
Project page: https://huggingface.co/datasets/MUIRBENCH/MUIRBENCH
1. Overview
인간은 다양한 장면으로부터 다양한 시간대에 연속적 혹은 이산적으로 수집된 시공간적 장면을 이해할 수 있기에,
Multi-Image 혹은 Video에 대한 총체적 시각적 이해능력을 기반으로
- 일련의 만화 혹은 영화 장면으로부터 이야기를 해석해내고
- 다양한 차트와 표로부터 차이점을 추출하고
- 과거 장면으로부터 다음 행동을 예측하고
- 복잡한 3D 장면을 자세히 이해할 수 있다.
이렇듯, Multi-image input은 공간적 의미를 풍부하게 전달하고
Time-sequential한 이미지를 기반으로 시간적 의미까지 풍부하게 전달할 수 있기에,
Single image의 Resolution 한계를 극복함으로써 더욱 현실적인 Task에 적합하다.
허나, "GPT-4o", "GPT-4-Turbo", "Gemini-Pro" 등의
Multi-modal (Vision, Language) LLM's의 성능을 측정하는 기존 벤치마크는
Single-image task가 대부분이고, Multiple Image input에 대한 총체적인 이해를 요구하는 task는 부족하기에,
Single-image task에서는 우월한 성능을 보이는 기존 VLM 들은
아직 다양한 현실적 Task를 총체적으로 해결하는 능력이 부족하다.
"Mantis-Eval", "BLINK" 등의 최근 벤치마크의 경우 Multi-image input을 포함하기 시작하였지만
'3D Scene에 대한 multi-persectives', '이미지 간의 multi-relations' 등
모델의 Multi-image input에 대한 comprehensive capability를 평가하는데 중요한 점들이 고려되지 않았다.
이에 본 논문은
Mutimodal (Vision, Language) LLMs 의
Multi-Image input에 대한 Robust capability를 검증하고자,
Comprehensive Benchmark로서
MUlti-Image-undeRstanding BENCHmark (MUIR-BENCH) 를 제시하였다.

위 이미지에서도 설명되었듯이, MUIRBENCH는
"3D Scene Understanding", "Image Ordering" 등
12개의 다양한 Multi-image tasks에 대한,
Multi-modal LLMs' robust capability를 검증하기 위해,
정량적 평가를 진행할 수 있는, 객관식 (Multi-Choice) 벤치마크를 설계하였고,
이에, 11,264개의 images를 활용하는 2,600개의 multiple choice questions 를 포함한다.
연구진은, "Multi-view", "Temporal-relations" 등 10개의 Multi-image relations를 포함하는 포괄적인 이미지셋으로부터 Tasks를 구성함으로써
Comprehensive Benchmark를 설계하고자 하였다.
또한, 현실 세계 문제들에 대한 Multi-modal LLMs' robust capability를 검증하고자,
벤치마크의 1,300개 standard instance에 대해,
각각 minimal semantic differences를 가함으로써,
expert-annotated unanswerable counterpart를 또한 생성함으로써,
pairwise manner로 도합 2,600개의 Multiple-choice questions를 설계하였다.
Unanswerable counterpart를 생성한 3가지 주 전략은 다음과 같다.

이렇게 설계된 Comprehensive, Robust Benchmark를 토대로
연구진은 20개의 recent multi-modal LLMs의 성능을 측정하였고
이에, Multi-image understanding에 있어서 SOTA인 GPT-4o와 Gemini Pro 등의 모델도
MUIRBENCH에 대해서, 낮은 성능을 기록하는 것을 확인하였다.
GPT-4o 는 68.0%의 Accuracy, Gemini Pro 는 49.3%의 Overall Accuracy를 보였는데
이는 93.1%의 Human Accuracy 보다 각각 25.1%, 43.8% 낮은 수치이다.
Mantis, Idefics, VILA, OpenFlamingo 등의 오픈 소스 모델의 경우, 훨씬 낮은 성능을 기록하였기에,
연구진은 MURIBENCH가 Multi-modal LLM's Multi-image understanding capability를 향상시킴에 있어
potential pathway를 제시함을 이야기한다.
Multi-modal LLM's capability를 측정하기 위한 기존 벤치마크와 비교하였을 때,
MUIRBENCH 가 지니는 Contribution은 다음의 이미지로 요약된다.

Multi-image input은
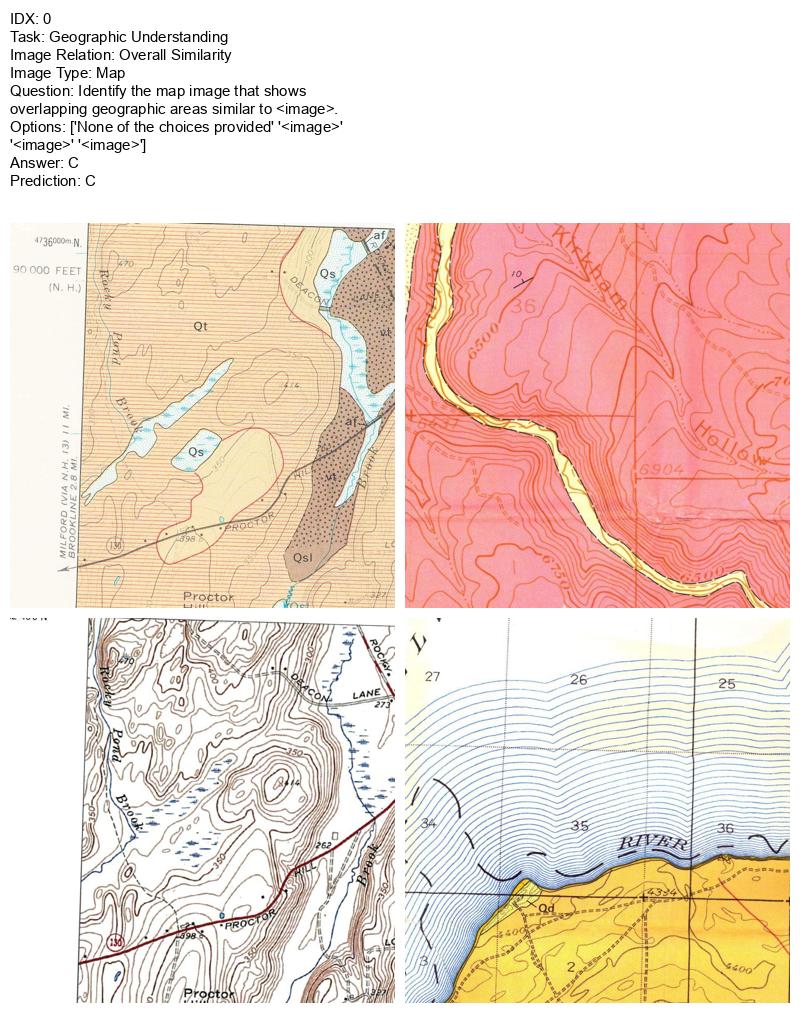
다음 이미지의 Question 항목을 통해 확인할 수 있듯이
Text instruction 상의
'Context', 'question' 혹은 'multi-choices' 로서
Interleaved format 으로 제시된다.
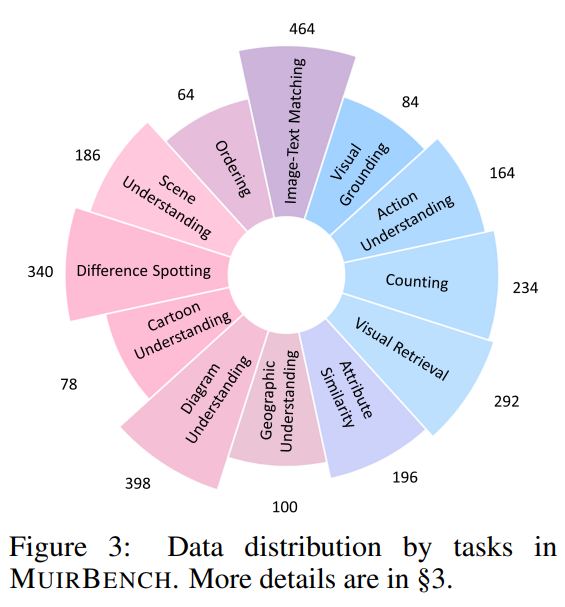
전체 2,600개 데이터셋에 대해 12개의 Tasks 분포는 다음과 같다.
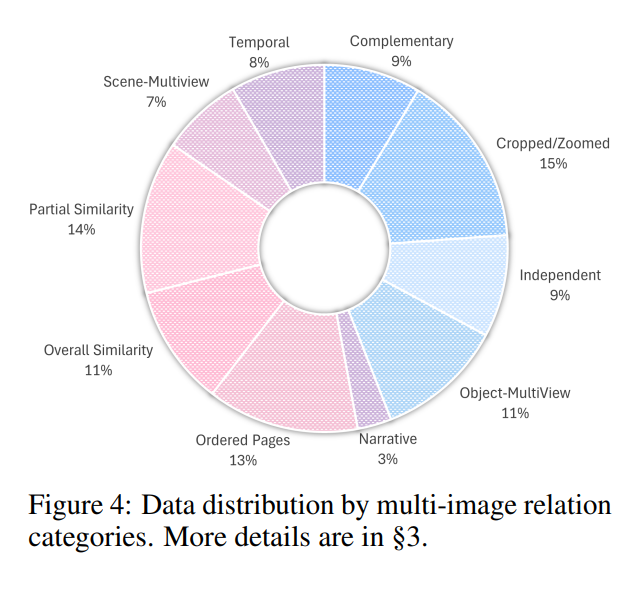
전체 2,600개 데이터셋에 대해 10개의 Multi-image relations 분포는 다음과 같다.
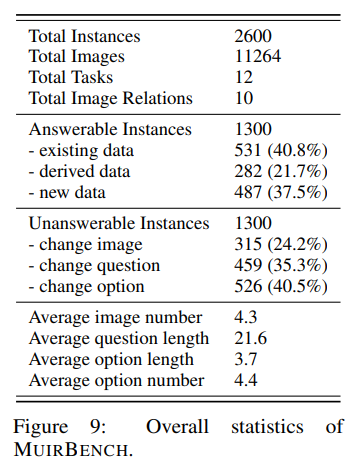
전체 2,600개 데이터셋에 대해 전반적인 통계는 다음과 같다.
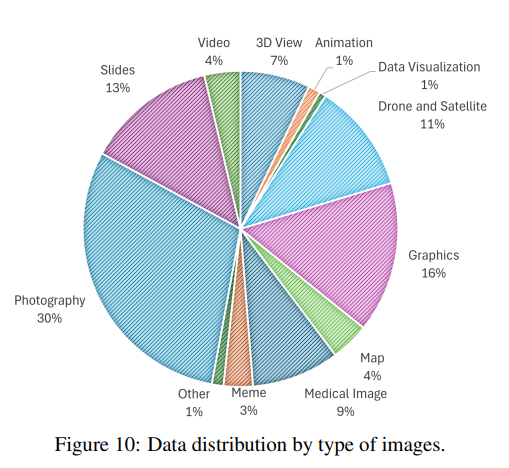
이미지 종류에 따른 분포는 다음과 같다.
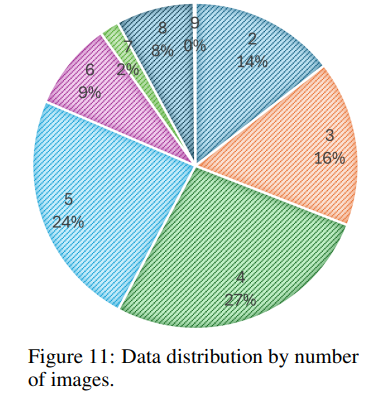
Instance 당 이미지 개수 분포는 다음과 같다.
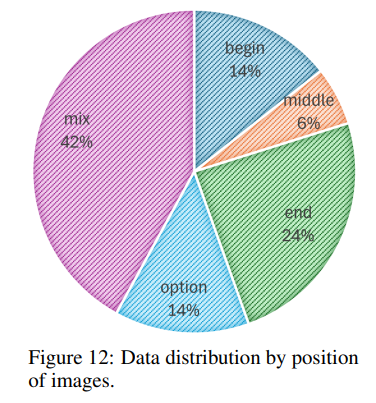
Instance에서의 이미지 위치 분포는 다음과 같다.
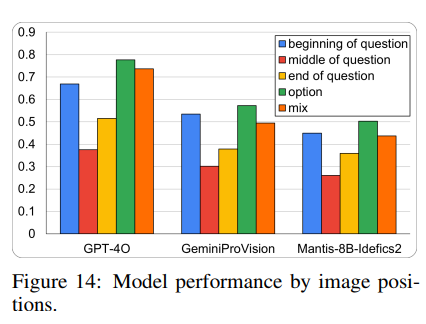
이미지 위치에 따른 모델 성능은 다음과 같다.
저자들은 아래 결과를 다음과 같이 해석한다.
- Text Instruction 상의 Image position은 Performance와 상관관계가 존재하며
- Image가 Instruction의 Middle or End 에 있을 경우, Context Flow 를 방해함에 따라, Instruction의 복잡성을 증가시킬 수 있다.
- Instruction Tuning Dataset 에 Image 가 Middle 에 Interleaved 된 형식이 부족한 것으로 추정된다.
2. Related Work
2.1. Multimodal Understanding Benchmarks
Multi-modal (Vision, Language) LLM's perception & reasoning capability를 검증하기 위해
Single Image scenario 에 대한 다양한 벤치마크가 개발되었고,
이 중 일부는, 'Comparison' 등의 Multi-image task 도 포함하지만,
Multi Image scenario 에 대한 VLMs' comprehensive capability 를 검증하는 벤치마크는 부족한 상태이다.
일부 벤치마크는 'Video-Understanding capability' 를 검증하지만, 이는 여러 Frames 간의 시간적 연속성을 포착하는데 더욱 집중하고, 몇몇 벤치마크는 'Few-shot example에 따른 in-context learning capability'를 검증하지만,
이는 multiple visual sources로부터의 다양한 시각적 정보를 기반으로 학습하는 인간의 능력이 VLM에도 있는지 검증하고자
'Varied Perspecives', 'Varied Moments' 에 따른 '시,공간적' 총체적 이해를 평가하는 'Multi-image' 벤치마크와는 다소 다르다.
최근, 'multi-image' input 에 기반한 'Size perception', 'weight comparison' 등의 task 를 수행하는
MANTIS-Eval 벤치마크 등이 개발되었지만 human-annotated 207 examples 만을 포함하기에,
다양한 'Multi-image tasks', 'Multi-image relations' 를 포함하는 벤치마크는 부족한 상태이다.
2.2. Multimodal Large Language Models
추론 능력이 대폭 향상된 LLM을 기반으로, Visual modality 또한 처리할 수 있는
다양한 VLM 파이프라인이 설계되었고, 이러한 모델들을
'MMC4', 'OBELICS' 등의 interleaved image-text corpus 를 기반으로 Pre-training,
'Mantis-Instruct' 등의 interleaved image-text corpus 를 기반으로 instruction tuning 함으로써,
'GPT-4-Turbo', 'Mantis', 'Flamingo', 'Idefics', 'Emu', 'VILA' 등의 일부 모델은
Multi-image input 에 기반한 'Counting', 'Comparison' capabilities 보여주었지만
현실 세계 속 다양한 Multi-image tasks 에 대한 VLM의 성능은 아직 뒤쳐진 상태이다.
3. MUIRBENCH
3.1. Benchmark Overview
11,264 개의 이미지에 기반하여 설계됨으로써 평균 4.3개의 이미지를 포함하는
2,600개의 Multiple-choice question 으로 구성된 MUIRBENCH 를 설계함에 있어
저자들은, 10개의 서로 다른 multi-image relation에 기반하여 12 개의 Multi-image tasks를 구축함으로써,
Comprehensive 벤치마크를 구축하고자 하였고
각각의 standard answerable instance 로부터,
'Context', 'Question' 혹은 'Choices'에 대해 minimal semantic difference 를 가함으로써
unanswerable counterpart 를 또한 설계하는 pairwise 방식으로
VLM 이 간단한 추론으로는 답변하기 힘든 Robust 벤치마크를 구축하고자 하였다.
3.1.1. Comprehensive Evaluation
전체 2,600개 데이터셋에 대해 12개의 Tasks 분포는 다음과 같다.
12개의 Multi-image tasks 각각에 대한 예시는 다음과 같다.

각 Task 한 줄 설명
[ACTION UNDERSTANDING]:
understand continuous images in chronological order and match it with an action.
[ATTRIBUTE SIMILARITY]:
identify a specific given attribute among multiple images.
[DIFFERENCE SPOTTING]:
identify differences across multiple images.
[CARTOON UNDERSTANDING]:
understand stories conveyed in cartoon images.
[COUNTING]:
count the number of specific objects across multiple images.
[DIAGRAM UNDERSTANDING]:
understand information conveyed in diagram images.
[GEOGRAPHIC UNDERSTANDING]:
understand maps and reason upon geographic features.
[IMAGE-TEXT MATCHING]:
understand the meaning of a text snippet and match it with the corresponding visual content or vice versa.
[ORDERING]:
order a series of images based on the textual description.
[SCENE UNDERSTANDING]:
understand a scene comprised of multiple views from multiple surveillance images.
[VISUAL GROUNDING]:
ground a specific object and seek information about it within multiple images.
[VISUAL RETRIEVAL]:
retrieval images that contain the same building.
전체 2,600개 데이터셋에 대해 10개의 Multi-image relations 분포는 다음과 같다.
각 Multi-image Relation 한 줄 설명
Temporal Relation:
Images are related by time, showing progression or change over a period.
Examples include time-lapse photography or sequential frames from a video.
Ordered Pages:
Images are part of a sequence, such as pages in a book or slides in a
presentation, where the order conveys meaning.
Complementary Relation:
Images that, when viewed together, provide additional information
or context that enhances the understanding of the subject. They complement each other by filling in gaps or providing different perspectives.
Cropped/Zoomed Images:
One image is a zoomed-in or cropped version of another, focusing
on a specific part of the original image to highlight details.
Narrative:
A series of images that together tell a story or convey a sequence of events, much
like a comic strip or a storyboard.
Scene-Multiview:
Multiple images of the same scene taken from different angles or perspectives, providing a more comprehensive view of the scene.
Object-Multiview:
Images of the same object captured from various angles or perspectives, useful for understanding the object’s three-dimensional shape.
Overall Similarity:
Images that are generally similar in content, style, or subject matter, but not necessarily identical. They might share common themes or visual elements.
Partial Similarity:
Images that share some, but not all, elements. They might have overlapping features or subjects but also contain distinct differences.
Independent Images:
Images that do not have a clear relation to each other. They are not connected by time, sequence, context, or content
각 Instance는 two to nine 이미지들을 포함하며
input text instruction 상에서 각 이미지의 position은
'beginning of question', 'middle of question', 'end of question',
'options', 'mix of these positions' 등 다양하게 구성된다.
각 Image type 은,
slides, maps, medical images, drone/satellite images, animations, memes, graphics, 3D views 등 다양하게 구성된다.
저자들은 이러한 Data diversity가 MUIRBENCH's comprehensiveness 를 향상시킨다고 이야기한다.
3.1.2. Robust Evaluation
Real-world multi-vision tasks 의 경우, user queries 가 항상 answerable 한 것은 아니기에
Reliable multi-modal LLM 은 user query 가 unanswerable 할 때,
가장 그럴듯한 답변을 제시하기보다는, 주어진 query가 unanswerable 함을 명시해야 한다.
이에 저자들은 unansweralb real-world scenarios 를 simulate 하고자,
standard answerable instance에 대해 다음의 변형 등을 가함으로써,
realistic unanswerable counterpart를 설계하였다.
- image replacing or reordering
- question modification
- option modification
3.2. Data Collection
3.2.1. Answerable Data Collection
다양한 데이터 분포는 fine-grained and diagnostic evaluation 을 가능하게 하고
객관식 답변은 Quantitative analysis 를 가능하게 하기에
저자들은 multi-image 를 Input 받는 Comprehensive multiple-choice question answering (MCQA) data 를 수집하고자 하였다.
이를 위해 우선 1,300 개의 Standard answerable instance 중
40.8% 를 'GeneCIS', 'SeedBench', 'IconQA' 등의 Existing data로부터 수집하였고
'Question generation', 'Option rewriting', 'Single-image QA combination' 등 다양한 전략을 취해
'NLVR2', 'HallusionBench', 'ISVQA', 'MMBench' 등의 Existing data를 MCQA 형식으로 변환하여,
21.7% 의 Derived data 를 구축하였고
'geographic understanding', 'visual retrieval' 과 같이, 앞선 데이터에서는 그 수가 부족하였던 Tasks 에 대해
1,300개의 instance 중 37.5% 에 해당하는 New data를 구축하였다.
이 때, 'National Geologic Map Database', 'University-1652', 'PubMed papers', 'SciDuet slides' 등의
dataset을 활용하였고, 저자들이 직접 question 과 choices 를 설계하였다.
HistoricalMap requires identifying map patches covering the same
regions collected from the National Geologic Map Database.
UnivBuilding requires identifying different views of the same building, or buildings from the same universities. The image data are from University-1652.
PubMedMQA contains questions regarding the subfigures from medical papers on PubMed.
SciSlides consists of questions regarding the slides for paper presentation
collected from SciDuet
New data 의 Annotation 은 다음과 같이 진행되었다.

3.2.2. Unanswerable Data Collection
1,300 개의 Unanswerable Counterpart 중
24.2% 는 'image replacing or reordering' 로 구축하였고
35.3% 는 'question modification' 로 구축하였고
40.5% 는 'option modification' 로 구축하였다.
각 answerable instance 에 대해 저자들은 위 세 가지 전략 중, 한 가지를 적용하였다.
➡️ This step doubles the size of data
➡️ balanced distribution of answerable and unanswerable instances.
3.2.3. Quality Control
Two types of quality Control
Automatic check with predefined rules:
verifies
- valid instance format
- answers
- metadata values,
- the coreference between image placeholders and images (ensuring no redundant image),
- the accessibility of images.
Manual examination of each instance to filter out low-quality data:
conducted by four experts working in this field, and filters out
- ambiguous queries
- unclear images
- confusing instances.
➡️ resulting in the retention of 86.3% of instances.
4. Experiments
4.1. Experimental Setup
Multimodal LLMs
저자들은 MURIBENCH 를 20 recent multimodal LLMs 에 적용하였고,
해당 VLMs 에는,
Multi-image input 을 고려한 모델들도 있고,
Single-image input 만을 위해 설계된 모델들도 있다.Multi-image input multimodal LLMs:
- GPT-4o
- GPT-4-Turbo
- Gemini Pro (Gemini 1.0 Pro Vision)
- Mantis (Idefics2, clip-llama3, and siglip-llama3 versions; 8B)
- VILA (v1.5-13B)
- Idefics (9B-Instruct and v2-8B)
- Emu2 (Chat)
- OpenFlamingo (v2-9B)
Single-image input multimodal LLMs:
- LLaVA (v1.5, NeXT, internLM, and xtuner versions, model size 7B, 13B, and 34B)
- Yi-VL-6B
- MiniGPT-4-v2
- CogVLM
4.1.2. Evaluation setup
Standard setup as it is in VLMEvalKit:
temperature is set to 0
retry is set to 10
Single-image input 만을 위해 설계된 multimodal LLMs 의 경우
각 Instance 의 Multiple Images 를 하나의 Input Image 로 concatenate.
4.2. Main Results
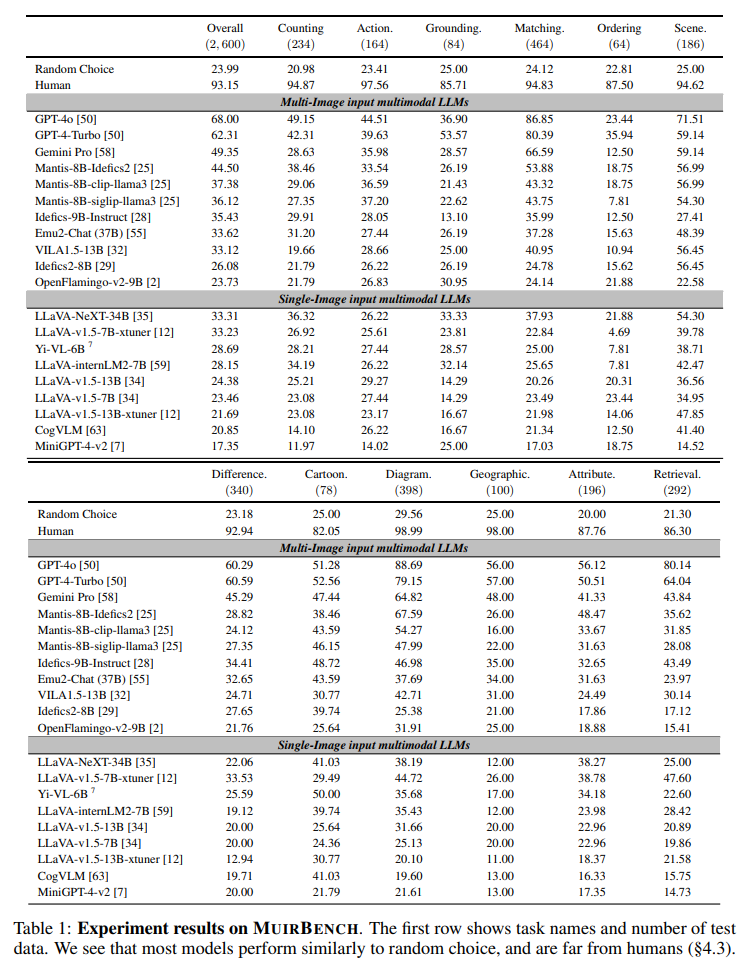
4.2.1. Overall performance
- SOTA VLM 로서의 GPT-4o 가 68% 달성
➡️ still far from HUMAN (93.15%)
- Mantis, Idefics, Emu, VILA, OpenFlamingo 등 Multi-image input 을 고려하여 설계된 Opensource VLM 들은 between 23.73% and 44.50%
➡️ fall behind from advanced proprietary LLMs
- no obvious correlation between model sizes and performances
➡️ importance of training data and training processes for multi-image understanding
4.2.2. In which multi-image tasks do multimodal LLMs show relative strengths and weaknesses?
- relatively better on
image-text matching, visual retrieval, and diagram understanding- appear to be more challenging
multi-image ordering and visual grounding
➡️ require understanding the whole multi-image context
➡️ require conducting more complicated reasoning processes across images and modalities
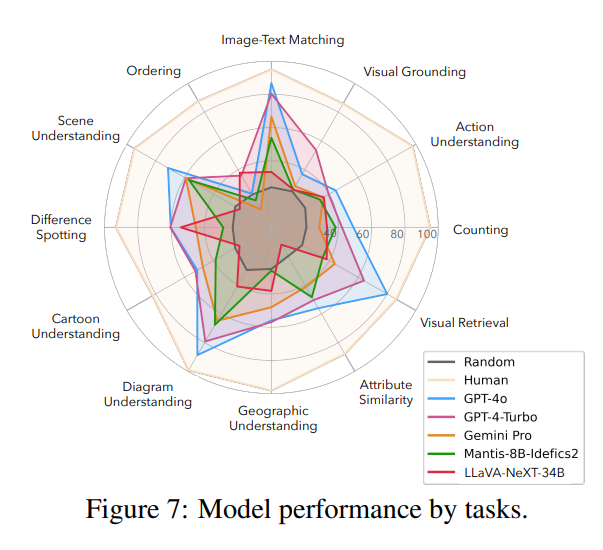
4.2.3. Can models designed for single-image inputs perform multi-image tasks?
In general, models accepting multi-image inputs(e.g., Mantis-8B), even with fewer parameters,
perform better than single image input multimodal LLMs (e.g., LLaVA-NeXT-34B).➡️ generalizing from single-image training to multi-image inference is non-trivial.
➡️ multi-image training data and learning processes matters❗
4.3. Analysis
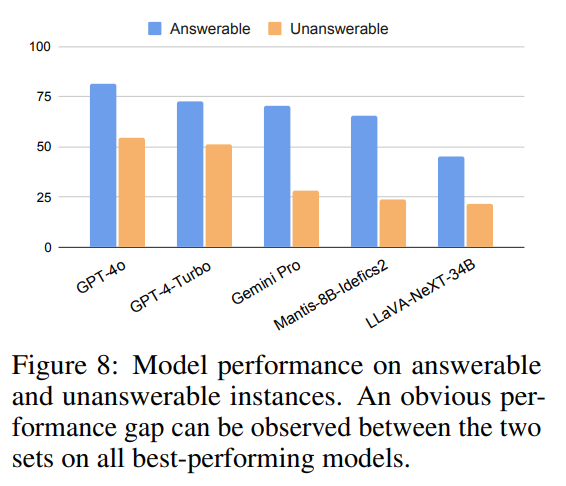
4.3.1.Do multimodal LLMs perform worse on the unanswerable set?
Severe performance drop when changing answerable instances to unanswerable counterparts
Models often avoid abstention when facing unanswerable questions.
➡️ pairwise design improves the reliability of MUIRBENCH.
➡️ importance of assessing model behavior under a more realistic setting
4.3.2. Error analysis of GPT-4o
Randomly sampled 100 error instances made by GPT-4o
- failure of capturing details in images: 26%
- inaccurate object counting or reasoning: 20%
- errors in logical reasoning: 18%
- errors in identification of the same object in different scenes : 14%
- errors in inferring the intents implied by image sequences: 12%
4.4. Qualitative Results
5. Conclusion
MUIRBENCH
- A comprehensive benchmark designed to provide a robust evaluation
on the multi-image understanding capabilities of multimodal LLMs.
- Experimental results of 20 multimodal LLMs (e.g., GPT-4, Gemini Pro)
revealed substantial limitations in their ability to handle multi-image scenarios
- Significant performance deficits compared to human accuracy
and struggled more with unanswerable questions in MUIRBENCH.➡️ Realistic Multi-image Understanding 부족 ❗❗
Limitations
- 저자들은 MUIRBENCH 가 2D Images 에 집중함으로써, 3D 관련 Tasks 은 부족하다고 언급하기에
➡️ 이와 관련된 'Multi-image relations', 'Multi-image tasks' 를 추가함으로써
➡️ VLMs' 3D Reasoning Capability 를 이끌어낼 수 있다고 생각한다.- "Image replacing or reordering", "Question modification", "Option modification"
3가지 전략을 통해, Unanswerable counterparts 를 생성함으로써,
MUIRBENCH 는 VLM 들의 현실 세계 속 Realistic Tasks 에 대한 Robustness 를 측정하고자 했지만,
➡️ 더욱 다양한 방식으로 Robustness 를 측정할 필요가 있다고 생각한다.- All the instances are in English and could induce bias on multilingual research settings
➡️ 다국어 벤치마크의 필요성
