4. Experiments
In this section, we evaluate the CvT model on large-scale image classification datasets and transfer to various downstream datasets.
이 섹션에서는 대규모 이미지 분류 데이터 세트에서 CvT 모델을 평가하고 다양한 다운스트림 데이터 세트로 전송합니다.
In addition, we perform through ablation studies to validate the design of the proposed architecture.
또한 제안된 아키텍처의 설계를 검증하기 위해 ablation 연구를 수행합니다.
4.1. Setup
For evaluation, we use the ImageNet dataset, with 1.3M images and 1k classes, as well as its superset ImageNet-22k with 22k classes and 14M images [9].
평가를 위해 130만 개의 이미지와 1k 개의 클래스가 있는 ImageNet 데이터 세트와 22k 개의 클래스와 14M 개의 이미지를 가진 슈퍼셋 ImageNet-22k를 사용한다[9].
We further transfer the models pretrained on ImageNet-22k to downstream tasks, including CIFAR-10/100 [19], Oxford-IIIT-Pet [23], Oxford-IIIT-Flower [22], following [18, 11].
transfer 전송하다
ImageNet-22k에서 사전 훈련된 모델을 [18, 11]에 이어 CIFAR-10/100 [19], Oxford-IIIT-Pet [23], Oxford-IIIT-Flower [22]를 포함한 다운스트림 작업으로 추가로 전송합니다.
Model Variants.
We instantiate models with different parameters and FLOPs by varying the number of Transformer blocks of each stage and the hidden feature dimension used, as shown in Table 2.
표 2와 같이 각 단계의 Transformer 블록 수와 사용된 숨겨진 기능 차원을 변경하여 다양한 매개변수와 FLOP으로 모델을 인스턴스화합니다.
Three stages are adapted.
We define CvT-13 and CvT-21 as basic models, with 19.98M and 31.54M paramters.
CvT-13 및 CvT-21을 기본 모델로 정의하며 19.98M 및 31.54M 매개변수를 사용합니다.
CvT-X stands for Convolutional vision Transformer with X Transformer Blocks in total.
stand for 나타내다 의미하다
CvT-X는 총 X개의 변압기 블록이 있는 Convolutional Vision Transformer의 약자입니다.
Additionally, we experiment with a wider model with a larger token dimension for each stage, namely CvT-W24 (W stands for Wide), resulting 298.3M parameters, to validate the scaling ability of the proposed architecture.
또한 각 단계에 대해 더 큰 토큰 차원을 가진 더 넓은 모델, 즉 CvT-W24(W는 Wide를 나타냄)를 실험하여 제안된 아키텍처의 확장 능력을 검증하기 위해 298.3M 매개변수를 생성합니다.
Training
AdamW [21] optimizer is used with the weight decay of 0.05 for our CvT-13, and 0.1 for our CvT-21 and CvT-W24.
AdamW [21] 옵티마이저는 CvT-13의 경우 0.05, CvT-21 및 CvT-W24의 경우 0.1의 가중치 감쇠로 사용됩니다.
We train our models with an initial learning rate of 0.02 and a total batch size of 2048 for 300 epochs, with a cosine learning rate decay scheduler.
코사인 학습률 감쇠 스케줄러를 사용하여 초기 학습률이 0.02이고 총 배치 크기가 300에포크에 대해 2048인 모델을 학습합니다.
We adopt the same data augmentation and regularization methods as in ViT [30].
ViT[30]에서와 동일한 데이터 증대 및 정규화 방법을 채택합니다.
Unless otherwise stated, all ImageNet models are trained with an 224 × 224 input size.
달리 명시되지 않는 한 모든 ImageNet 모델은 224 × 224 입력 크기로 훈련됩니다.
Fine-tuning
We adopt fine-tuning strategy from ViT [30].
SGD optimizor with a momentum of 0.9 is used for finetuning.
As in ViT [30], we pre-train our models at resolution 224 × 224, and fine-tune at resolution of 384 × 384.
ViT[30]에서와 같이 해상도 224 × 224에서 모델을 사전 훈련하고 384 × 384 해상도에서 미세 조정합니다.
We fine-tune each model with a total batch size of 512, for 20,000 steps on ImageNet-1k, 10,000 steps on CIFAR-10 and CIFAR-100, and 500 steps on Oxford-IIIT Pets and Oxford-IIIT Flowers-102.
ImageNet-1k에서 20,000단계, CIFAR-10 및 CIFAR-100에서 10,000단계, Oxford-IIIT Pets 및 Oxford-IIIT Flowers-102에서 500단계에 대해 총 배치 크기 512로 각 모델을 미세 조정합니다.
4.2. Comparison to state of the art
Compared to Transformer based models, CvT achieves a much higher accuracy with fewer parameters and FLOPs.
Transformer 기반 모델과 비교하여 CvT는 더 적은 수의 매개변수와 FLOP로 훨씬 더 높은 정확도를 달성합니다.
CvT-21 obtains a 82.5% ImageNet Top-1 accuracy, which is 0.5% higher than DeiT-B with the reduction of 63% parameters and 60% FLOPs.
CvT-21은 82.5%의 ImageNet Top-1 정확도를 얻는데, 이는 63% 파라미터와 60%의 FLOP의 감소로 DeiT-B보다 0.5% 더 높습니다.
Our architecture designing can be further improved in terms of model parameters and FLOPs by neural architecture search (NAS) [7].
우리의 아키텍처 설계는 NAS(Neural Architecture Search)[7]에 의해 모델 매개변수 및 FLOP 측면에서 더욱 향상될 수 있습니다.
In particular, we search the proper stride for each convolution projection of key and value (stride = 1, 2) and the expansion ratio for each MLP layer (ratio M LP = 2, 4).
특히, 우리는 키와 값(stride = 1, 2)의 각 컨볼루션 투영에 대한 적절한 보폭과 각 MLP 계층에 대한 확장 비율(비율 M LP = 2, 4)을 검색합니다.
Such architecture candidates with FLOPs ranging from 2.59G to 4.03G and the num-ber of model parameters ranging from 13.66M to 19.88M construct the search space.
range from A to B ~가 A에서 B까지 분포하다/이르다
2.59G ~ 4.03G 범위의 FLOP 및 13.66M ~ 19.88M 범위의 모델 매개변수를 갖는 이러한 아키텍처 후보는 검색 공간을 구성합니다.
The NAS is evaluated directly on ImageNet-1k.
NAS는 ImageNet-1k에서 직접 평가됩니다.
The searched CvT-13-NAS, a bottlenecklike architecture with stride = 2, 'ratioMLP' = 2 at the first and last stages, and stride = 1, 'ratioMLP' = 4 at most layers of the middle stage, reaches to a 82.2% ImageNet Top-1 accuracy with fewer model parameters than CvT-13.
검색된 CvT-13-NAS는 보폭 = 2, 첫 번째 및 마지막 단계에서 'ratioMLP' = 2, 중간 단계의 대부분의 레이어에서 보폭 = 1, 'ratioMLP' = 4인 병목 현상 유사 아키텍처로, CvT-13보다 적은 모델 파라미터로 82.2%의 ImageNet Top-1 정확도에 도달합니다.
Compared to CNN-based models, CvT further closes the performance gap of Transformer-based-models.
close 좁히다
CNN 기반 모델과 비교하여 CvT는 Transformer 기반 모델의 성능 격차를 더욱 좁힙니다.
Our smallest model CvT-13 with 20M parameters and 4.5G FLOPs surpasses the large ResNet-152 model by 3.2% on ImageNet Top-1 accuracy, while ResNet-151 has 3 times the parameters of CvT-13.
surpasses 능가하다 뛰어나다
20M 매개 변수와 4.5G FLOP을 가진 가장 작은 모델인 CvT-13은 ImageNet Top-1 정확도에서 대형 ResNet-152 모델을 3.2% 능가하는 반면, ResNet-151은 CvT-13의 3배 매개 변수를 갖는다.
Furthermore, when more data are involved, our wide model CvT-W24 pretrained on ImageNet-22k reaches to 87.7% Top-1 Accuracy on ImageNet without extra data (e.g. JFT-300M), surpassing the previous best Transformer based models ViT-L/16 by 2.5% with similar number of model parameters and FLOPs.
further 게다가 또한
또한 더 많은 데이터가 관련되면 ImageNet-22k에서 사전 훈련 된 와이드 모델 CvT-W24 ``가 추가 데이터 (예 : JFT-300M)없이 ImageNet에서 87.7 %의 Top-1 정확도에 도달하여 유사한 수의 모델 매개 변수 및 FLOP로 이전 최고의 변압기 기반 모델 ViT-L / 16을 2.5 % 능가합니다.
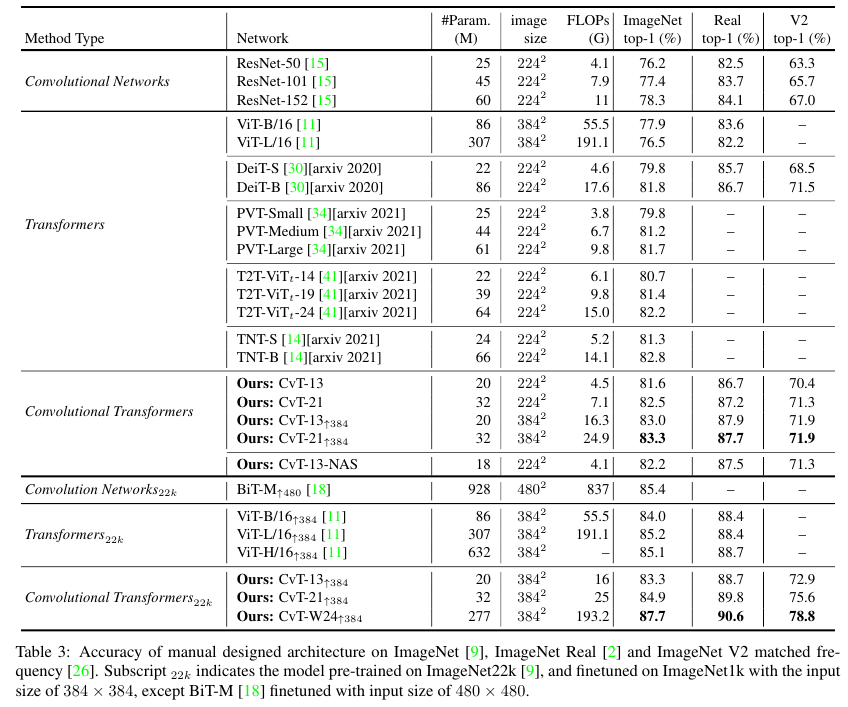
Accuracy of manual designed architecture on ImageNet [9], ImageNet Real [2] and ImageNet V2 matched frequency [26].
ImageNet [9], ImageNet Real [2] 및 ImageNet V2 일치 주파수 [26]에서 수동으로 설계된 아키텍처의 정확성.
Subscript 22k indicates the model pre-trained on ImageNet22k [9], and finetuned on ImageNet1k with the input size of 384 × 384, except BiT-M [18] finetuned with input size of 480 × 480.
Subscript 아래에 기입한indicate 나타내다
Subscript 22k는 ImageNet22k[9]에서 사전 교육되고 ImageNet1k에서 입력 크기가 384 × 384인 모델을 나타내며, BiT-M [18]은 입력 크기가 480 × 480인 것을 제외하고 미세 조정된다.
4.3 Downstream task transfer
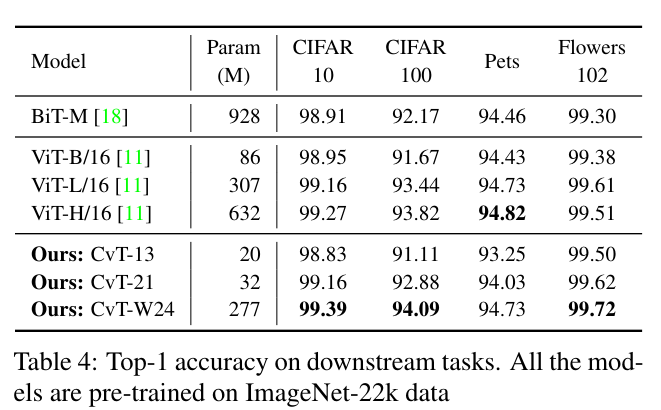
We further investigate the ability of our models to transfer by fine-tuning models on various tasks, with all models being pre-trained on ImageNet-22k.
우리는 또한 모든 모델이 ImageNet-22k에서 사전 교육을 받은 상태에서 다양한 작업에서 모델을 미세 조정하여 모델을 전송할 수 있는 능력을 조사한다.
Table 4 shows the results.
Our CvT-W24 model is able to obtain the best performance across all the downstream tasks considered, even when compared to the large BiT-R152x4 [18] model, which has more than 3× the number of parameters as CvT-W24.
across all 모두에 걸쳐
우리의 CvT-W24 모델은 CvT-W24보다 매개 변수 수가 3배 이상인 대형 BitT-R152x4[18] 모델과 비교하더라도 고려된 모든 다운스트림 작업에서 최고의 성능을 얻을 수 있다.
4.4 Ablation Study
We design various ablation experiments to investigate the effectiveness of the proposed components of our architecture.
우리는 아키텍처의 제안된 구성 요소의 효과를 조사하기 위해 다양한 절제 실험을 설계한다.
First, we show that with our introduction of convolutions, position embeddings can be removed from the model.
첫째, 컨볼루션을 도입하면 위치 임베딩을 모델에서 제거 할 수 있음을 보여줍니다.
Then, we study the impact of each of the proposed Convolutional Token Embedding and Convolutional Projection components.
그런 다음 제안된 각 컨볼루션 토큰 임베딩 및 컨볼루션 투영 구성 요소의 영향을 연구한다.
Removing Position Embedding
Given that we have introduced convolutions into the model, allowing local context to be captured, we study whether position embedding is still needed for CvT.
allow 가능하게 하다, 허용하다
우리는 컨볼루션을 모델에 도입하여 로컬 컨텍스트를 캡처할 수 있도록 했기 때문에 CvT에 위치 임베딩이 여전히 필요한지 연구한다.
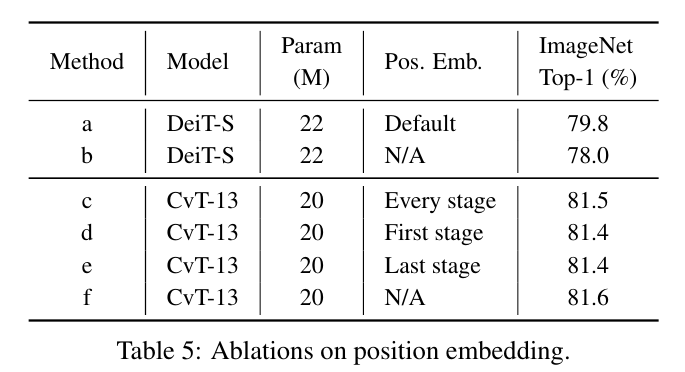
The results are shown in Table 5, and demonstrate that removing position embedding of our model does not degrade the performance.
결과는 표 5에 나와 있으며, 모델의 위치 임베딩을 제거해도 성능이 저하되지 않음을 보여준다.
Therefore, position embeddings have been removed from CvT by default.
따라서 위치 임베딩은 기본적으로 CvT에서 제거되었습니다.
As a comparison, removing the position embedding of DeiT-S would lead to 1.8% drop of ImageNet Top-1 accuracy, as it does not model image spatial relationships other than by adding the position embedding.
As a comparison, 비교로, 이에비해
이에 비해 DeiT-S의 위치 임베딩을 제거하면 위치 임베딩을 추가하는 것 외에는 이미지 공간 관계를 모델링하지 않기 때문에 ImageNet Top-1 정확도가 1.8% 하락한다.
This further shows the effectiveness of our introduced convolutions.
Position Embedding is often realized by fixed-length learn-able vectors, limiting the trained model adaptation of variable-length input.
realized 실현된
위치 임베딩은 종종 고정 길이 학습 가능 벡터에 의해 실현되어 가변 길이 입력의 훈련된 모델 적응을 제한합니다.
However, a wide range of vision applications take variable image resolutions.
Recent work CPVT [6] tries to replace explicit position embedding of Vision Transformers with a conditional position encodings module to model position information on-the-fly.
on-the-fly 즉석, 즉시
최근 연구 CPVT[6]는 위치 정보를 즉시 모델링하기 위해 비전 트랜스포머의 명시적 위치 임베딩을 조건부 위치 인코딩 모듈로 대체하려고 한다.
CvT is able to completely remove the positional embedding, providing the possibility of simplifying adaption to more vision tasks without requiring a re-designing of the embedding.
CvT는 위치 임베딩을 완전히 제거할 수 있으므로 임베딩을 다시 설계할 필요 없이 더 많은 비전 작업에 대한 적응을 단순화할 수 있습니다.
Convolutional Token Embedding
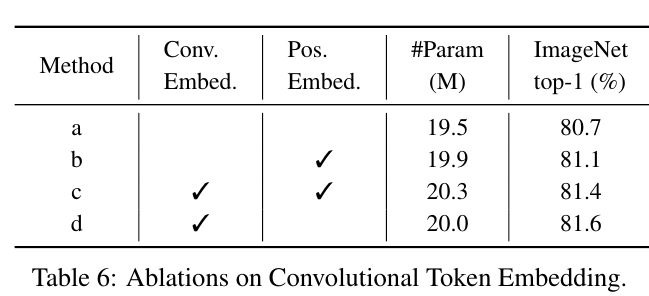
We study the effectiveness of the proposed Convolutional Token Embedding, and Table 6 shows the results.
제안한 Convolutional Token Embedding의 효과를 연구하고 그 결과를 Table 6과 같다.
Table 6d is the CvT-13 model.
When we replace the Convolutional Token Embedding with non-overlapping Patch Embedding [11], the performance drops 0.8% (Table 6a v.s. Table 6d).
Convolutional Token Embedding을 겹치지 않는 Patch Embedding[11]으로 교체하면 성능이 0.8% 떨어집니다(표 6a 대 표 6d).
When position embedding is used, the introduction of Convolutional Token Embedding still obtains 0.3% improvement (Table 6b v.s. Table 6c).
위치 임베딩을 사용할 때 Convolutional Token Embedding의 도입은 여전히 0.3% 개선을 얻습니다(표 6b 대 표 6c).
Further, when using both Convolutional Token Embedding and position embedding as Table 6d, it slightly drops 0.1% accuracy.
또한 표 6d와 같이 Convolutional Token Embedding과 Position Embedding을 모두 사용하면 0.1% 정확도가 약간 떨어집니다.
These results validate the introduction of Convolutional Token Embedding not only improves the performance, but also helps CvT model spatial relationships without position embedding.
이러한 결과는 Convolutional Token Embedding의 도입을 검증하여 성능을 향상시킬 뿐만 아니라 CvT가 위치 임베딩 없이 공간 관계를 모델링하는 데 도움이 됩니다.
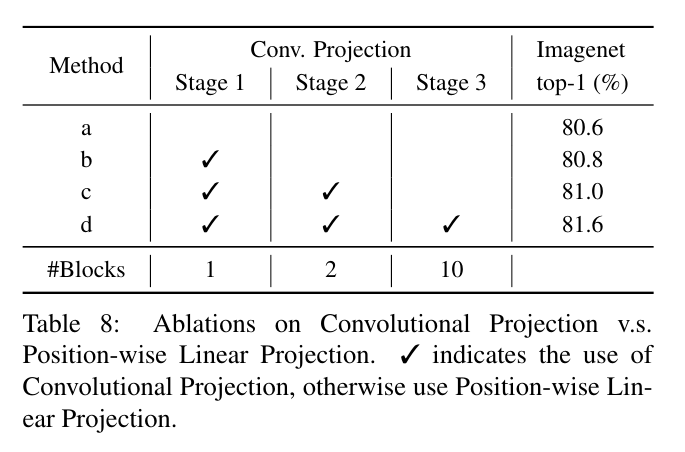
Convolutional Projection
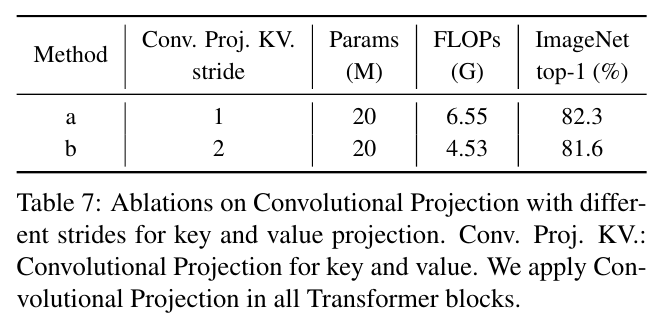
First, we compare the proposed Convolutional Projection with different strides in Table 7.
먼저 제안된 Convolutional Projection을 표 7에서 다른 보폭과 비교합니다.
By using a stride of 2 for key and value projection, we observe a 0.3% drop in ImageNet Top-1 accuracy, but with 30% fewer FLOPs.
키 및 값 프로젝션에 2의 보폭을 사용하면 ImageNet Top-1 정확도가 0.3% 감소하지만 FLOP은 30% 감소합니다.
We choose to use Convolutional Projection with stride 2 for key and value as default for less computational cost and memory usage.
계산 비용과 메모리 사용량을 줄이기 위해 키와 값에 대해 보폭 2를 사용하는 컨볼루션 투영을 기본값으로 사용하기로 선택했습니다.
Then, we study how the proposed Convolutional Projection affects the performance by choosing whether to use Convolutional Projection or the regular Position-wise Linear Projection for each stage.
그런 다음 각 단계에 대해 Convolutional Projection 또는 일반 Position-wise Linear Projection을 사용할지 선택하여 제안한 Convolutional Projection이 성능에 어떤 영향을 미치는지 연구합니다.
The results are shown in Table 8.
We observe that replacing the original Position-wise Linear Projection with the proposed Convolutional Projection improves the Top-1 Accuracy on ImageNet from 80.6% to 81.5%.
원래 위치별 선형 투영을 제안된 컨볼루션 투영으로 교체하면 ImageNet의 Top-1 정확도가 80.6%에서 81.5%로 향상됩니다.
In addition, performance continually improves as more stages use the design, validating this approach as an effective modeling strategy.
또한 더 많은 단계에서 설계를 사용함에 따라 성능이 지속적으로 향상되어 이 접근 방식을 효과적인 모델링 전략으로 검증합니다.