Transformers in Vision: A Survey
1.Transformers in Vision: A Survey 제1부

Astounding results from Transformer models on natural language tasks have intrigued the vision community to study their application to computer vision
2022년 12월 13일
2.Transformers in Vision: A Survey 제2부

Transformer models 1 have recently demonstrated exemplary performance on a broad range of language tasks e.g., text classification, machine translatio
2022년 12월 13일
3.Transformers in Vision: A Survey 제2부-2
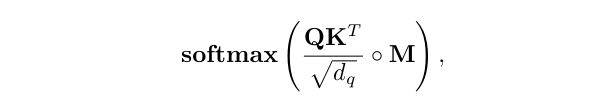
For a given entity in the sequence, the self-attention basically computes the dot-product of the query with all keys, which is then normalized using s
2022년 12월 13일
4.Transformers in Vision: A Survey 제3부
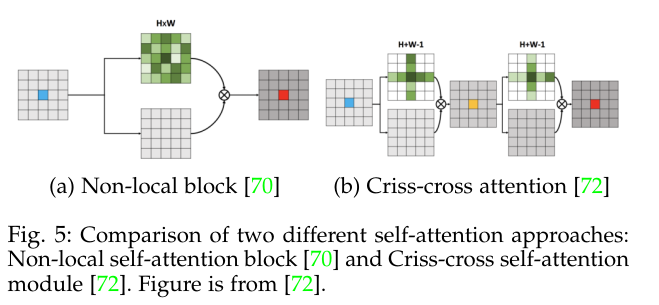
Inspired by non-local means operation 69 which was mainly designed for image denoising, Wang et al. 70 proposed a differentiable non-local operation f
2022년 12월 15일