For a given entity in the sequence, the self-attention basically computes the dot-product of the query with all keys, which is then normalized using softmax operator to get the attention scores. Each entity then becomes the weighted sum of all entities in the sequence, where weights are given by the attention scores (Fig. 2 and Fig. 3, top row-left block).
시퀀스에서 주어진 엔티티에 대해 자체 주의는 기본적으로 모든 키로 쿼리의 도트 곱을 계산한 다음 소프트맥스 연산자를 사용하여 정규화하여 주의 점수를 얻는다. 그러면 각 엔티티는 주의 점수에 의해 가중치가 주어지는 시퀀스의 모든 엔티티의 가중 합계가 된다(그림 2 및 그림 3, 상단 행 왼쪽 블록).
Masked Self-Attention
For a given entity in the sequence, the self-attention basically computes the dot-product of the query with all keys, which is then normalized using softmax operator to get the attention scores. Each entity then becomes the weighted sum of all entities in the sequence, where weights are given by the attention scores (Fig. 2 and Fig. 3, top row-left block).
시퀀스의 주어진 엔터티에 대해 self-attention은 기본적으로 모든 키를 사용하여 쿼리의 내적을 계산한 다음 softmax 연산자를 사용하여 정규화하여 어텐션 점수를 얻습니다. 그런 다음 각 엔터티는 시퀀스에 있는 모든 엔터티의 가중 합계가 되며, 여기서 가중치는 어텐션 점수로 지정됩니다(그림 2 및 그림 3, 왼쪽 상단 블록).
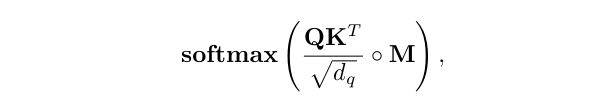
where ◦ denotes Hadamard product. Basically, while predicting an entity in the sequence, the attention scores of the future entities are set to zero in masked self-attention.
여기서 ◦는 Hadamard 제품을 나타냅니다. 기본적으로 시퀀스에서 엔터티를 예측하는 동안 마스크된 셀프 어텐션에서 미래 엔터티의 어텐션 점수는 0으로 설정된다.
Multi-Head Attention

encapsulate 압축하다, 요약하다
The main difference of self-attention with convolution operation is that the filters are dynamically calculated instead of static filters (that stay the same for any input) as in the case of convolution. Further, self-attention is invariant to permutations and changes in the number of input points.
permutation 순열
컨볼루션 연산과 자기 주의의 주요한 차이점은 컨볼루션의 경우처럼 (어떤 입력에도 동일하게 유지되는) 정적 필터 대신 필터가 동적으로 계산된다는 것이다. 또한, 자기 주의는 순열과 입력 지점 수의 변화에 변함이 없다.
As a result, it can easily operate on irregular inputs as opposed to standard convolution that requires grid structure.
Furthermore, it has been shown in the literature how selfattention (with positional encodings) is theoretically a more flexible operation which can model the behaviour of convolutional models towards encoding local features [40].
literature 문헌 ireegular 불규칙적인
결과적으로 그리드 구조가 필요한 표준 컨벌루션과 달리 불규칙한 입력에도 쉽게 작동할 수 있습니다.
게다가, selfattention(위치 인코딩 포함)이 이론적으로 로컬 기능을 인코딩하는 방향으로 컨볼루션 모델의 동작을 모델링할 수 있는 더 유연한 작업이라는 것이 문헌에서 나타났습니다[40].
Cordonnier et al. [41] further studied the relationships between self-attention and convolution operations. Their empirical results confirm that multi-head self-attention (with sufficient parameters) is a more generic operation which can model the expressiveness of convolution as a special case. In fact, self-attention provides the capability to learn the global as well as local features, and provide expressivity to adaptively learn kernel weights as well as the receptive field (similar to deformable convolutions [42]).
Cordonnier et al. [41]은 self-attention과 convolution 연산 사이의 관계를 더 연구했습니다. 이들의 경험적 결과는 multi-head self-attention(충분한 매개변수 포함)이 컨볼루션의 표현력을 특수한 경우로 모델링할 수 있는 보다 일반적인 작업임을 확인합니다. 실제로 self-attention은 전역 및 로컬 기능을 학습할 수 있는 기능을 제공하고 수용 필드뿐만 아니라 커널 가중치를 적응적으로 학습할 수 있는 표현성을 제공합니다(변형 가능한 컨볼루션 [42]와 유사).
2.2 (Self) Supervised Pre-training
Self-attention based Transformer models generally operate in a two-stage training mechanism. First, pre-training is performed on a large-scale dataset (and sometimes a combination of several available datasets [22], [43]) in either a supervised [11] or a self-supervised manner [3], [44], [45].
자기 주의 기반 트랜스포머 모델은 일반적으로 2단계 훈련 메커니즘으로 작동한다. 첫째, 사전 훈련은 대규모 데이터 세트(때로는 사용 가능한 여러 데이터 세트의 조합)에 대해 감독된 방식[11] 또는 자체 감독 방식[3], [44], [45] 중 하나로 수행된다.
Later, the pre-trained weights are adapted to the downstream tasks using small-mid scale datasets. Examples of downstream tasks include image classification [46], object detection [13], zero-shot classification [20], questionanswering [10] and action recognition [18]. The effectiveness of pre-training for large-scale Transformers has been advocated in both the language and vision domains.
adocated 지지하다
나중에, 사전 훈련된 가중치는 중소규모 데이터 세트를 사용하여 다운스트림 작업에 적용된다. 다운스트림 작업의 예로는 이미지 분류[46], 객체 감지[13], 제로샷 분류[20], 질문 응답[10] 및 동작 인식[18]이 있다. 대규모 트랜스포머에 대한 사전 훈련의 효과는 언어와 비전 영역 모두에서 지지되어 왔다.
For example, Vision Transformer model (ViT-L) [11] experiences an absolute 13% drop in accuracy on ImageNet test set when trained only on ImageNet train set as compared to the case when pretrained on JFT dataset [47] with 300 million images.
예를 들어, Vision Transformer 모델(ViT-L)[11]은 3억 개의 이미지가 있는 JFT 데이터 세트[47]에서 사전 훈련된 경우와 비교하여 ImageNet 훈련 세트에서만 훈련되었을 때 ImageNet 테스트 세트에서 정확도가 절대 13% 감소했습니다. .
Since acquiring manual labels at a massive scale is cumbersome, self-supervised learning has been very effectively used in the pre-training stage.
cubersome 번거로운
2.4 Bidirectional Representations
The training strategy of the original Transformer model [1] could only attend to the context on the left of a given word in the sentence. This is limiting, since for most language tasks, contextual information from both left and right sides is important.
원래 Transformer 모델[1]의 학습 전략은 문장에서 주어진 단어의 왼쪽에 있는 컨텍스트에만 주의를 기울일 수 있었습니다. 대부분의 언어 작업에서 왼쪽과 오른쪽 모두의 컨텍스트 정보가 중요하기 때문에 이것은 제한적입니다.
Bidirectional Encoder Representations from Transformers (BERT) [3] proposed to jointly encode the right and left context of a word in a sentence, thus improving the learned feature representations for textual data in an self-supervised manner.
BERT(Bidirectional Encoder Representations from Transformers)[3]는 문장에서 단어의 오른쪽 및 왼쪽 컨텍스트를 공동으로 인코딩하여 자체 감독 방식으로 텍스트 데이터에 대한 학습된 특징 표현을 개선하도록 제안했습니다.
To this end, BERT [3] introduced two pretext tasks to pre-train the Transformer model [1] in a self-supervised manner: Masked Language Model and Next Sentence Prediction.
이를 위해 BERT[3]는 자기 감독 방식으로 Transformer 모델[1]을 사전 훈련하기 위해 Masked Language Model과 Next Sentence Prediction이라는 두 가지 pretext 작업을 도입했습니다.
For adapting the pre-trained model for downstream tasks, a task-specific additional output module is appended to the pre-trained model, and the full model is fine-tuned end-to-end. Here, we briefly touch upon the pretext tasks.
사전 훈련된 모델을 다운스트림 작업에 적용하기 위해 작업별 추가 출력 모듈이 사전 훈련된 모델에 추가되고 전체 모델이 종단 간 미세 조정됩니다. 여기에서는 구실 작업을 간략하게 다룹니다.
(1) Masked Language Model (MLM) - A fixed percentage (15%) of words in a sentence are randomly masked and the model is trained to predict these masked words using cross-entropy loss. In predicting the masked words, the model learns to incorporate the bidirectional context. (2) Next Sentence Prediction (NSP) - Given a pair of sentences, the model predicts a binary label i.e., whether the pair is valid from the original document or not.
(1) 마스킹된 언어 모델(MLM) - 문장 내 단어의 고정 비율(15%)이 무작위로 마스킹되고 모델은 교차 엔트로피 손실을 사용하여 이러한 마스킹된 단어를 예측하도록 훈련됩니다. 마스킹된 단어를 예측할 때 모델은 양방향 컨텍스트를 통합하는 방법을 배웁니다. (2) 다음 문장 예측(NSP) - 한 쌍의 문장이 주어지면 모델은 이진 레이블, 즉 쌍이 원본 문서에서 유효한지 여부를 예측합니다.
The training data for this can easily be generated from any monolingual text corpus. A pair of sentences A and B is formed, such that B is the actual sentence (next to A) 50% of the time, and B is a random sentence for other 50% of the time. NSP enables the model to capture sentence-to-sentence relationships which are crucial in many language modeling tasks such as Question Answering and Natural Language Inference.
이를 위한 학습 데이터는 모든 단일 언어 텍스트 말뭉치에서 쉽게 생성할 수 있습니다. 한 쌍의 문장 A와 B가 형성되어 B가 50%의 시간 동안 실제 문장(A 옆)이고 B가 나머지 50%의 시간 동안 임의의 문장입니다. NSP는 모델이 질문 응답 및 자연어 추론과 같은 많은 언어 모델링 작업에서 중요한 문장 간 관계를 캡처할 수 있도록 합니다.
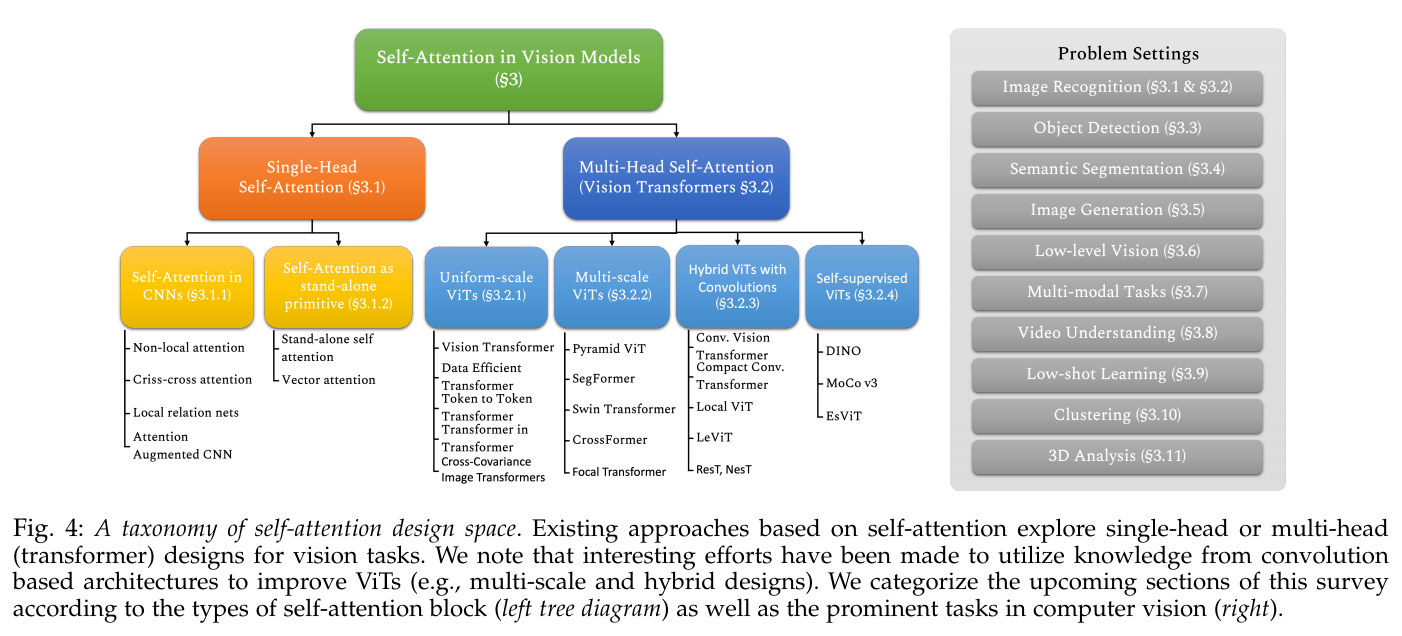
Fig. 4: A taxonomy of self-attention design space. Existing approaches based on self-attention explore single-head or multi-head (transformer) designs for vision tasks.
taxonomy 분류
그림 4: self-attention 디자인 공간의 분류. Self-attention 기반의 기존 접근 방식은 비전 작업을 위한 단일 헤드 또는 다중 헤드(변압기) 설계를 탐색합니다.
We note that interesting efforts have been made to utilize knowledge from convolution based architectures to improve ViTs (e.g., multi-scale and hybrid designs). We categorize the upcoming sections of this survey according to the types of self-attention block (left tree diagram) as well as the prominent tasks in computer vision (right).
upcoming 다가오는 다음의prominent 주요한
우리는 ViT(예: 다중 스케일 및 하이브리드 설계)를 개선하기 위해 컨볼루션 기반 아키텍처의 지식을 활용하려는 흥미로운 노력이 이루어졌음을 주목한다. 우리는 컴퓨터 비전의 주요 과제(오른쪽)뿐만 아니라 자기 주의 블록 유형(왼쪽 트리 다이어그램)에 따라 이 설문 조사의 다음 섹션을 분류한다.
3 SELF-ATTENTION & TRANSFORMERS IN VISION
We broadly categorize vision models with self-attention into two categories: the models which use single-head selfattention (Sec. 3.1), and the models which employ multihead self-attention based Transformer modules into their architectures (Sec. 3.2).
우리는 self-attention이 있는 비전 모델을 싱글 헤드 selfattention을 사용하는 모델(Sec. 3.1)과 아키텍처에 Transformer 모듈을 기반으로 하는 multihead self-attention을 사용하는 모델(sec. 3.2)의 두 가지 범주로 광범위하게 분류합니다.
Below, we first discuss the first category of single-head self-attention based frameworks, which generally apply global or local self-attention within CNN architectures, or utilize matrix factorization to enhance design efficiency and use vectorized attention models. We then discuss the Transformer-based vision architectures in Sec. 3.2.
below 아래에서는
아래에서는 먼저 CNN 아키텍처 내에서 일반적으로 글로벌 또는 로컬 셀프 어텐션을 적용하거나 매트릭스 인수 분해를 활용하여 설계 효율성을 높이고 벡터화된 어텐션 모델을 사용하는 단일 헤드 셀프 어텐션 기반 프레임워크의 첫 번째 범주에 대해 논의한다. 그런 다음 3.2절에서 트랜스포머 기반 비전 아키텍처에 대해 논의합니다.
