1 INTRODUCTION
Transformer models [1] have recently demonstrated exemplary performance on a broad range of language tasks e.g., text classification, machine translation [2] and question answering.
demonstrate 입증하다 examplary 모범적인
트랜스포머 모델[1]은 최근 텍스트 분류, 기계 번역[2] 및 질문 답변과 같은 광범위한 언어 작업에서 모범적인 성능을 보여주었다.
Among these models, the most popular ones include BERT (Bidirectional Encoder Representations from Transformers) [3], GPT (Generative Pre-trained Transformer) v1-3 [4]–[6], RoBERTa (Robustly Optimized BERT Pre-training) [7] and T5 (Text-to-Text Transfer Transformer) [8].
이러한 모델 중 가장 인기 있는 모델은 BERT(Bidirectional Encoder Representations from Transformers)[3], GPT(Generative Pre-trained Transformer) v1-3[4]–[6], RoBERTa(Robustly Optimized BERT Pre-training) [ 7] 및 T5(텍스트 대 텍스트 전송 변환기)[8].
The profound impact of Transformer models has become more clear with their scalability to very large capacity models [9], [10]. For example, the BERT-large [3] model with 340 million parameters was significantly outperformed by the GPT-3 [6] model with 175 billion parameters while the latest mixture-of-experts Switch transformer [10] scales up to a whopping 1.6 trillion parameters!
Transformer 모델의 매우 큰 용량 모델에 대한 확장성으로 인해 그 영향이 더욱 뚜렷해졌습니다[9], [10]. 예를 들어, 3억 4천만 개의 매개 변수를 가진 BERT-large [3] 모델은 1750억 개의 매개 변수를 가진 GPT-3 [6] 모델보다 훨씬 성능이 뛰어났으며, 최신 혼합 전문가 Switch Transformer [10]은 무려 1조 6천억 개의 매개 변수로 확장됩니다.
The breakthroughs from Transformer networks in Natural Language Processing (NLP) domain has sparked great interest in the computer vision community to adapt these models for vision and multi-modal learning tasks (Fig. 1).
breakthroughs 돌파구, 혁신
자연어 처리(NLP) 도메인에서 Transformer 네트워크의 혁신은 컴퓨터 비전 커뮤니티에서 이러한 모델을 비전 및 다중 모달 학습 작업에 적용하기 위해 큰 관심을 불러일으켰습니다(그림 1).
However, visual data follows a typical structure (e.g., spatial and temporal coherence), thus demanding novel network designs and training schemes.
coherence 일관성 schemes 쳬계
그러나 시각적 데이터는 일반적인 구조(예: 공간적 및 시간적 일관성)를 따르므로 새로운 네트워크 설계 및 교육 체계가 필요합니다.
As a result, Transformer models and their variants have been successfully used for image recognition [11], [12], object detection [13], [14], segmentation [15], image super-resolution [16], video understanding [17], [18], image generation [19], text-image synthesis [20] and visual question answering [21], [22], among several other use cases [23]–[26].
variant 변형
결과적으로 Transformer 모델과 그 변형은 이미지 인식[11,12], 물체 감지[13],[14], 분할[15], 이미지 초해상도[16], 비디오 이해[16], 17], [18], 이미지 생성[19], 텍스트-이미지 합성[20] 및 시각적 질문 응답[21], [22], 기타 여러 사용 사례[23]-[26].
This survey aims to cover such recent and exciting efforts in the computer vision domain, providing a comprehensive reference to interested readers.
이 설문 조사는 관심 있는 독자들에게 포괄적인 참고 자료를 제공하면서 컴퓨터 비전 영역에서 최근에 이루어진 흥미진진한 노력을 다루는 것을 목표로 합니다.
Transformer architectures are based on a self-attention mechanism that learns the relationships between elements of a sequence. As opposed to recurrent networks that process sequence elements recursively and can only attend to short-term context, Transformers can attend to complete sequences thereby learning long-range relationships.
as apposed to ~와 달리 thereby 그렇게 함으로써 recursively 회기적으로
트랜스포머 아키텍처는 시퀀스 요소 간의 관계를 학습하는 셀프 어텐션 메커니즘을 기반으로 합니다. 시퀀스 요소를 재귀적으로 처리하고 단기 컨텍스트에만 주의를 기울일 수 있는 순환 네트워크와 달리 Transformers는 전체 시퀀스에 주의를 기울여 장기적인 관계를 학습할 수 있습니다.
Although attention models have been extensively used in both feed-forward and recurrent networks [27], [28], Transformers are based solely on the attention mechanism and have a unique implementation (i.e., multi-head attention) optimized for parallelization.
어텐션 모델이 피드 포워드 및 순환 네트워크 모두에서 광범위하게 사용되었지만 Transformers는 어텐션 메커니즘에만 기반을 두고 병렬화에 최적화된 고유한 구현(즉, 멀티 헤드 어텐션)을 가지고 있습니다.
An important feature of these models is their scalability to high-complexity models and large-scale datasets e.g., in comparison to some of the other alternatives such as hard attention [29] which is stochastic in nature and requires Monte Carlo sampling for sampling attention locations.
scalability 확장성 stochastic 확률적인
이러한 모델의 중요한 특징은 본질적으로 확률적이고 주의 위치 샘플링을 위해 몬테카를로 샘플링이 필요한 하드 주의 [29]와 같은 다른 대안과 비교하여 복잡성이 높은 모델과 대규모 데이터 세트에 대한 확장성이다.
Since Transformers assume minimal prior knowledge about the structure of the problem as compared to their convolutional and recurrent counterparts [30]–[32], they are typically pre-trained using pretext tasks on largescale (unlabelled) datasets [1], [3].
트랜스포머는 컨볼루션 및 반복되는 대응물[30]–[32]과 비교하여 문제의 구조에 대한 최소한의 사전 지식을 가정하기 때문에, 일반적으로 대규모(레이블이 없는) 데이터 세트에 대한 핑계 작업을 사용하여 사전 훈련된다[1], [3].
Such a pre-training avoids costly manual annotations, thereby encoding highly expressive and generalizable representations that model rich relationships between the entities present in a given dataset. The learned representations are then fine-tuned on the downstream tasks in a supervised manner to obtain favorable results.
favorable 유리한, 호의적인 annotations 주석
이러한 사전 교육은 비용이 많이 드는 수동 주석을 방지하므로 주어진 데이터 세트에 있는 엔터티 간의 풍부한 관계를 모델링하는 매우 표현적이고 일반화 가능한 표현을 인코딩합니다. 그런 다음 학습된 표현은 감독 방식으로 다운스트림 작업에서 미세 조정되어 유리한 결과를 얻습니다.
This paper provides a holistic overview of the transformer models developed for computer vision applications.
holistic 전체적인
We develop a taxonomy of the network design space and highlight the major strengths and shortcomings of the existing methods. Other literature reviews mainly focus on the NLP domain [33], [34] or cover generic attention-based approaches [27], [33]. By focusing on the newly emerging area of visual transformers, we comprehensively organize the recent approaches according to the intrinsic features of self-attention and the investigated task.
taxonomy 분류 genetic 일반적인 intrinsic 본질적인 investigated 조사된
우리는 네트워크 설계 공간의 분류법을 개발하고 기존 방법의 주요 강점과 단점을 강조한다. 다른 문헌 검토는 주로 NLP 영역 [33], [34] 또는 일반 주의 기반 접근법[27]에 초점을 맞추고 있다. 새롭게 부상하는 시각적 변환기 영역에 초점을 맞춤으로써, 우리는 자기 주의의 본질적인 특징과 조사된 작업에 따라 최근의 접근 방식을 포괄적으로 구성한다.
We first provide an introduction to the salient concepts underlying Transformer networks and then elaborate on the specifics of recent vision transformers.
salient 주요한 underlying 근본적인 elaborate 정교한 specifics 주요
먼저 트랜스포머 네트워크의 주요 개념에 대한 소개를 제공한 다음 최근 비전 트랜스포머의 세부 사항에 대해 자세히 설명한다.
Where ever possible, we draw parallels between the Transformers used in the NLP domain [1] and the ones developed for vision problems to flash major novelties and interesting domain-specific insights.
가능하면 우리는 NLP 도메인[1]에서 사용되는 트랜스포머와 시력 문제를 위해 개발된 트랜스포머 사이에 유사점을 그려 주요 참신함과 흥미로운 도메인별 통찰력을 보여줍니다.
Recent approaches show that convolution operations can be fully replaced with attention-based transformer modules and have also been used jointly in a single design to encourage symbiosis between the two complementary set of operations. This survey finally details open research questions with an outlook towards the possible future work.
complementary 상호보안적인 symbiosis 공동
최근의 접근 방식은 컨볼루션 작업을 주의 기반 변압기 모듈로 완전히 대체할 수 있으며, 두 개의 상호 보완적인 작업 세트 사이의 공생을 장려하기 위해 단일 설계에서 공동으로 사용되었음을 보여준다. 이 설문조사는 마지막으로 가능한 미래 작업에 대한 전망과 함께 공개된 연구 질문을 자세히 설명합니다.
2 FOUNDATIONS
There exist two key ideas that have contributed towards the development of conventional transformer models. (a) The first one is self-attention, which allows capturing ‘longterm’ dependencies between sequence elements as compared to conventional recurrent models that find it challenging to encode such relationships.
기존 변압기 모델의 개발에 기여한 두 가지 핵심 아이디어가 있습니다. (a) 첫 번째는 self-attention으로, 이러한 관계를 인코딩하는 데 어려움이 있는 기존의 반복 모델과 비교하여 시퀀스 요소 간의 '장기적' 종속성을 캡처할 수 있습니다.
(b) The second key idea is that of pre-training 1 on a large (un)labelled corpus in a (self)supervised manner, and subsequently fine-tuning to the target task with a small labeled dataset [3], [7], [38].
(b) 두 번째 핵심 아이디어는 (자체)감독 방식으로 큰 (비)레이블 말뭉치에 대해 1을 사전 훈련한 다음 작은 레이블 데이터 세트로 대상 작업을 미세 조정하는 것입니다 [3], [7 ], [38].
Below, we provide a brief tutorial on these two ideas (Sec. 2.2 and 2.1), along with a summary of seminal Transformer networks (Sec. 2.3 and 2.4) where these ideas have been applied. This background will help us better understand the forthcoming Transformer based models used in the computer vision domain (Sec. 3).
forthcoiming 다가 오는
아래에서는 이러한 아이디어가 적용된 주요 트랜스포머 네트워크(2.3 및 2.4) 요약과 함께 이 두 가지 아이디어(2.2 및 2.1)에 대한 간단한 튜토리얼을 제공한다. 이러한 배경은 컴퓨터 비전 영역에서 사용되는 다가오는 트랜스포머 기반 모델을 더 잘 이해하는 데 도움이 될 것입니다(3장).
2.1 Self-Attention in Transformers
Given a sequence of items, self-attention estimates the relevance of one item to other items (e.g., which words are likely to come together in a sentence). The self-attention mechanism is an integral component of Transformers, which explicitly models the interactions between all entities of a sequence for structured prediction tasks.
integral 필수적인 explicitly 명시적인
일련의 항목을 고려할 때, 자기 주의는 한 항목과 다른 항목의 관련성을 추정한다(예: 문장에서 어떤 단어가 함께 나올 가능성이 있는가). 자기 주의 메커니즘은 구조화된 예측 작업에 대한 시퀀스의 모든 엔티티 간의 상호 작용을 명시적으로 모델링하는 트랜스포머의 필수 구성 요소이다.
Basically, a selfattention layer updates each component of a sequence by aggregating global information from the complete input sequence. Lets denote a sequence of n entities (x 1 , x 2 , · · · x n ) by X ∈ R n×d , where d is the embedding dimension to represent each entity. The goal of self-attention is to capture the interaction amongst all n entities by encoding each entity in terms of the global contextual information.
기본적으로, 자기 주의 계층은 완전한 입력 시퀀스로부터 글로벌 정보를 집계함으로써 시퀀스의 각 구성 요소를 업데이트한다. n개의 엔티티(x 1, x 2, · · · · x n )의 시퀀스를 X ∈ R n×d로 나타내자. 여기서 d는 각 엔티티를 나타내는 임베딩 차원이다. 자기 주의의 목표는 글로벌 상황 정보의 관점에서 각 엔티티를 인코딩하여 모든 n개 엔티티 간의 상호 작용을 포착하는 것이다.
This is done by defining three learnable weight matrices to transform Queries (W Q ∈ R d×d q ), Keys (W K ∈ R d×d k ) and Values (W V ∈ R d×d v ), where d q = d k . The input sequence X is first projected onto these weight matrices to get Q = XW Q , K = XW K and V = XW V . The output Z ∈ R n×d v of the self attention layer is,
이는 쿼리(WQ ∈ R d×d q ), 키(W K ∈ R d×d k ) 및 값(W V ∈ R d×d v )을 변환하기 위해 3개의 학습 가능한 가중치 행렬을 정의하여 수행됩니다. 여기서 d q = d k 입니다. 입력 시퀀스 X는 먼저 이러한 가중치 행렬에 투영되어 Q = XW Q , K = XW K 및 V = XW V 를 얻습니다. Self Attention Layer의 출력 Z ∈ R n×d v는 다음과 같습니다.


Fig. 2: An example self-attention block used in the vision domain [39]. Given the input sequence of image features, the triplet of (key, query, value) is calculated followed by attention calculation and applying it to reweight the values. A single head is shown here and an output projection (W) is finally applied to obtain output features with the same dimension as the input. Figure adapted from [39].
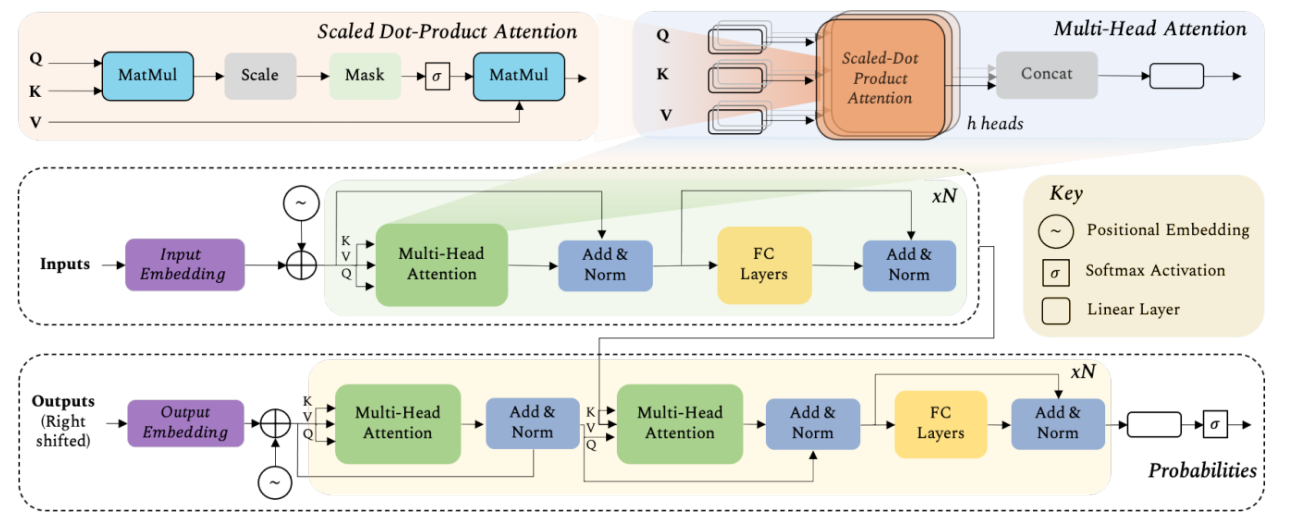
Fig. 3: Architecture of the Transformer Model [1]. The model was first developed for the language translation task where an input sequence in one language is required to be converted to the output sequence in another language. The Transformer encoder (middle row) operates on the input language sequence and converts it to an embedding before passing it on to the encoder blocks.
그림 3: 트랜스포머 모델의 아키텍처 [1]. 이 모델은 한 언어의 입력 시퀀스를 다른 언어의 출력 시퀀스로 변환해야 하는 언어 번역 작업을 위해 처음 개발되었습니다. Transformer 인코더(중간 행)는 입력 언어 시퀀스에서 작동하고 인코더 블록에 전달하기 전에 임베딩으로 변환합니다.
The Transformer decoder (bottom row) operates on the previously generated outputs in the translated language and the encoded input sequence from the middle branch to output the next word in the output sequence.
트랜스포머 디코더(하단 행)는 번역된 언어로 이전에 생성된 출력과 중간 분기에서 인코딩된 입력 시퀀스에 대해 작동하여 출력 시퀀스에서 다음 단어를 출력합니다.
The sequence of previous outputs (used as input to the decoder) is obtained by shifting the output sentence to the right by one position and appending start-of-sentence token at the beginning.
이전 출력 시퀀스(디코더에 대한 입력으로 사용됨)는 출력 문장을 오른쪽으로 한 위치 이동하고 처음에 문장 시작 토큰을 추가하여 얻습니다.
This shifting avoids the model to learn to simply copy the decoder input to the output. The ground-truth to train the model is simply the output language sequence (without any right shift) appended with an end-of-sentence token.
The blocks consisting of multi-head attention (top row) and feed-forward layers are repeated N times in both the encoder and decoder.
이 이동은 모델이 단순히 디코더 입력을 출력에 복사하는 방법을 배우는 것을 방지합니다. 모델을 교육하기 위한 실측은 단순히 문장 끝 토큰이 추가된 출력 언어 시퀀스(오른쪽 시프트 없음)입니다.
멀티 헤드 어텐션(상단 행)과 피드포워드 레이어로 구성된 블록은 인코더와 디코더 모두에서 N번 반복됩니다.
