1. Overview
OpenAI's o1 등과 같은 LLM의 경우 Inference Time Scaling을 통해서, 상당한 추론 능력 향상을 이루었다.
허나, Vision Language Model (VLM)의 경우, 복잡한 Visual-Quenstion-Answering Tasks에 대해, "systematic" and "structured" reasoning을 수행하는 능력이 다소 뒤떨어져 있다. (24.11 기준)
- Systematic:
model does not generate a direct reasoning
but instead engages in "multistage" reasoning. - Structured:
model clearly identifies the reasoning stage it is in
and understand the primary task to be addressed at each stage
 본 논문에 제시되어있는 위 예시는 "MMStar" Benchmark로부터 채택된 Image-Text pairs로서, 벤치마크로서의 유효성이 보장된다.
본 논문에 제시되어있는 위 예시는 "MMStar" Benchmark로부터 채택된 Image-Text pairs로서, 벤치마크로서의 유효성이 보장된다.
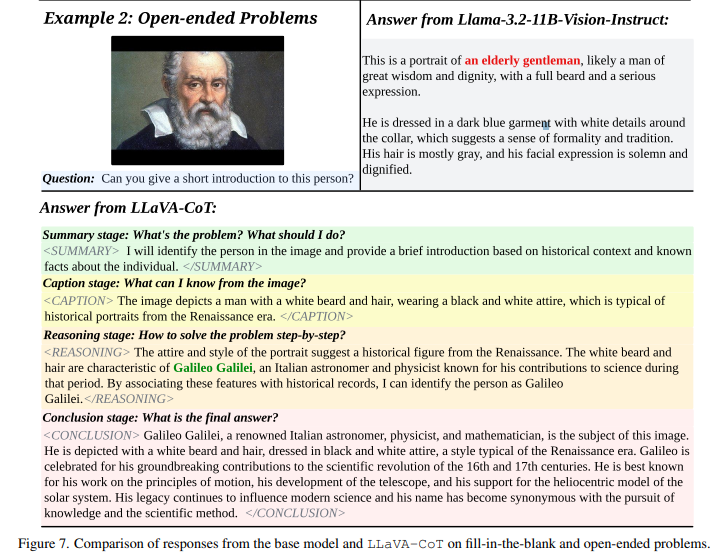
허나, Llama-3.2-11B-Vision-Instruct 와 같은 VLMs의 경우
응답을 생성하기에 앞서
- 문제 해결방식과 활용가능한 시각적 정보에 대한 적절한 구조화를 진행하지 않고
→ "Summary" & "Captioning" stage required - Logical Reasoning으로부터 Conclusion을 정확하게 도출하지 못하기도 한다.
→ "Reasoning" & "Conclusion" stage required.
OpenAI o1 모델은 Language Modality를 통해 "Systematic" and "Structured" Reasoning을 진행함으로써, 추론능력을 향상시킨 것으로 추정되나,
o1 모델의 구체적인 추론 방식은 여전히 Black Box로서 남아있다.
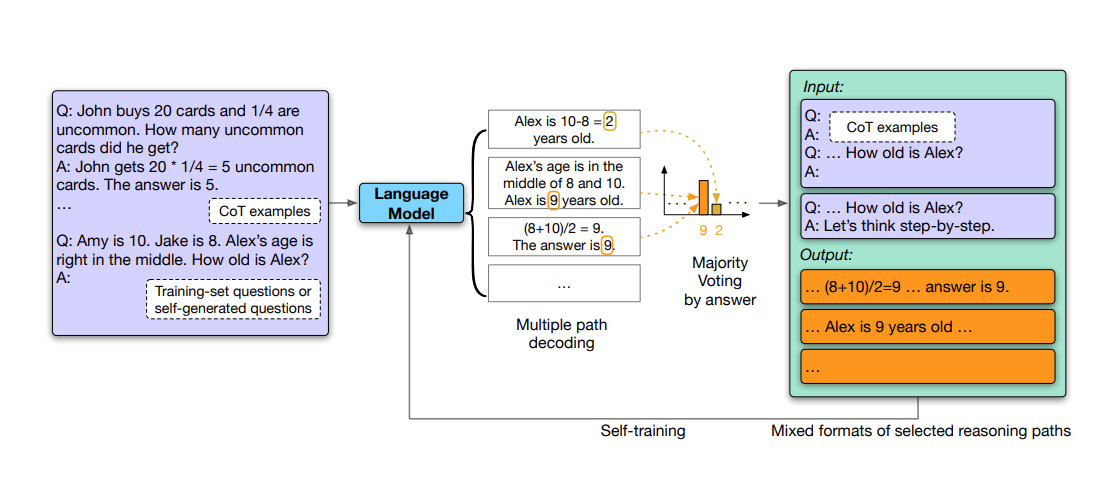
따라서, 저자들은 자율적으로 systematic and structured reasoning을 수행하는 open-source VLM으로서, LLaVA-CoT 모델을 제시하였다.
Chain-of-Thought prompting의 경우, 모델의 Zero- 혹은 Few-shot Generalization Capability룰 활용하여, Prompt를 통해서만 Chain-of-Thought 추론을 지시하지만, 이와 달리 LLaVA-CoT 모델의 경우,
"Summary", "Caption", "Reasoning", "Conclusion"으로 이어지는
Sequential Reasoning Dataset을 통해 모델을 사전에 Instruction-Tuning함에 따라,
이후 Inference 시 모델이 자율적 및 독립적으로 각 추론 단계에 참여하게끔 한다.
 위 추론 예시에서 확인할 수 있듯이, 각 단계에서의 추론은 독립적으로 이루어지게 된다.
위 추론 예시에서 확인할 수 있듯이, 각 단계에서의 추론은 독립적으로 이루어지게 된다.
Summary:
A brief outline in which the model summarizes the forthcoming task.Caption:
A description of the relevant parts of an image (if present),
focusing on elements related to the question.Reasoning:
A detailed analysis in which the model systematically considers the question.Conclusion:
A final response based on the preceding reasoning
앞서 이야기하였듯이, 일반적인 Chain-of-Prompting 과는 달리,
LLaVA-CoT 모델의 경우, "Multi-stage reasoning dataset'을 통해 사전에 Instruction Tuning함으로써, 이후 Inference 시에 각 독립적 추론 단계를 자율적으로 구사하게끔 하는 것이 목표였기에,
저자들은 우선 LLaVA-CoT-100k dataset 을 구축하였다.
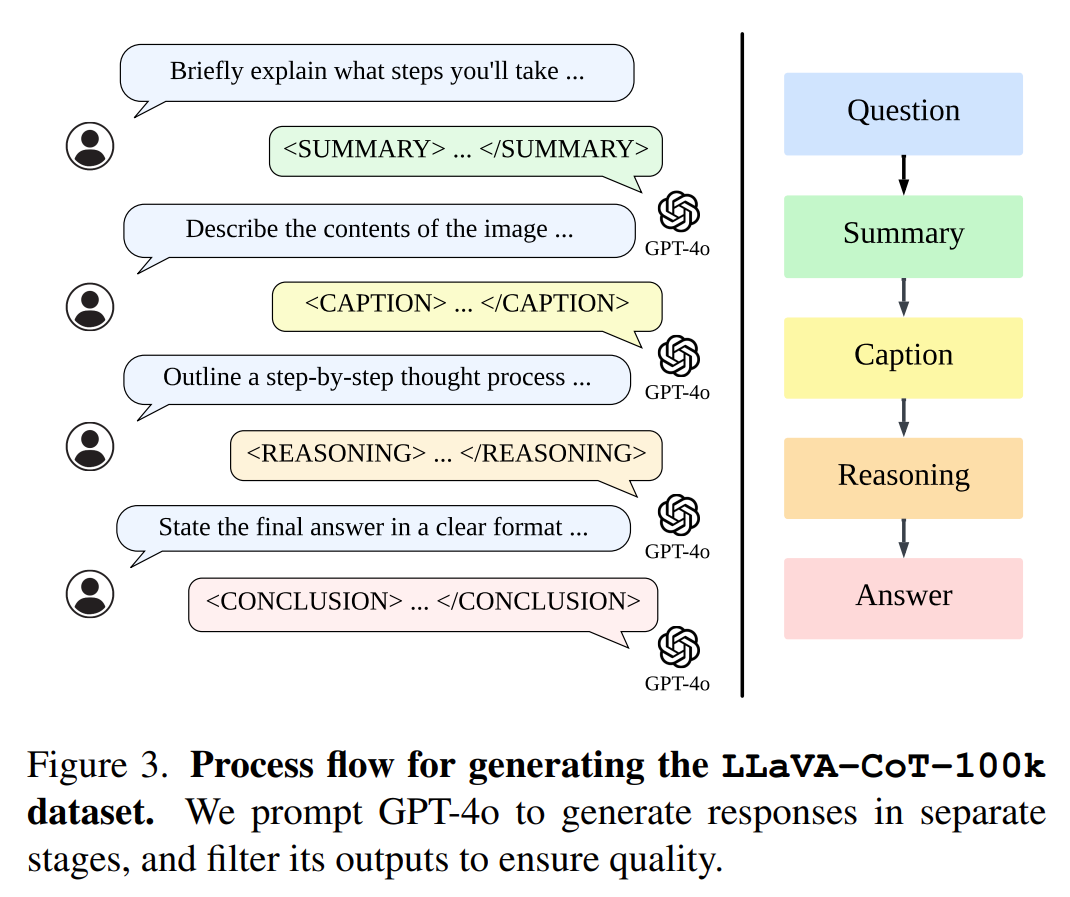 이를 위해, 다양한 VQA 데이터셋으로부터 Sub-Sampling을 수행한 이후,
이를 위해, 다양한 VQA 데이터셋으로부터 Sub-Sampling을 수행한 이후,
위 이미지와 같이 GPT-4o를 활용하여 각 Image-Text pairs에 대해, Stage-By-Stage Reasoning 응답을 추가하였고,
해당 Multi-stage-reasoning 데이터셋으로 모델을 Fine-Tuning 하였다.
이에, 단계적 추론 능력을 함양한 LLaVA-CoT 모델의 능력을 더욱 이끌어내고자
기존과는 다른 Inference-Time-Scaling 기법을 적용하였다.
Conventional scaling methods로서의 'best-of-N sampling' 혹은 'sentence-level beam search' 와는 달리,
LLaVA-CoT는 두 방식의 타협점으로서 'stage-level beam search'를 활용하였다.
stage-level beam search:
"Summary", "Caption", "Reasoning", "Conclusion"의 각 단계별로 다수의 후보 응답을 생성한 이후, 각 단계에서 독립적으로 최적의 응답을 선택해나가는 방식이다.
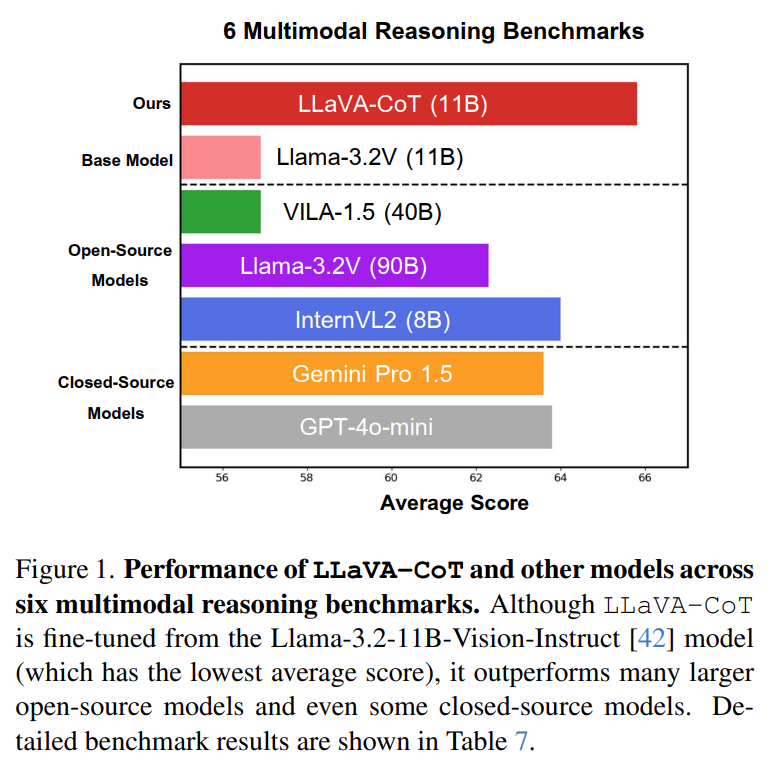
- LLaVA-CoT-100k dataset을 통한 Instruction Tuning
- Inference time scaling: stage-level beam search
2가지만을 적용하였음에도 불구하고,
LLaVA-CoT는 대부분의 Benchmark에서,
base-model로서의 'Llama-3.2-11B-Vision-Instruct' 뿐만 아니라,
심지어 'Gemini-1.5-pro', ' GPT-4o-mini', 'Llama-3.2-90B-Vision-Instruct'와 같이
훨씬 규모가 큰 Open Source Models와 Closed-Source Models까지 앞질렀다.
code, dataset, and pre-trained weights are publicly available: https://github.com/PKU-YuanGroup/LLaVA-CoT
2. Related Works
2.1. Visual reasoning with large language models
OpenAI's o1과 같은 LLM의 advanced reasoning capability를
Visual Modality에도 적용하고자 하는 움직임이 활발함을 언급한다.
2.2. Chain-of-thought in large language models
CoT Prompting은 복잡한 질문에 대한 응답을 단계별로 생성하고자,
질문을 세부적인 추론 단계들로 분해하여, LLM을 Guide하는 기법을 의미한다.
CoT Prompoting이 LLM의 상당한 성능 향상을 가져옴에 따라,
VLM 에도 해당 기법을 적용하고자 하는 움직임이 활발하고,
저자들은 하나의 예시로서 Prism Framework를 제시한다.
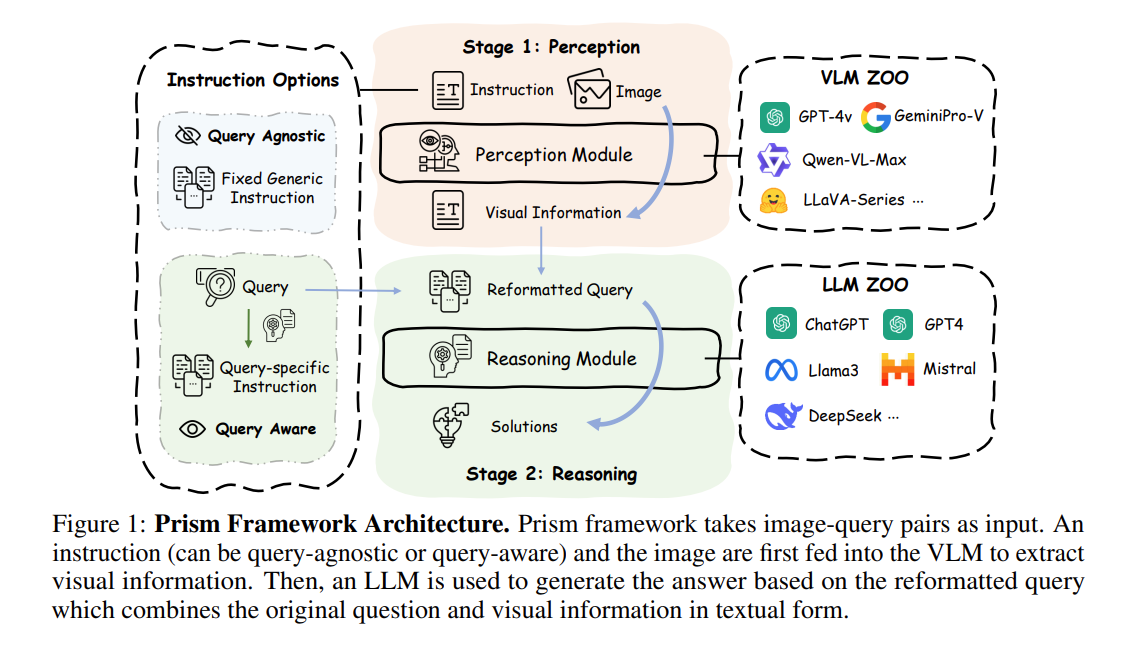 위 이미지에서 확인할 수 있듯이, Prism은 Visual Reasoning을 'Perception' 단계와 'Reasoning' 단계로 나누어서 진행함으로써, 단계적인 추론을 진행하고자 하였다.
위 이미지에서 확인할 수 있듯이, Prism은 Visual Reasoning을 'Perception' 단계와 'Reasoning' 단계로 나누어서 진행함으로써, 단계적인 추론을 진행하고자 하였다.
 MSG 또한 Structured Prompting 기법을 활용하여, Multi-modal Reasoning을 수행하고자 한다.
MSG 또한 Structured Prompting 기법을 활용하여, Multi-modal Reasoning을 수행하고자 한다.
2.3 Inference time scaling
기존의 Inference Time Scaling 기법은 2가지 Main Categories로 분류된다.
- those that rely on an external verifier for selection
- those that operate independently of any external verifier
 External verifier를 통한 Response Selection은 다양한 VLM에서 활용중이지만, External Verifier에 의존하지 않는 기법들도 다수 활용되고 있으며 이는 다음의 기법을 포함한다.
External verifier를 통한 Response Selection은 다양한 VLM에서 활용중이지만, External Verifier에 의존하지 않는 기법들도 다수 활용되고 있으며 이는 다음의 기법을 포함한다.
- Majority Voting:
effective for certain types of problems that have standard answers, but it is not suitable for open-ended tasks.
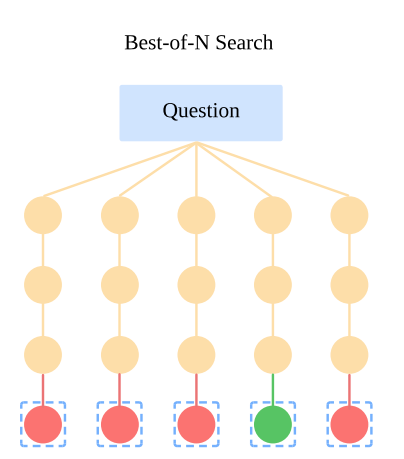
- Best-of-N Search:
generates N complete answers and allows the model to select the best response, but it is computationally expensive.
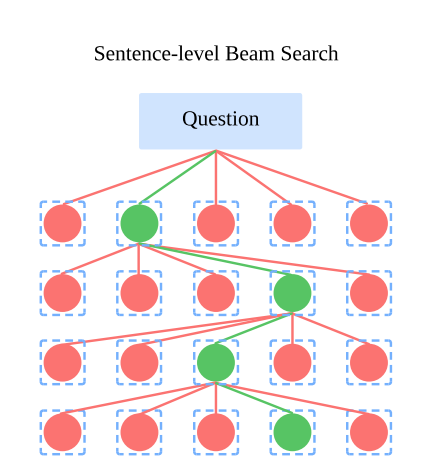
- Sentence-level Beam-search:
generates multiple candidate sentences, selects the best one, and iteratively continues this process. However, this approach operates at too granular a level, which makes it difficult for the model to effectively assess the quality of its responses on a per-sentence basis. Also, often miss the global context in a response.
3. Methodologies
3.1. Training: Enhancing Structured Reasoning Capability
3.1.1. Reasoning Stages
앞서 언급하였듯이, 저자들의 연구 목표는,
확장된 Chains-of-Reasoing을 자율적으로 수행하는 VLM의 개발이었고,
이에 LLaVA-CoT 모델의 응답 생성 과정을
Four structured Reasoning Steps로 분할하였다.
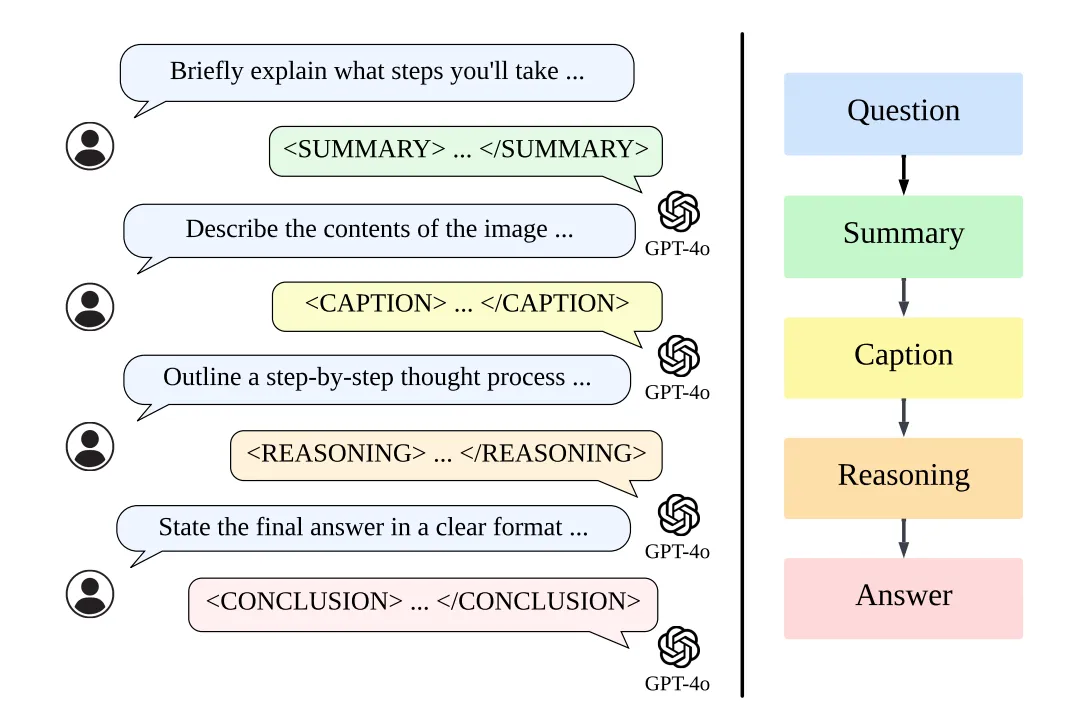 위 이미지와 같이, LLaVA-CoT는 4단계의 추론을 거친다.
위 이미지와 같이, LLaVA-CoT는 4단계의 추론을 거친다.
Summary:
summarizing the response approach
Caption:
describing instruction-relevant image content
Reasoning:
conducting structured reasoning building on the initial summary.
Conclusion:
synthesizing an answer based on the preceding reasoning.
The output at this stage adapts to the user’s requirements:
brief answer request → concise conclusion
detailed explanations desired → thorough conclusion
각 추론 단계는 LLaVA-CoT 모델의 재량 하에, 자율적으로 활성화되고,
OpenAI's o1과 같이, 모든 단계는 Single-Inference-Pass를 통해 일괄적으로 진행된다.
3.1.2. Data Preparation and Model Training
"Dataset Preparation"
LLaVA-CoT 모델의 단계적 추론 능력 향상을 위해서는, 단계별 Reasoning Process가 명시되어있는 구조화된 Dataset이 필요하지만, 대부분의 기존 VQA Dataset은 구조화된 추론 과정이 명시되어있지 않다.
이에 저자들은 널리 사용되고 있는 VQA datasets로부터 우선 Subsampling을 진행 및 통합하여, 총 99k Visual QA pairs를 수집하였다.
(각 pair는 single 혹은 multiple rounds of QA로 구성된다)
각 VQA benchmark로부터 추출된 QA pairs의 수는 다음과 같다.
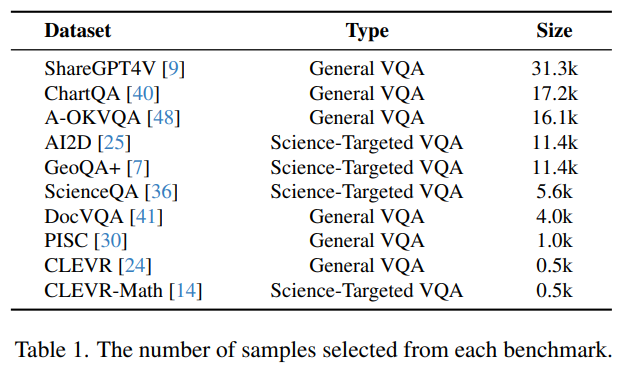
General VQA Benchmarks
ShareGPT4V: Real conversations from GPT4 Users
ChartQA: Interpreting charts and graphs
A-OKVQA: emphasizes External knowledge beyond visible content
DocVQA: involves document-based questions requiring textual comprehension
PISC: social relationships
CLEVR: object properties, spatial relationships, and counting tasks.
Science-Targeted VQA Benchmarks
GeoQA+: geometric reasoning
AI2D and ScienceQA: scientific questions
CLEVR-Math: arithmetic analysis in visual contexts
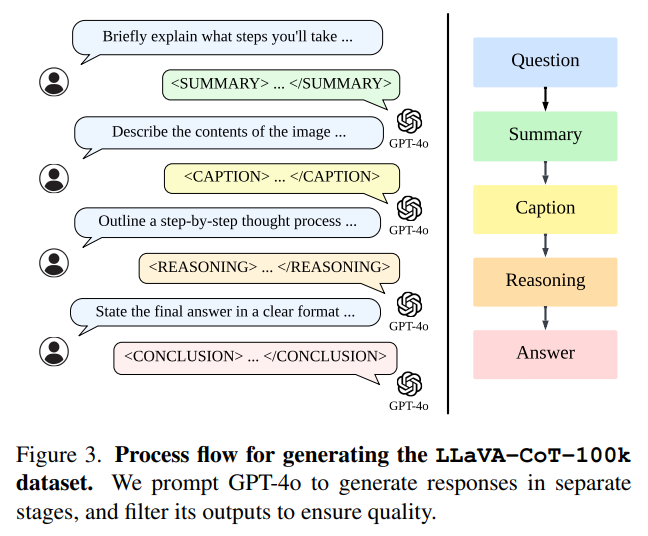
99k Visual QA pairs는 VQA Benchmark로부터 Subsampling 한 것으로, Structured Reasoning Process가 결여되어 있기에,
저자들은 GPT-4o를 활용하여, 각 Image-Text Pair에 대해
"Summary", "Caption", "Reasoning", "Conclusion" 으로 이어지는 detailed reasoning process를 추가함으로써,
LLaVA-CoT-100k dataset을 생성하였다.
"Training"
저자들은 Llama-3.2-11B-Vision-Instruct를 base model로 선정한 뒤,
LLaVA-CoT-100k dataset을 기반으로 full parameter fine-tuning을 진행하였다.
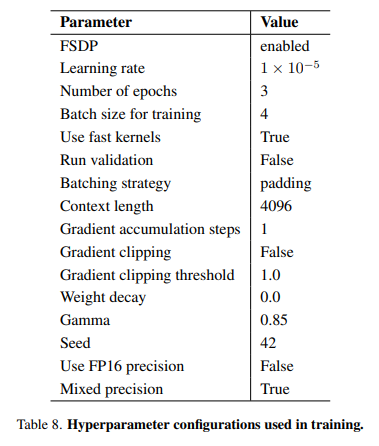
학습은 a single node with 8 H100 GPUs 에서 진행되었고, Hyperparameter는 다음과 같이 설정되었다.
Llama-3.2-11B-Vision-Instruct Architecture
출처: https://medium.com/@tsunhanchiang/llama-3-2-metas-blueprint-for-consumer-ai-77d184bce6de
Llama 3.2-Vision 모델은 사전학습된 Llama 3.1 text-only model과
별도로 학습된 vision-adapter를 통합함으로써 구축되었다.
Vision-Adapter는 일련의 Cross-Attention-Layers로 구성되었으며,
Image Encoder's representation을 LLM Decoder에 Input하는 방식을 취한다.
3.2. Inference: Stage-level Beam Search
LLaVA-CoT-100k dataset을 통한 Fine-Tuning 이후,
Inference 시에, 모델의 단계적 추론 능력을 더욱 향상시키고자
저자들은 LLaVA-CoT 모델의 Stage-based-reasoning-output을 활용한다.
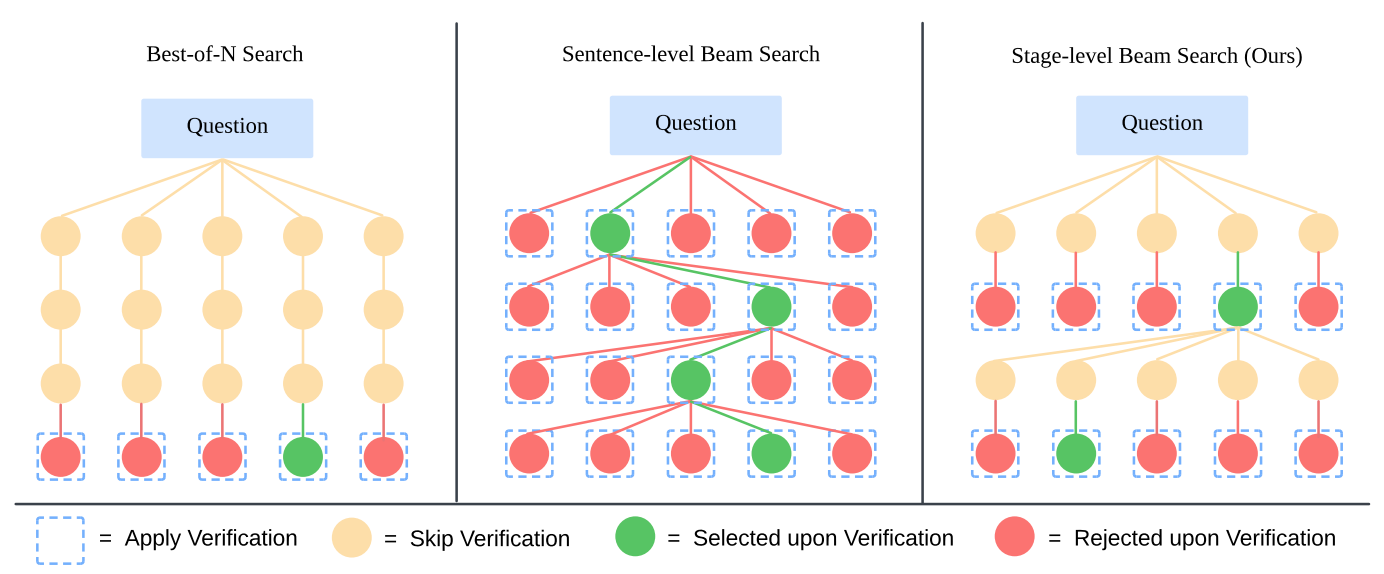
즉 저자들은 Stage-level-Beam-Search를 제시하였고, 해당 방식이 다음의 특성을 지닌다고 주장한다.
→ ideal balancing between (Best-Of-N Search) and (Sentence-Level-Beam Search)
→ ideal granularity for inference time scaling
Stage-level-Beam-Search
1. Sample N responses for the first stage in the solution.
2. Randomly sub-sample 2 responses and let the model determine which is better, keeping the better response.
3. Repeat for N − 1 times, retaining the best response.
4. Sample N responses for the next stage,
5. Repeat steps 2-4 until all stages are processed.
→ 정리하자면, “Summary”, “Caption”, “Reasoning”, “Conclusion” 의
각 단계에서 N개의 응답을 생성 및 비교하여, 단계별 최적의 응답 선정.
→ Here, LLaVA-CoT acts as a judge to evaluate responses.

LLaVA-CoT's Structured Ouput Design을 기반으로
"Stage-level-beam-search'를 진행함에 따라,
각 단계별로 efficienct & accurate verification이 가능해졌고,
이에 다음 예시와 같이 단계적 추론을 통해 정확한 응답을 생성하는 능력이 향상되었다.
4. Post-Training Performance
여기서 말하는 Post-Trainig 이란,
Base model로서의 Llama-3.2-11B-Vision-Instruct에
“LLaVA-CoT-100k” dataset을 통한 ”full parameter fine-tuning”
만을 적용한 LLaVA-CoT 모델을 의미하는 것으로,
Inference-time-scaling은 아직 적용하지 않은 상태이다.
Multi-modal benchmarks
MMStar, MMBench, and MMVet:
primarily evaluate the general visual question-answering capabilities of models.
MathVista, and AI2D:
focus on models’ proficiency in mathematical and scientific reasoning.
HallusionBench:
specifically assesses the models’ handling of language hallucinations and visual illusions.
Benchmark Results
LLaVA-CoT의 경우, 100k data만을 활용하였음에도 불구하고
"general VQA"
"mathematical reasoning, scientific VQA"
"hallucination control tasks"
에서 평균적으로 6.9%의 benchmark score 향상을 달성하였다.
→ Effectiveness of ”full parameter fine-tuning” using the “LLaVA-CoT-100k” dataset.
구체적으로 LLaVA-CoT가 Base Model에 비해서 어떤 능력이 향상되었는지를 분석하고자, MMStar benchmark에 대한 상세한 평가를 진행한 결과
이에,
"Instance Reasoning"
"Logical Reasoning"
"Math"
"Science & Technology"
등 systematic reasoning을 요구하는 태스크에서 상당한 발전을 확인하였지만,
"Coarse Perception"
"Fine-grained Perception"
등 복잡한 추론을 요구하지 않는 Tasks에서는 상대적으로 성능 향상이 적었다.
이를 통해,
“LLaVA-CoT-100k” dataset을 통한 ”full parameter fine-tuning”이 "Reasoning capability"를 향상시킴을 확인할 수 있다.
5. Inference Time Scaling Performance
→ structured output design of LLaVA-CoT
→ stage-level beam search (Beam Size 2)
→ balance between “rigorous quality control” and “computational efficiency”
→ higher accuracy on complex reasoning tasks without significant computational overhead
Comparison to Baseline inference-time-scaling methods on the MMVet benchmark
→ superiority of stage-based search
Beam Size ⬆️ → performance ⬆️
→ stage-level beam search is scalable
6. Comparison to State-Of-The-Art VLMs
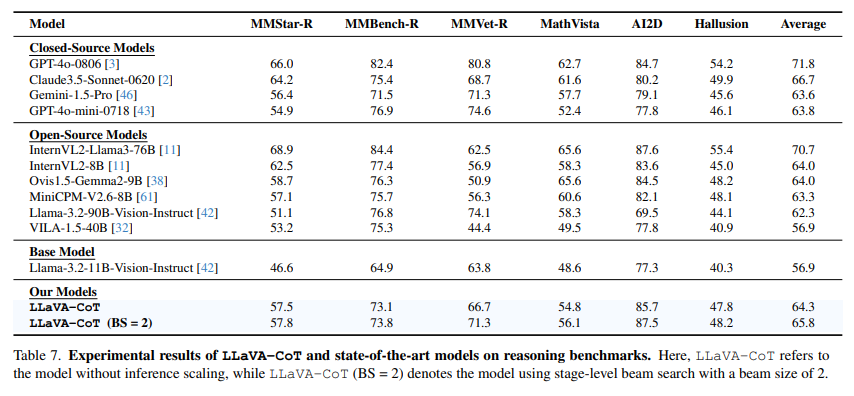 LLaVA-CoT consistently outperforms many
LLaVA-CoT consistently outperforms many
open-source models of similar or even larger sizes, such as
- InternVL2-8B
- MiniCPM-V2.6-8B
- Ovis1.5-Gemma2-9B
- VILA-1.5-40B
- Llama-3.2-90B-Vision-Instruct
LLaVA-CoT even surpasses certain closed-source models like
- GPT-4o-mini
- Gemini-1.5-pro
→ LLaVA-CoT: competitive model in reasoning-intensive VLM tasks

7. Conclusion
LLaVA-CoT:
A novel VLM that performs
structured, autonomous reasoning in multiple stages
[ Summary, Caption, Reasoning, Conclusion ]Two Contributions
1. LLaVA-CoT-100k dataset
→ with detailed reasoning annotations,
→ supports training on systematic, structured responses
→ can be used to further conduct Supervised FineTuning (SFT) on any existing VLM to enhance reasoning capabilities2. Stage-level beam search
→ effective scalable inference time scaling
→ can be used to achieve higher accuracy on complex reasoning tasks without significant computational overhead on existing VLM→ LLaVA-CoT의 위 2가지 Contribution은, 기존 VLM의 추론 능력 향상을 위해 손쉽게 적용 가능
