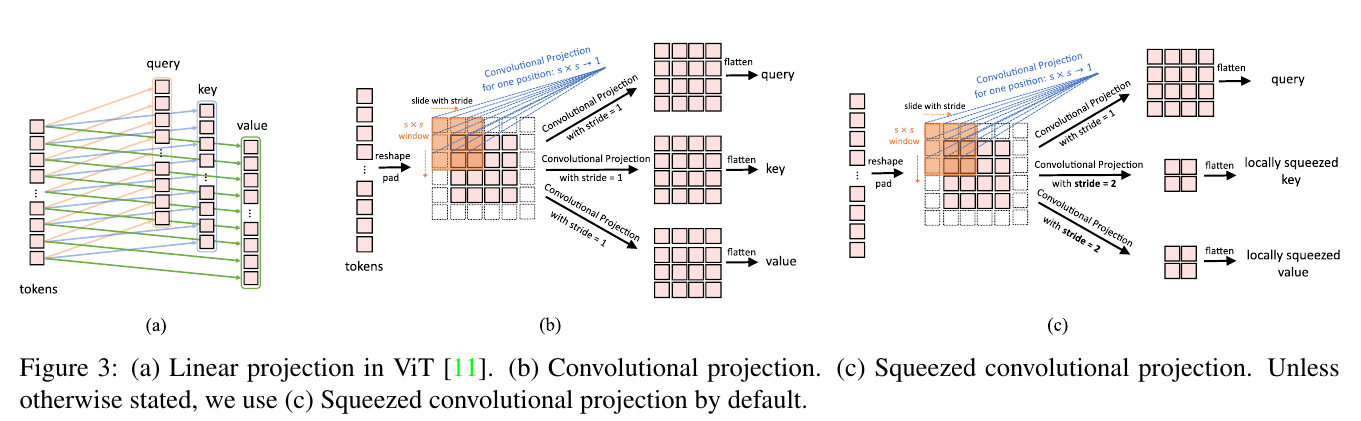
a) Linear projection in ViT [11]. (b) Convolutional projection. (c) Squeezed convolutional projection. Unless otherwise stated, we use (c) Squeezed convolutional projection by default.
squueezed 압축된Unless otherwise stated 달리 명시되지 않는 한
3.2.1 Implementation Details
Figure 3 (a) shows the original position-wise linear projection used in ViT [11] and Figure 3 (b) shows our proposed s × s Convolutional Projection.
그림 3(a)는 ViT[11]에서 사용된 원래 위치별 선형 투영을 보여주고 그림 3(b)는 제안된 s × s 컨볼루션 투영을 보여줍니다.
As shown in Figure 3 (b), tokens are first reshaped into a 2D token map.
그림 3(b)와 같이 토큰은 먼저 2D 토큰 맵으로 재구성됩니다.
Next, a Convolutional Projection is implemented using a depth-wise separable convolution layer with kernel size s.
다음으로, 커널 크기가 s인 깊이별 분리 가능한 컨볼루션 레이어를 사용하여 컨볼루션 투영을 구현합니다.
Finally, the projected tokens are flattened into 1D for subsequent process. This can be formulated as:
subsequent 후속
마지막으로, 투사된 토큰은 후속 프로세스를 위해 1D로 평면화됩니다. 이것은 다음과 같이 공식화될 수 있습니다.
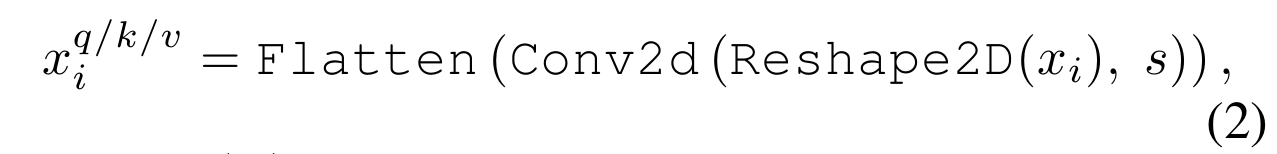
where is the token input for matrices at layer i, is the unperturbed token prior to the Convolutional Projection, Conv2d is a depth-wise separable convolution [5] implemented by: Depth-wise Conv2d → BatchNorm2d → Point-wise Conv2d, and s refers to the convolution kernel size.
unperturbed 방해받진않는, 교란되지 않는
여기서 'xq/k/vi'는 계층 i에서 Q/K/V 행렬에 대한 토큰 입력이고, xi는 컨볼루션 투영 이전의 방해받지 않은 토큰이며, Conv2d는 깊이별 분리 가능한 컨볼루션[5]으로 구현되며, Depth-wise Conv2d → BatchNorm2d → Point-wise Conv2d에 의해 구현된 커널 크기를 가리킨다.
The resulting new Transformer Block with the Convolutional Projection layer is a generalization of the original Transformer Block design.
Convolutional Projection 레이어가 있는 새로운 Transformer Block은 원래 Transformer Block 디자인을 일반화한 것입니다.
The original position-wise linear projection layer could be trivially implemented using a convolution layer with kernel size of 1 × 1.
trivially 사소한, 하찮은 ,평범한
원래의 위치별 선형 투영 레이어는 커널 크기가 1 × 1인 컨볼루션 레이어를 사용하여 사소한 방식으로 구현될 수 있다.
3.2.2 Efficiency Considerations
There are two primary efficiency benefits from the design of our Convolutional Projection layer.
First, We utilize efficient convolutions.
Directly using standard convolutions for the Convolutional Projection would require parameters and FLOPs, where C is the token channel dimension, and T is the number of tokens for processing.
컨볼루션 투영에 표준 sxs 컨볼루션을 직접 사용하려면 '2C2' 매개변수와 'O(s 2 C 2 T )' FLOP가 필요합니다. 여기서 C는 토큰 채널 차원이고 T는 처리를 위한 토큰 수입니다.
Instead, we split the standard s × s convolution into a depth-wise separable convolution [16].
대신 표준 s × s 컨볼루션을 깊이별 분리 가능한 컨볼루션으로 분할합니다[16].
In this way, each of the proposed Convolutional Projection would only introduce an extra of parameters and FLOPs compared to the original positionwise linear projection, which are negligible with respect to the total parameters and FLOPs of the models.
negligible 무시할 수 있는 with respect to ~에 관하여
이러한 방식으로 제안된 각 컨볼루션 프로젝션은 원래 위치별 선형 프로젝션과 비교하여 ' 파라미터 및 FLOP를 추가로 도입할 뿐이며, 이는 모델의 전체 파라미터 및 FLOP와 관련하여 무시할 수 있습니다.
Second, we leverage the proposed Convolutional Projection to reduce the computation cost for the MHSA operation.
leverage 활용하다
둘째, 제안된 Convolutional Projection을 활용하여 MHSA 연산에 대한 계산 비용을 줄입니다.
The s × s Convolutional Projection permits reducing the number of tokens by using a stride larger than 1.
s × s Convolutional Projection은 1보다 큰 보폭을 사용하여 토큰 수를 줄이는 것을 허용합니다.
Figure 3 (c) shows the Convolutional Projection, where the key and value projection are subsampled by using a convolution with stride larger than 1.
그림 3(c)는 1보다 큰 stride를 갖는 컨볼루션을 사용하여 키 및 값 프로젝션을 서브샘플링하는 컨볼루션 프로젝션을 보여줍니다.
We use a stride of 2 for key and value projection, leaving the stride of 1 for query unchanged.
키 및 값 프로젝션에 2의 스트라이드를 사용하고 쿼리에 1의 스트라이드를 변경하지 않고 그대로 둡니다.
In this way, the number of tokens for key and value is reduced 4 times, and the computational cost is reduced by 4 times for the later MHSA operation.
이러한 방식으로 키와 값에 대한 토큰의 수는 4배 감소하고, 나중 MHSA 작업을 위해 계산 비용은 4배 감소합니다.
This comes with a minimal performance penalty, as neighboring pixels/patches in images tend to have redundancy in appearance/semantics.
redundancy 중복 appearance 모양 semantics
이미지의 인접 픽셀/패치는 모양/의미에서 중복성을 갖는 경향이 있기 때문에 성능 저하가 최소화됩니다.
In addition, the local context modeling of the proposed Convolutional Projection compensates for the loss of information incurred by resolution reduction.
compensates 보상하다 incurred 발생하다
또한 제안된 Convolutional Projection의 로컬 컨텍스트 모델링은 해상도 감소로 인한 정보 손실을 보상합니다.
3.3 Methodological Discussions
방법론적 토론
Removin Positional Embeddings:
The introduction of Convolutional Projections for every Transformer block, combined with the Convolutional Token Embedding, gives us the ability to model local spatial relationships through the network.
Convolutional Token Embedding과 결합된 모든 Transformer 블록에 대한 Convolutional Projections의 도입은 네트워크를 통해 로컬 공간 관계를 모델링할 수 있는 기능을 제공합니다.
This built-in property allows dropping the position embedding from the network without hurting performance, as evidenced by our experiments (Section 4.4), simplifying design for vision tasks with variable input resolution.
이 내장 속성은 우리의 실험(섹션 4.4)에서 입증되었듯이 성능을 해치지 않고 네트워크에서 위치 임베딩을 드롭할 수 있어 가변 입력 해상도로 비전 작업에 대한 설계를 단순화한다.
Relations to Concurrent Work
동시작업과의 관계
Recently, two more related concurrent works also propose to improve ViT by incorporating elements of CNNs to Transformers.
최근, 두 가지 더 관련된 동시 연구는 CNN의 요소를 트랜스포머에 통합하여 ViT를 개선할 것을 제안한다.
Tokensto-Token ViT [41] implements a progressive tokenization, and then uses a Transformer-based backbone in which the length of tokens is fixed.
토큰 투 토큰 ViT[41]는 점진적인 토큰화를 구현한 다음 토큰 길이가 고정된 트랜스포머 기반 백본을 사용한다.
By contrast, our CvT implements a progressive tokensiztion by multi-stage process-containing both convolutional token embeddings and convolutional Transformer blocks in each stage.
대조적으로, CvT는 각 단계에서 컨볼루션 토큰 임베딩과 컨볼루션 변압기 블록을 모두 포함하는 다단계 프로세스에 의한 점진적 토큰화를 구현합니다.
As the length of tokens are decreased in each stage, the width of the tokens (dimension of feature) can be increased, allowing increased richness of representations at each feature spatial resolution.
각 단계에서 토큰의 길이가 감소함에 따라 토큰의 너비(특징의 차원)가 증가할 수 있으므로 각 특징 공간 해상도에서 표현의 풍부함을 높일 수 있습니다.
Additionally, whereas T2T concatenates neighboring tokens into one new token, leading to increasing the complexity of memory and computation, our usage of convolutional token embedding directly performs contextual learning without concatenation, while providing the flexibility of controlling stride and feature dimension.
whereas 두가지를 비교할때 씀 Additionally 게다가, 또한, 추가로
또한 T2T는 인접 토큰을 하나의 새로운 토큰으로 연결하여 메모리와 계산의 복잡성을 증가시키는 반면, 컨볼루션 토큰 임베딩을 사용하면 연결 없이 컨텍스트 학습을 직접 수행하면서 보폭과 기능 차원을 제어할 수 있는 유연성을 제공합니다.
To manage the complexity, T2T has to consider a deep-narrow architecture design with smaller hidden dimensions and MLP size than ViT in the subsequent backbone.
복잡성을 관리하기 위해 T2T는 후속 백본에서 ViT보다 작은 숨겨진 크기와 MLP 크기를 가진 매우 좁은 아키텍처 설계를 고려해야합니다.
Instead, we changed previous Transformer modules by replacing the position-wise linear projection with our convolutional projection.
대신 위치별 선형 투영을 컨볼루션 투영으로 교체하여 이전 Transformer 모듈을 변경했습니다.
Pyramid Vision Transformer (PVT) [34] overcomes the difficulties of porting ViT to various dense prediction tasks.
overcome 극복하다 porting 이식
Pyramid Vision Transformer(PVT)[34]는 ViT를 다양한 밀집 예측 작업으로 이식하는 어려움을 극복합니다.
In ViT, the output feature map has only a single scale with low resolution.
ViT에서 출력 기능 맵에는 저해상도의 단일 스케일만 있습니다.
In addition, computations and memory cost are relativey high, even for common inut image sizes.
또한 일반적인 입력 이미지 크기에 대해서도 계산 및 메모리 비용이 상대적으로 높습니다.
To address this problem, both PVT and our CvT incorporate pyramid structures from CNNs to the Transformers structure.
이 문제를 해결하기 위해 PVT와 CvT 모두 CNN에서 Transformers 구조까지 피라미드 구조를 통합합니다.
Compared with PVT, which only spatially subsamples the feature map or key/value matrices in projection, our CvT instead employs convolutions with stride to achieve this goal.
투영에서 형상 지도 또는 키/값 행렬을 공간적으로만 하위 샘플링하는 PVT와 비교하여, 우리의 CvT는 이 목표를 달성하기 위해 대신 보폭을 가진 컨볼루션을 사용한다.
Our experiments (shown in Section 4.4) demonstrate that the fusion of local neighboring information plays an important role on the performance.
우리의 실험(섹션 4.4 참조)은 로컬 인접 정보의 융합이 성능에 중요한 역할을 한다는 것을 보여줍니다.
