
1. Overview
LLM의 Zero- 혹은 Few-shot Generalization Capability를 이끈 Supervised Instruction Tuning을 Vision Language Model로 확장하고자 한 연구들이
LLaVA series model 을 기반으로 활발히 진행되었으나,
Visual과 Language Modality간에 Alignment를 이루고자 하는
'Feature-Alignment-Pre-training'에 대한 깊이 있는 연구는 진행되지 않았다. (23.12 기준)
이에 저자들은 LLM's Capability를 VLM 분야로 확장하기 위한 Training 기법을 위주로 연구를 진행하였고 다음의 three-main-findings를 제시하였다.
(1) Feature-Alignment를 위한 Pre-Training 동안, LLM의 가중치를 고정하는 것이 Zero-Shot capability에는 도움이 되지만, Deep-Embedding-Alignment를 이루지 못함에 따라 In-Context learning capability 에는 도움이 되지 않는다.
(2) 'Image-Text' pair dataset만을 활용하는 방식은 최적이 아니며, 'Interleaved pre-training data'를 추가적으로 활용하는 것이 Accurate-gradient-update와 maintaining-text-capability에는 도움이 된다.
(3) Instruction fine-tuning을 진행함에 있어, Visual instruction data 뿐만 아니라 'text-only' instruction data 또한 활용하는 것이, text-only tasks에 대한 degradation을 완화할 뿐만 아니라, VLM Tasks accrucay 또한 증가시킨다.
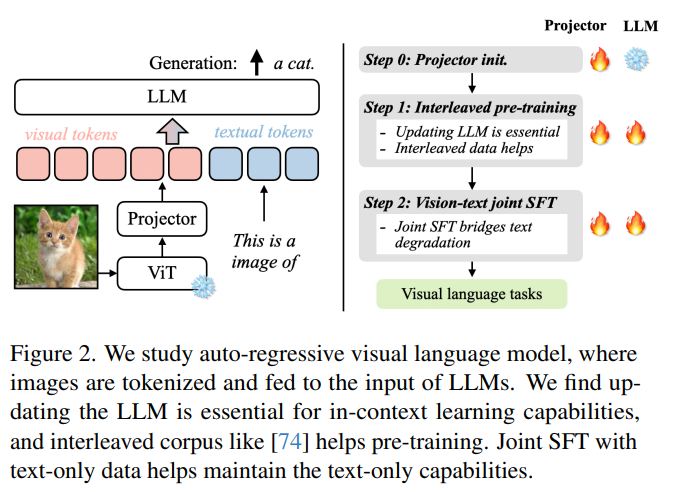
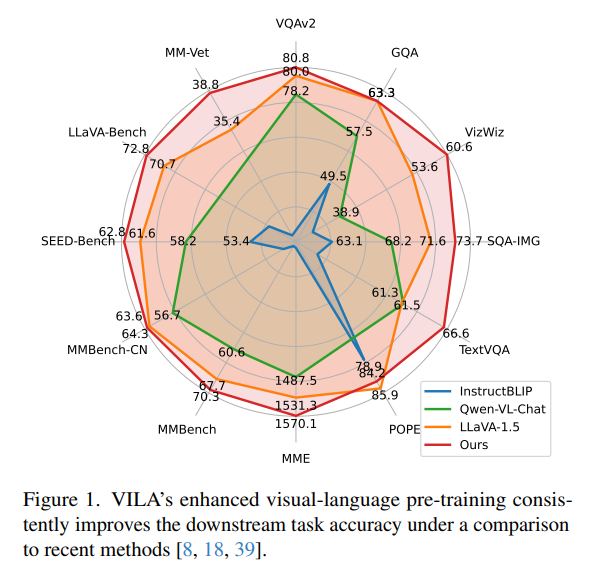
위 Pre-Training recipe를 기반으로 저자들은 'VIsual LAnguage model family' "VILA"를 제시하였고, 이는 LLaVA-1.5 와 같은 SOTA 모델보다 여러 Benchmark에서 좋은 성능을 보여준다.
저자들은 VILA 모델이 더 나은 Pre-Training 기법을 통해
- Multi-Image Reasoning
(despite the model only sees single image-text pairs during SFT) - stronger In-Context Learning
- Better world knowledge
등의 장점을 지니게된다고 이야기한다.
2. Related Work
LLMs
Tranformer Decoder에 기반한 LLMs은 Model-size와 Pre-training-corpus를 Scaling-up 함으로써, 자연어 처리 분야를 근본적으로 변화시켰다.
최근에는 Large-scale Pre-training process 뿐만 아니라
Instruction Tuning과 Reinforcement-Learning-from-Human-Feedback을 통해
더욱 강력한 Base LLMs이 개발되고 있다.
저자들은 'Llama-2' Open-source Model을 base model로 설정하였다.
VLMs
LLM's Reasoning Capability를 Visual Modality로 확장하고자 하는
Vision-Language-Model에 대한 연구가 활발히 진행되어왔다.
몇몇 연구는 LLM의 가중치를 고정한 채로, Visual Encoder, Visual Resampler 등 Auxiliary components 등을 학습시켰고, 다른 연구들은 Visual Reasoning을 더욱 활성화하고자 LLM Decoder 또한 Supervised-Instruction-Tuning 하였다.
이 외에도 'Image-Text pairs', 'Video-Text pairs', 'Interleaved Datasets', 'Visual-Grounded annotations' 등 Data corpora에 대한 연구 또한 활발히 진행되었다.
저자들은 위와 같이 'VLM Pre-training의 다양한 Design choice'에 대해
광범위한 ablation을 진행하였는데,
기존 VLMs에 대한 Design은 크게 2가지로 구분된다.
(1) Cross-Attention based VLMs
LLM의 가중치를 고정한 채로, Cross-Attention Mechanism을 통해 Intermediate Embeddings와 Visual Information을 결합하는 방식이다.
Llama-3.2-Vision Architecture출처: https://medium.com/@tsunhanchiang/llama-3-2-metas-blueprint-for-consumer-ai-77d184bce6de
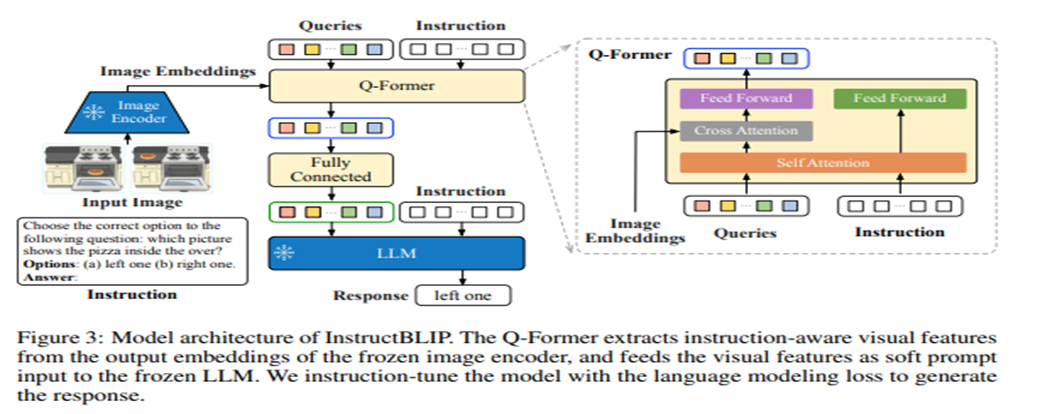
InstructBLIP Architecture
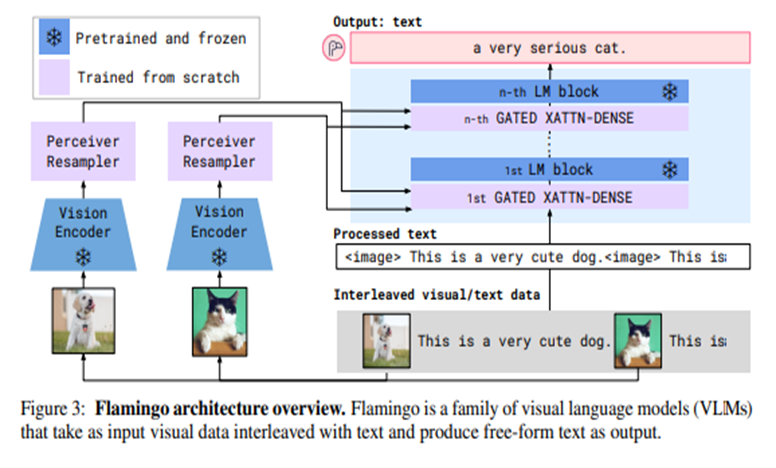
Flamingo Architecture
(2) Auto-regressive VLMs
Visual Input이 Visual Encoder와 Visual Resampler를 거쳐 tokenized 된 이후,
text tokens (query, outputs) 과 같이 LLM Decoder에 Input 되는 방식이다.
이는 Visual Inputs을 Foreign language처럼 취급하는 LLM's natural extension으로, 전체 VLM 파이프라인을 Supervised-Instruction-Tuning 하기에,
Human Visual Instruction을 더 잘 따른다고 이야기된다.
저자들은 Multi-modal-inputs에 대한 handling-flexibility를 위해,
Auto-Regressive VLMs을 기반으로 Pre-Training process를 연구하였다.
LLaVA (1, 1.5) Architecture
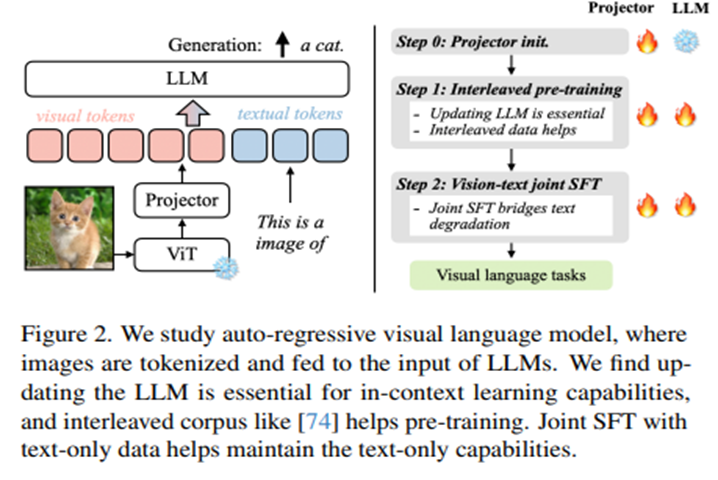
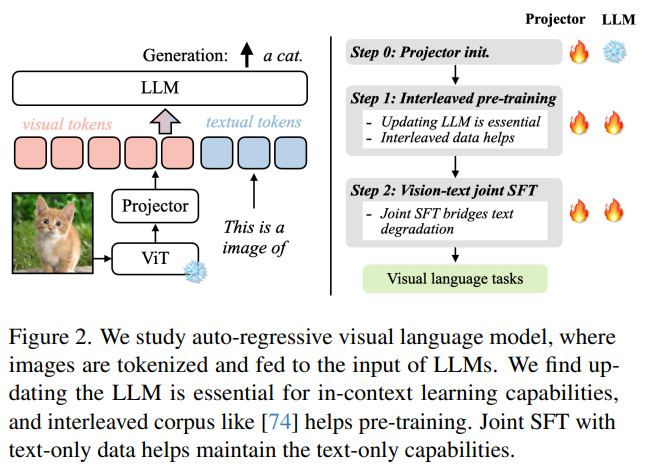
VILA Architecture
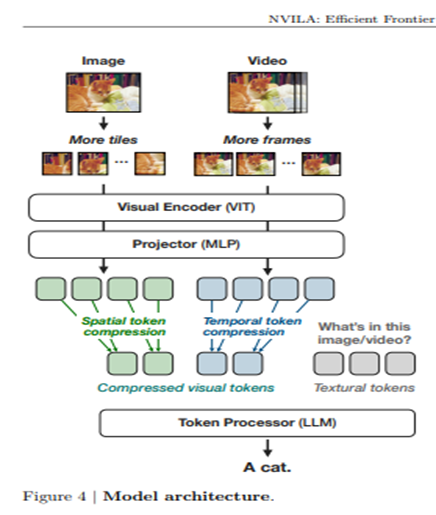
NVILA Architecture
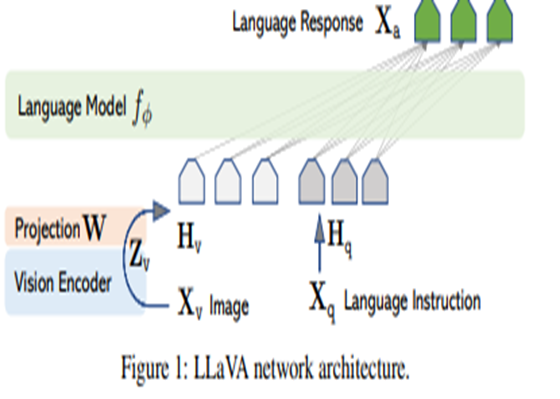
3. Background
3.1. Model Architecture
Visual Embedding을 Text Embedding과 단순히 Concatenate한 이후
LLM Decoder에 Input하는 방식을 취함에 따라
Arbitrary interleaved image-text input을 처리할 수 있는
Auto-regressive VLMs의 아키텍처는 일반적으로 위 그림처럼 구성된다.
- Visual Encoder
- Vision → Language Projector
- LLM Decoder
Projector의 경우,
LLaVA처럼 Simple-linear-layer로 구성할 수도 있고,
InstructBLIP's Q-Former 처럼 더욱 Capable한 Transformer block으로 구성할 수도 있기에,
저자들은 Simple-linear-projector와 Transformer-projector 간에 Ablation을 진행하였다.
3.2. Training Stages
Text-only LLM Decoder를 기반으로 VLM을 구축함에 있어
학습 파이프라인은 다음의 3가지로 세분화 될 수 있다.
0. Projector initialization
Llama-2와 같은 LLM Decoder와 CLIP-ViT와 같은 Visual Encoder는 Foundation Model로서 독립적으로 Pre-training 되는 반면,
두 Modality를 연결하는 Projector는 일반적으로 Random-weights로 초기화된다.
따라서, ViT visual encoder와 Llama-2 language decoder의 가중치를 고정한채로, 우선 Projector에 대해 'image-caption pairs' 를 활용하여 Feature-Alignment-Pre-Training 을 진행한다.
1. visual language pre-training
1차적인 Feature-Alignment pre-training을 진행한 이후,
LLM Decoder와 Projector에 대한 2차적인 pre-training을 진행한다.
이때, 두 종류의 Visual-Language Corpus를 활용한다:
- Interleaved Image-Text Corpus
- Image-Text pairs
저자들은
most costly but most important for visual language alignment:
visual language pre-training을 가장 중요한 학습 단계로서 이야기한다.
2. Visual instruction-tuning
pre-trained VLM에 대해 Visual Instruction datasets에 기반하여
마지막으로 Instruction-Tuning을 진행하는 단계이다.
4. On Pre-training for Visual Language Models
4.1. Updating LLM is Essential
Pre-Trained Text-Only LM을 기반으로 VLM을 구축함에 있어
LLM의 가중치를 고정할 경우, text-only task에 대한 degradation을 완화할 수는 있지만,
In-Context Learning과 같은 LLM의 Emerging-properties를 Visual Modality에서도 발견하기 위해서,
저자들은 LLM Decoder 또한 학습시켜야함을 강조한다.
(1) 위 표에서 확인할 수 있듯이, Supervised Fine Tuning 동안 LLM의 가중치를 고정하고, Projector만을 학습시켰을 때, Transformer-based Projector를 활용함으로써 Projector의 Capacity를 크게 가져갔음에도 불구하고, 모든 벤치마크에서 Zero-, Few-shot Capability가 낮게 나타났고, 이를 통해 SFT 동안 LLM 또한 Fine-Tuning 해야 함을 추론할 수 있다.
(2) Pre-Training 동안 LLM의 가중치를 고정하는 것이 0-shot 성능에는 영향을 미치지 않았지만, 4-Shot generalization 등의 In-Context-Learning 성능에는 분명한 악영향을 미쳤다.
(3) Transformer block 대신 linear layer projector를 활용함으로써, projector의 capacity를 작게 가져갔을 때, Benchmark에 대한 성능은 오히려 증가하였다. 저자들은 Simple Projector가 Visual Input을 처리하는 방식을 더욱 효과적으로 학습한다고 이야기하는데, LLaVA Series 논문에서도 Transformer-based complex projector는 Feature-Alignment-Pre-training을 위해 large-scale image-text pairs를 활용함에도 불구하고, Underfitting 될 수 있음이 언급되었다.
LLM Fine-tuning 에 대한 근거: The deep embedding alignment hypothesis
LLM을 Fine-tuning하는 것이 중요함을 증명하고자
저자들은 우선, Visual latent embeddings와 textual latent embeddings간에 distribution alignment를 이루는 것이 중요함을 가정하는데, LLM's in-context learning capability와 같은 특성을 Visual Modality로 가져오기 위해서, 두 Modality 간에 Alignment를 이루는 것은 필수적이다.
이에 LLM의 각 Layer 별로 Visual embeddings과 Textual Embeddings 간에 pairwise consine similarity를 계산함으로써,
두 Modality 간에 Chamfer distance를 계산하였고, 결과는 위 그래프와 같다.
LLM을 fine-tuning함에 따라, deeper layer에서 두 Modality 간에 cosine similarity가 높게 나타났는데,위 표를 통해 확인할 수 있듯이, Text Decoder로서의 LLM을 Fine tuning함에 따라 4-shot accuracy 또한 증가하는 것을 확인할 수 있다.
이를 통해 'Fine-tuning LLM', 'Deep embedding alignment', 'In-context learning capability'간에 양의 관계가 성립함을 추론할 수 있다.
이에, 저자들은 최종적으로 'Feature-Alignment-pre-training'과 'Supervised instruction-tuning'을 진행함에 있어,
Deeper Embedding Alignment를 통한 In-context learnning capability를 위해
"LLM을 fine-tuning" 하였고
transformer-projector 대신 "Simple linear projection layer"를 활용하였다.
4.2. Interleaved Visual Language Corpus Helps Pre-training
Interleaved format:
기존 VLM pre-training은 widely available 'image-text pairs' (i.e., image and captions)를 활용하였지만,
저자들은 LLM backbone이 VLM Pipeline에서 Visual Input 또한 원활하게 입력받게끔 학습시키기 위해서는,
Text 사이에 Visual Input (i.e., Images, videos)이 Interleaved 된
Interleaved dataset이 중요함을 가정하였다.
이에 각 Image에 대해 Short description이 할당됨으로써, LLM's Pre-trainig data와는 달리 short text distribution을 지닌 COYO Dataset으로부터, CLIP Similarities에 기반하여, 오직 25M images만을 subsampling한 이후, Interleaved dataset으로서의 MMC4를 함께 활용하였다.
위 표를 통해,
'Image-Caption pairs': 'COYO' 와
'Interleaved dataset': 'MMC4' 를
함께 활용했을 때, Zero- / Few-shot capability가 모두 상승하는 것을 확인할 수 있다.
또한 'Image-Caption pairs'로 구성된 'COYO' dataset을 기반으로 pre-training을 진행하였을 때, text-only accuracy (MMLU)가 상당히 떨어지는 것을 확인할 수 있는데,
저자들은 COYO Dataset의 text-based caption이 LLM's pre-training dataset과는 달리, 지나치게 짧고 간결하기 때문이라고 가정한다.이와 달리 'Interleaved corpus'로 구성된 'MMC4' dataset은 LLM's pre-training dataset, 즉 text-only corpus와 유사한 distribution을 지녔기에,
'MMC4' Dataset을 기반으로 pre-training을 진행하였을 때는, text-only accuracy가 상대적으로 훨씬 적게 떨어짐을 확인할 수 있다.
Pre-training에서의 작은 degradation은 이어지는 Instruction-tuning을 통해 fully recoverable하기에,
LLM's pre-training corpus와 유사한 distribution을 지닌 Interleaved dataset으로 Pre-training을 진행하는 것이, LLM's capability를 VLM로 확장함에 있어 필수적임을 알 수 있다.위 그래프를 통해서, 'Image-text pairs'로 구성된 'MMC4-Pairs' dataset이 아닌 'Interleaved corpus'로 구성된 'MMC4' dataset으로 Pre-training을 진행하였을 때, loss가 더 작게 나타남을 확인할 수 있다.
저자들은 Interleaved corpus가 LLM's pre-training corpus와 distribution이 유사함에 따라,
VLM이 LLM Backbone을 통해 Interleaved corpus 상에서 Image related text information을 더 잘 포착할 수 있다고 이야기한다.
MMC4-Pairs:
MMC4:
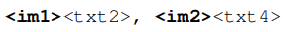
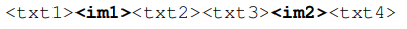
4.3. Recover LLM Degradation with Joint SFT
Interleaved data를 통해, VILA's Pre-training data distribution을 LLM's pre-training data distribution과 유사하게 가져감으로써 Text-only capability를 유지하고자 하였지만,
여전히 text-only task에 대해 5%의 accurcacy drop이 존재하기에,
저자들은 LLM's pre-training 에 사용되는 text-only corpus를 활용하였다.
또한 저자들은 Vision-Language feature-alignment-pretraining 동안
Text-only capability가 'forgotten' 되지 않고 'hidden' 되었다는 점에 착안하여,
일반적으로 trillion scale에 해당하는 LLM's pre-training corpora 와는 달리, 상대적으로 훨씬 적은 text-only corpora를 'SFT' 과정에 추가함으로써,
Data-efficient manner로 LLM's degradation을 recover하였다.
구체적으로는 1M text-only instruction tuning data를 VQA dataset과 blending 하였으며, 이를 통한 정확도 향상을 다음 표를 통해 확인할 수 있다.1M text-only instruction tuning data를 통해 Fine-tuning한 Llama-2 base model과 비교하였을 때,
Feature-alignment-pretraining 과정에서 발생한 Text-capability-degradation을 복구하였을 뿐만 아니라,
Zero- / Few-shot generalization과 같이 Visual-langauge-capability 까지 증가한 것을 확인할 수 있다.
Text-only instruction-tuning-data를 포함하여
LLM's pre-training corpora 와 Data distribution (token length) 을
유사하게 가져감으로써,
Short-Caption이 대부분인 VQA Dataset으로부터 발생하는
Text-capability-degradation을 완화한 것으로 설명할 수 있다.
5. Experiments
5.1. Scaling up VLM
앞서 언급한 다양한 Ablation을 기반으로
LLM's Capability를 최대한 활용하는 VLM을 구축하고자
저자들은 VLM Pipeline을 Scale-up 하였다.
Higher Image Resolution
'TextVQA'과 같이, Fine-grained details 를 요구하는 VQA Task에 대해 성능을 올리고자
Visual encoder로서 활용되는 OpenAI CLIP visual encoder의 Input resolution을
에서 으로 증가시켰다.
Larger LLMs
Text-capability를 증가시키고자,
Ablation study에서 활용되었던 Llama-2 7B Model에서
Llama-2 13B 모델로 LLM Backbone을 scale-up 하였다.
Pre-training data
Feature-alignment-pretraining을 위해, Image-caption pairs 뿐만 아니라 interleaved image-text data 또한 활용하였다.
총 50M Images를 포함하는 pre-training corpus를 활용하여 data diversity를 증가시켰다.
물론 여타 VLM's pre-training에 활용되는 bilion-scale-data와 비교하였을 때는 적지만, 저자들은 50M scale pre-training data만으로도, 상당한 성능 향상을 이루었다고 주장한다.
SFT data
High-quality LLaVA-1.5 dataset 을 SFT 과정에 추가적으로 활용하였다.
자세한 SFT dataset 구성은 논문의 Appendix를 통해 확인할 수 있다.
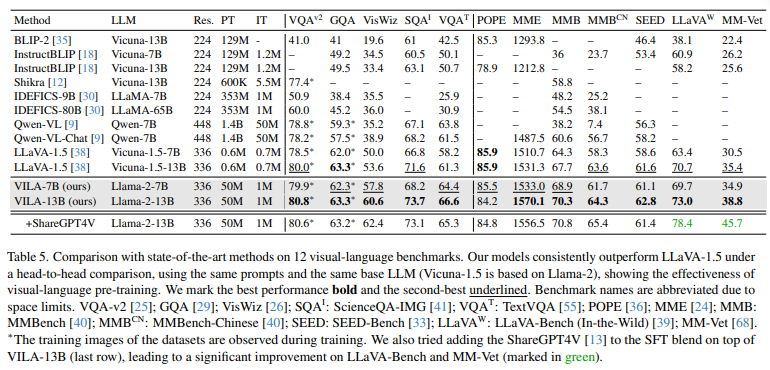
5.2. Quantitative Evaluation
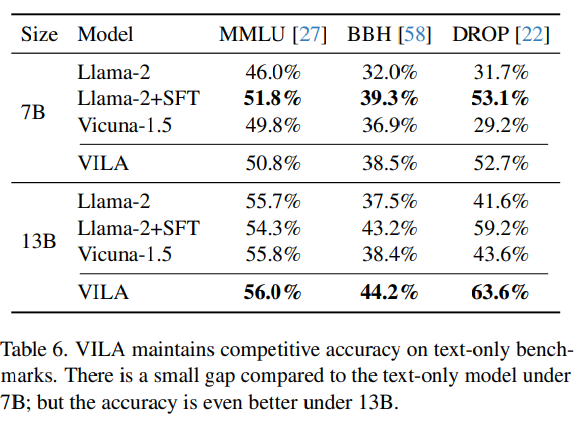
5.3. Qualitative Evaluation
- Scaling up VLM Piepline
- Interleaved dataset
- Joint SFT with text-only instruction-tuning datasets
- Decoder LLM Pre-training
등을 적용함으로써, VILA model은 다음의 Emerging-properties를 보여준다.
Multi-image reasoning

In-context learning

Visual Chain-of-Thoughts (CoT)

Better world knowledge

5.4. Other findings
- Image resolution matters, not #tokens
We can use different projector designs to compress the visual tokens
(ex. “downsample” projector, which simply concatenates every 2 × 2 tokens into a single one and use a linear layer to
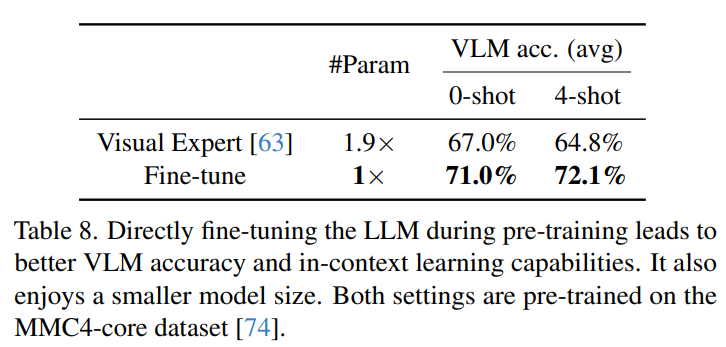
fuse the information)- Comparison to frozen LLMs with visual experts
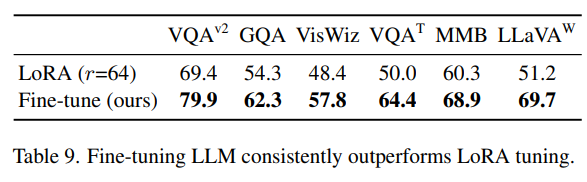
- Comparison to PEFT/LoRA
- "Interleaved" structure is important

6. Conclusion
저자들은 LLM's Capability를 VLM 분야로 확장하기 위한
Training 기법을 위주로 연구를 진행하였고
다음의 three-main-findings를 제시하였다.
(1) Feature-Alignment를 위한 Pre-Training 동안, LLM의 가중치를 고정하는 것이 Zero-Shot capability에는 도움이 되지만, Deep-Embedding-Alignment를 이루지 못함에 따라 In-Context learning capability 에는 도움이 되지 않는다.
(2) 'Image-Text' pair dataset만을 활용하는 방식은 최적이 아니며, 'Interleaved pre-training data'를 추가적으로 활용하는 것이 Accurate-gradient-update와 maintaining-text-capability에는 도움이 된다.
(3) Instruction fine-tuning을 진행함에 있어, Visual instruction data 뿐만 아니라 'text-only' instruction data 또한 활용하는 것이, text-only tasks에 대한 degradation을 완화할 뿐만 아니라, VLM Tasks accrucay 또한 증가시킨다.
저자들은 'VIsual LAnguage model family' "VILA"를 제시하였고,
이는 LLaVA-1.5 와 같은 SOTA 모델보다 여러 Benchmark에서 좋은 성능을 보여준다.
저자들은 VILA 모델이 더 나은 Pre-Training 기법을 통해
다음의 Capability를 지니게 되었다고 이야기한다
- Multi-Image Reasoning
- Stronger In-Context Learning
- Better world knowledge
