀스 길이를 점진적으로 줄입니다.
This gives the tokens the ability to represent increasingly complex visual patterns over increasingly larger spatial footprints, similar to feature layers of CNNs.
footprint 차지하는 공간
이를 통해 토큰은 CNN의 특징 계층과 유사하게 점점 더 큰 공간 풋프린트에 대해 점점 더 복잡한 시각적 패턴을 나타낼 수 있다.
3.2 Convolutional Projection for Attention
The goal of the proposed Convolutional Projection layer is to achieve additional modeling of local spatial context, and to provide efficiency benefits by permitting the undersampling of K and V matrices.
permit 허용하다
제안된 컨볼루션 프로젝션 레이어의 목표는 로컬 공간 컨텍스트의 추가 모델링을 달성하고 K 및 V 행렬의 언더샘플링을 허용하여 효율성 이점을 제공하는 것입니다.
Fundamentally, the proposed Transformer block with Convolutional Projection is a generalization of the original Transformer block.
Fundamentally 근본적으로, 기본적으로
기본적으로, 제안된 컨볼루션 투영 트랜스포머 블록은 원래 트랜스포머 블록의 일반화이다.
While previus works try to add additional convolution modules to the Transformer Block for speech recognition and natural language processing, they result in a more complicated design and additional computational cost.
이전 연구[13, 39]에서는 음성 인식 및 자연어 처리를 위해 Transformer Block에 추가 컨볼루션 모듈을 추가하려고 시도했지만 설계가 더 복잡하고 계산 비용이 추가되었습니다.
Instead, we propose to replace the original position-wise linear projection for Multi-Head Self-Attention(MHSA) with depth-wise separable convolutions, forming the Convolutional Projection layer.
대신, 우리는 MHSA(Multi-Head Self-Attention)에 대한 원래 위치별 선형 투영을 깊이별 분리 가능한 회선으로 교체하여 회선 투영 레이어를 형성할 것을 제안합니다.
