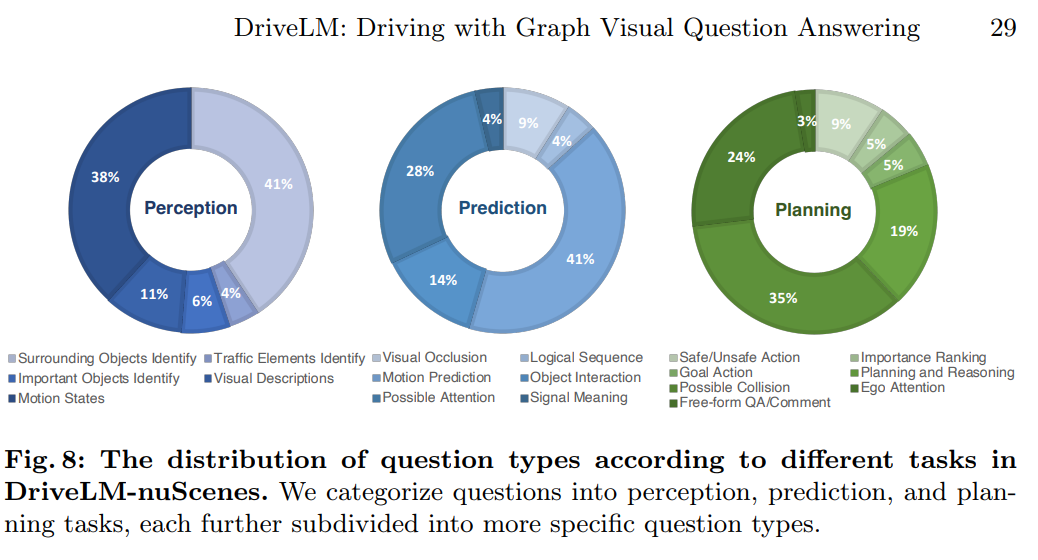
1. Overview
Web scale Text & Image 데이터에 기반한 추론 방식을 학습함에 따라,
Task-Generalization과 Human-Interativity, Reasoning 이 뛰어난 VLM 을
자율주행 분야에 적용하고자 하는 연구가 활발히 진행되고 있다.
Task-Generalization 은,
무단횡단, 폭설 등의 Unscene Scenarios 에 대응하기 위해 중요하고
Human Interactivity 는,
주행 중에, 사람과 자동차가 Language Modality 로 실시간 소통하기 위해 중요하며
Reasoning 은,
Object-Perception > Object-Movement-Prediction > Ego-Vehicle-Planning > Behavior-Decision > Trajectory-Decision
등의 Object-Centric 추론을 통해, 운전을 해나가는 인간에게 설명가능성과 신뢰성 을 제공하기 위해 중요하다.
다수의 기존 연구들이 Single-Round VQA 를 통해 VLM 을 자율주행에 적용하고자 한 것과 달리,
인간은
- Localization of key objects
- Estimation of object-interactions
- Planning Actions
등의 Multiple-steps 를 통해 Driving Actions 를 결정해나가기에,
저자들은
- Perception (Key objects Identifiaction and Localization)
- Prediction (Possible movements of Objects)
- Planning (Ego-car movement)
- Behavior (바로 취할 행동)
- Motion (Trajactory 예측)
위의 추론 단계를 통해 인간의 추론 과정을 모방하고자 하였고,
이에, 각 단계에 대한 VQA 를 생성한 이후
Vertices 와 Edges 로 구성된
Directed Acyclic Graph (DAG) 의 형태로 각 단계의 질문들을 연결하였다.
저자들은 이를,
Graph-structured-Visual-Question-Answering (GVQA) 라고 명칭하였고,
DAG 를 통해, 인간 추론 과정에서의 Logical Dependencies 를 모방한 것을
Contribution 이라 주장한다.
이를 기반으로 단일 이미지 기반 자율주행을 위한
- GVQA Task (Benchmark),
- GVQA Dataset (DriveLM-nuScenes, DriveLM-CARLA)
- GVQA 로 학습한 VLM Baseline, 'DriveLM-Agent' (BLIP-2 활용)
3가지를 제시하였다.
Dataset, Benchmark 생성
각 VQA 는 nuScenes Dataset 과 CARLA Simulator 에서 추출한 Dataset 을 기반으로
각 Frame 단일 Image와, Frame Image에 대한 GT Data (3D Bounding boxes 등) 를 활용함으로써
Human annotator, Pre-defined Rules, GPT-3.5 등을 통해 생성되었고,
Multi-round Quality Check 을 거쳤다고 주장한다.
[로직]DriveLM-Agent's Trajectory-Tokenizer
기존 VLM 이 아키텍처 수정 없이, Fine-Grained Numerical Trajectory 를 출력할 수 있게끔 한다.
이는 RT-2 논문 (https://arxiv.org/pdf/2307.15818) 에서 Robotic action을 다루고자 제시된,
Vision-Language Action 모델의 방식으로,
3D 공간 상의 Continuous Traectory 에 대한 Discretization, Tokenization 을 수반한다.
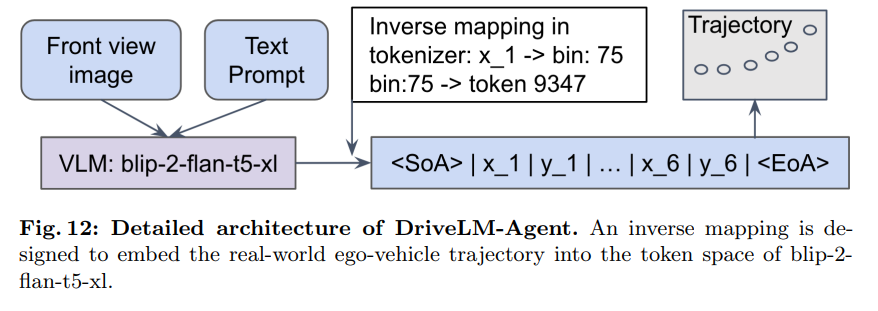
- nuScenes Training Dataset 에서의 Future Trajectory 분포 분석
- 분포 기반 각 좌표 축을 256 개의 Discrete Interval 로 분할
(Continuous (x, y) waypoint space ➡️ Discrete waypoint Space)
(256 개는 LOD 와 Token-Managability 과 균형을 위한 Hyperparameter)
We re-define tokens in the BLIP-2 language tokenizer,
establishing tokens for each bin (Discrete interval), and fine-tune the VLM on the redefined vocabulary
- 각 Discretized bin 을 LLM vocabulary 상의 Unique Token 으로 사전 매핑
- Trajectory Sequence 의 시작과 끝을 나타내기 위한
SOT (Start Of Trajectory), EOT (End Of Trajectory) Special Token 사전 정의 - Image Input 과 Behavior 관련 Text Input 이 DriveLM-Agent로 들어왔을 때,
LLM Vocabulary 상의 Trajectory Token을 활용하여,
Text Token 을 생성하듯, Discretized Numerical Trajectory Token 또한 출력 가능해짐. - Diecretized output Trajectory Tokens을 다시 연속적 Coordinate space 로 Decoding 하는 관계를 설정함으로써
Numerical Trajectory 생성 가능 (Motion Planning) - 이후, Motion Planning 에 대한 VQA Dataset 으로 Fine-Tuning 함으로써, Trajectory Planning Task 에 활용 가능.
정리하자면,
- 연속적 좌표 공간 ➡️ 이산적 좌표 공간, 매핑
- Tokenizer Vocabulary 재정의
- 이산적 좌표 공간 ➡️ 연속적 좌표 공간, 매핑
- Trajectory Planning VQA Dataset 기반 Fine Tuning
위 과정을 통해 기존 VLM 을 아키텍처 수정 없이, VLA (Vision-Language-Action) 모델로 활용 가능.
Dataset, Models, Evaluation Server 는 모두 공개된 상태이다.
DriveLM: https://github.com/OpenDriveLab/DriveLM
2. Related Work
Generalization in Autonomous Driving
주행 환경에서, 도로에 사람이 갑자기 나타나거나, 전봇대가 무너지는 등의 Edge case 에도 일반화하고자
기존 자율 주행 알고리즘은 Simulation 을 통해 Edge case 에 대한 Data 를 늘리는 Data-Driven Method 를 취하지만
Generalization Capabilty 는 근본적으로 향상되지 않기에,
Semantic Information 을 활용하는 접근 법이 등장하였지만, Zero-Shot 성능이 대폭 향상되지는 않고 있기에,
VLM 의 단계적 추론 (일반화) 능력을 자율주행에도 활용하고자 하는 연구가 진행되고 있다.
Language-grounded Driving
GPT-Driver, LLM-Driver 등의 모델은 Scene state 를 Text Prompt 로 encoding 함으로써
LLM 의 Reasoning Capability 를 자율 주행에 활용하고자 하였고,
DriveGPT4 는 Raw-Sensor-Data 까지 토큰화하여 전달하기도 했지만,
Multi-Modal Input 에 기반하여 Multi-step 으로 단계적 추론을 진행하고자
VLM의 Generalization Capabiity 를 극대화하는 연구는 부재하였음을 언급한다.
3. DriveLM: Task, Data, Metrics
3.1. DriveLM-Task (GVQA)
nuScenes, CARLA 로부터 추출한 각 이미지 프레임에 대한 Q & A 쌍을 Node 로,
Q&A Node 간의 Logical Dependecy 를 Edge 로 활용함으로써,
전체 VQA Dataset 은 Directed Acyclic Graph 형태로 구조화된다.
이 때 Edge (Logical Dependency) 는 Object-level 과 Task-level 로 나뉜다.
Object-level Q&A Dependency:
객체 간에 끼치는 영향을 표현한다.
Task-level Q&A Dependency:
여기서 Task 는 서로 다른 Multi-reasoning-stage 를 의미한다.
- Perception: identification, description, and localization of key objects in the current scene.
- Prediction: estimation of possible action/interaction of key objects based on perception results.
- Planning: possible safe actions of the ego vehicle
- Behavior: classification of driving decision.
- Motion: waypoints of ego vehicle future trajectory.
: Perception
: Prediction
: Planning
Motion Task 의 Output 은, 앞서 설명한 Trajectory-Tokenizer Method 에 기반하여,
Bird's-eye-view (BEV) 상에서의 N 개의 (x,y) 좌표에 해당한다.
이 때 각 좌표는, Fixed Time Interval 마다의, Future Position 과 Current Position 과의 Offset 을 의미한다고 저자들이 이야하기에,
현재 Ego-Vehicle 의 BEV 좌표를 원점으로 설정한 듯 하다.
Behavior Question 에 대한 응답으로 Category 를 Output 하기 위해
다음의 식을 통해 와 를 정의한다.
(for )
(for )
이후 와 의 평균을 사전 정의된 Behavior bin 으로 매핑하는데,
이때 각 Beahavior bin 은 고유의 speed 와 steering 값을 지닌다.
정리하면, Trajectory Output 을 기반으로, 현 시점에서 취해야 할 Speed behavior과 Steering behavior 를 계산하는것인데,
이를 와 로 표현하고, 각각은 다음의 카테고리를 지닌다.
마지막으로 정리하자면,
Motion Task 의 Trajectory Output 을 기반으로 Speed 와 Steering Output 즉, Ego-Vehicle 을 제어하기 위한 Behavior 를 결정하게 되기에,
더욱 정교한 로직을 기반으로 차선 변경, 추월 등의 추상적인 행동도 결정할 수 있을 것 같다.
3.2. DriveLM-Data
Perception ➡️ Prediction ➡️ Planning ➡️ Motion ➡️ Behavior (Catogorical)
위와 같이 이어지는 Logical Dependency 를 Edge 로, VQA Pair를 Vertex 로 활용함으로써,
특정 Video Frame Image 와 관련된 모든 Q&A 를 Directed Acyclic Graph 로서 표현할 수 있기에,
저자들은 Video Frame 을 두가지 데이터셋으로부터 추출하였다.
- Multi-view 자율주행 비디오 데이터셋 nuScenes
- Multi-view 자율주행 시뮬레이션을 진행할 수 있는 CARLA.
DriveLM-nuScenes

Annotation Process 는 위와 같이 3 단계로 구성된다.
- 20초 길이 1,000 개의 주행 동영상으로부터, Manually Key frame 추출
- 각 Key Frame 내에서의 Key object Manually 추출
- 각 Key Objects 에 대해, Manually 혹은 Rule-based Q&A 생성
➡️ 각 Key objects 에 대한, Perception, Prediction, Planning Q&A 생성 과정
➡️ Manually: 5 명의 해당 분야 전문가가 주관적으로, 인간의 사고 과정을 모방함
➡️ Rule-based: 각 객체에 대한 3D Bounding Box, Future Trajectory, Object Description 기반이 때, Domain Expert 가 Manually 생성하는 과정에서, 주관이 개입되기에, 엄격한 품질 평가를 진행하였다고 얘기한다.
DriveLM-CARLA
CARLA 0.9.14 에서 Leaderboard 2.0 framework 를 활용하여 데이터를 수집하였고,
새로운 Expert Algorithm 'PDM-Lite' 를 구축하여 데이터 수집에 활용하였다.
'PDM-Lite' 의 경우, CARLA Validation routes 에서 향상된 Driving Score 를 달성하였다고 이야기한다.
Urban, Residential, Rural 지역에서의 경로를 설정하였고,
PDM-Lite 알고리즘을 활용하여 경로 주행을 진행하였다.
데이터셋 생성 과정은 DriveLM-nuScenes와 유사하기에, 위 파이프라인을 통해 확인하면 될 것 같다.
다만 주목할 점은, 초기 Scenario, Route 설정을 제외하고는 모든 과정이 Automatic 하다는 것이다.
- Expert Algorithm 이 "Acceleration ➡️ Breaking" 과 같이 결정을 바꾸는 시점을 KeyFrame 으로서 추출하였고
- Static and Dynamic Objects 에 대해서, Object Status 정보를 추출하였고,
- 사전 정의된 Sentence-Template 을 활용하여, Object status 기반 Q&A 를 자동 생성하였다.
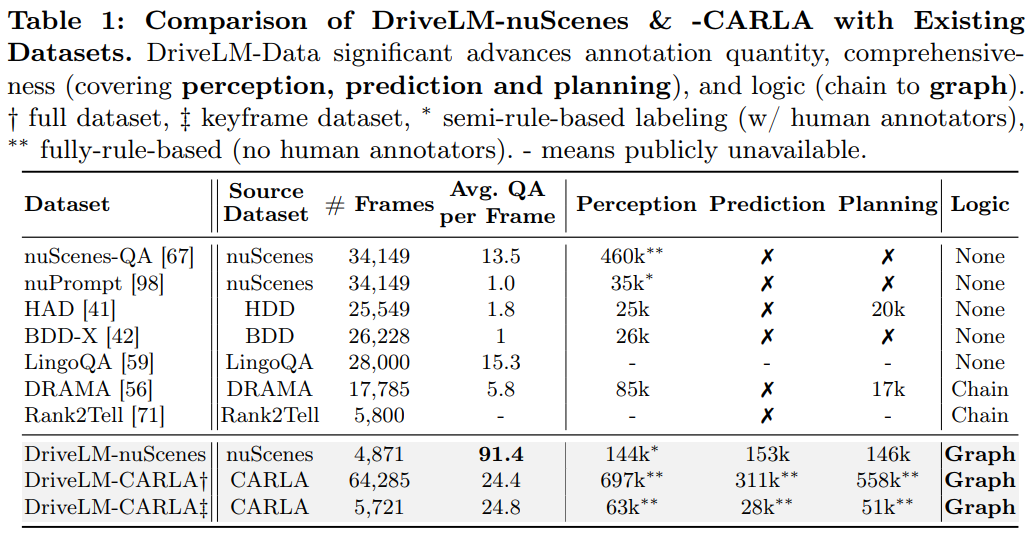
저자들은 이를 통해 1.6M QAs 를 생성하였고, 이는 다음의 표를 통해 확인할 수 있듯이,
기존 Dataset 보다 훨씬 큰 규모이다.
3.3. DriveLM-Metrics
- (Perception, Prediction, Planning)
- Behavior (Text Description)
- Motion ( Trajectory)
각 단계의 Visual Question 에 대한 Answer 의 적절성을 판단하기 위한 Metric 은 다음과 같다.
Motion (Trajectory) Metric
nuScenes and Waymmo bechmark metric:
- Average Displacement Error (X, Y coordinate)
- Final Displacement Error
UniAD metric:
- Collision Rate on the predicted trajectory
Behavior Metric
(Perception, Prediction, Planning) Metric:
2 가지 Metric 사용
- SPICE
- GPT Score
Spice:
VQA 와 Image-Captioning 등에서 널리 사용되는 방식으로
GT Text 와 Predicted Text 간의 구조적 유사성만을 측정하고
Semantic Meaning 은 고려하지 않음.
GPT Score:
Spice Metric 은 구조적 유사성만을 측정하기 때문에, Semantic Meaning 을 고려하고자
ChatGPT-3.5 를 활용.
- Visual Question
- GT Answer
- Predicted Answer
- Text Prompt for asking Numerical Score (0 ~ 100)
위 4가지를 ChatGPT-3.5 에 전달하여 Semantic Meaning 에 대한 (0~100) Score 를 반환 받아, Metric 으로 활용
이에 따라, GPT-3.5 가 측정한 점수 예시는 다음과 같음.
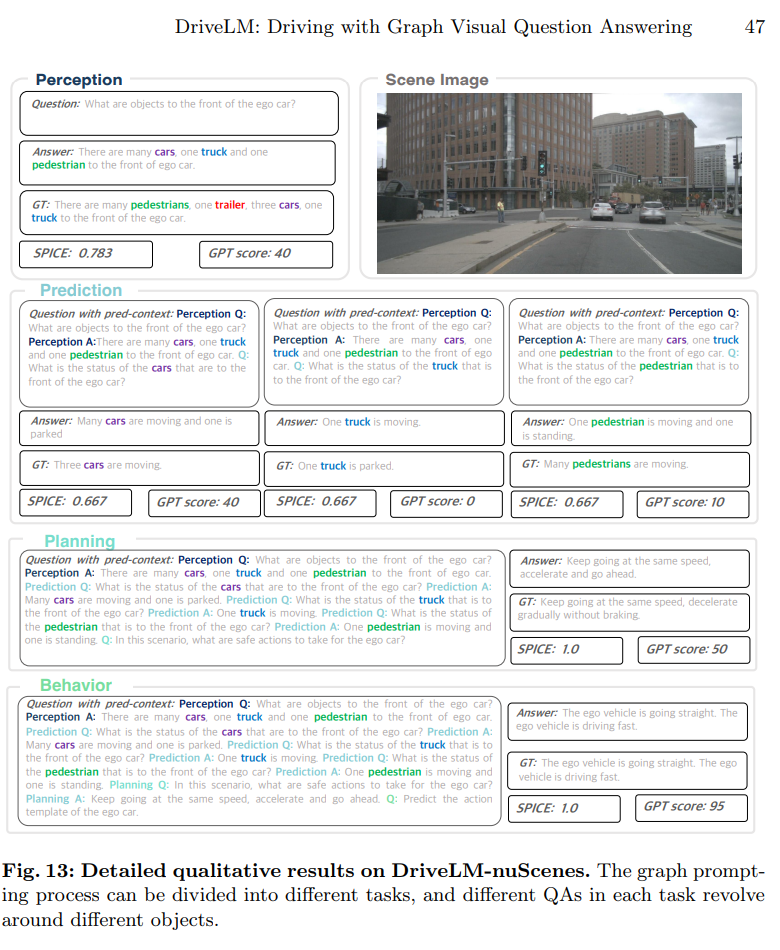
4. DriveLM-Agent: A GVQA Baseline
BLIP-2 를 Baseline VLM 로 설정한 이후,
앞서 설명한 Trajectory-Tokenizer 방식을 취하여,
Motion Trajectory 를 Output 하는 Agent 를 설계한 이후,
DriveLM-Data 로 Fine-tuning 하여
Single Image 에 대해 Object-centeric Multi-stage Reasoning 을 수행하여, Motion Trajectory 를 Output 하는
End-to-End 자율주행 VLM 아키텍처를 설계.
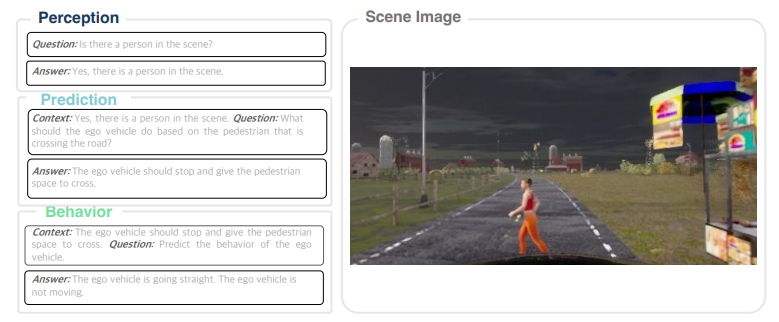
DriveLM-Agent Piepline: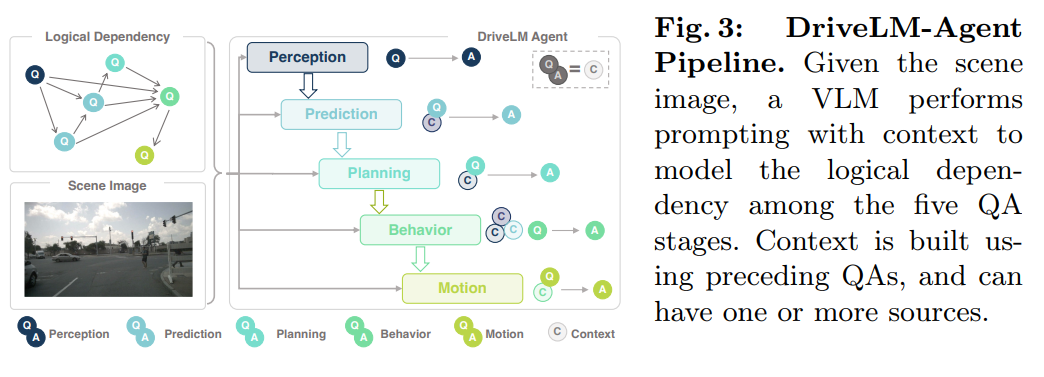 (1) : 단일 이미지를 객체 중심으로 이해하기 위한 과정
(1) : 단일 이미지를 객체 중심으로 이해하기 위한 과정
(2) Behavior: 에서의 중요 정보를 통합하여, Desired Driving Action 을 언어로서 표현
(3) Motion: 단일 이미지와 Behavior Answer 를 기반으로 실행 가능한 Driving Trajectory 를 생성.
위 파이프라인에서 확인할 수 있듯이,
각 단계에서, 이전 단계의 Text Answer 를 Context 로서 Concatenate 하는 Multi-Stage 방식을 취함.
5. Experiments
DriveLM-Agent Qualitative Resulsts:
GVQA-Effect of Context:
Behavior Description 을 생성함에 있어, 어떠한 Context 도 주지 않았을 때,
즉 Perception, Prediction, Planning 에서 생성된 정보를 Logical Reasoning 에 활용하지 않았을 때,
nuScenes Benchmark 를 가장 잘 해결함.
➡️ Logical Dependency 가 잘못 되었거나
➡️ 현재의 Context Concatenation 을 통한 CoT 방식이 잘못된 것을 추측할 수 있음
➡️ GVQA 를 Main Contribution 으로 이야기 해도 되는 것인가에 의문이 듦.DriveLM-Agent: Effect of finetuning on DriveLM-Data:
DriveLM-Data로 FineTuning 했을 때, DriveLM-nuScenes 와 DriveLM-CARLA 벤치마크에 대해, 구조적 유사도가 높아지고 의미적으로 풍부해짐을 이야기한다.
➡️ 물론, DriveLM-Data로 FineTuning 되지 않은 Baseline으로서의 BLIP-2와 차이가 많이 나긴 하지만, Fine-Tuning의 당연한 결과라고 생각한다.
➡️ 눈여겨볼 점은, CARLA Task 보다 nuScenes Task 가 더욱 어렵다는 것이고, 이에 Data 의 Realistic 함이 중요함을 유추할 수 있다.
6. Conclusion
- Perception (Key objects Identifiaction and Localization)
- Prediction (Possible movements of Objects)
- Planning (Ego-car movement)
- Behavior (바로 취할 행동)
- Motion (Trajactory 예측)
위의 추론 단계를 통해, 차량 운전자의 추론 과정을 모방하고자 하였고,
이에, 각 단계에 대한 VQA 를 생성한 이후
Vertices 와 Edges 로 구성된 Directed Acyclic Graph (DAG) 의 형태로 각 단계의 질문들을 연결하였다.저자들은 이를,
Graph-structured-Visual-Question-Answering (GVQA) 라고 명칭하였고,
DAG 를 통해, 인간 추론 과정에서의 Logical Dependencies 를 모방한 것을
Contribution 이라 주장한다.
본 논문은, 단일 이미지 기반 자율주행을 위한
- GVQA Task (Benchmark),
- GVQA Dataset (DriveLM-nuScenes, DriveLM-CARLA)
- GVQA Dataset 으로 학습한 VLM Baseline, 'DriveLM-Agent' (BLIP-2 활용)
3가지를 제시한다.
개인적 분석
1.
저자들은
1. 한 두 문장으로 Ego-vehicle 의 운전 상황을 묘사하는 Scene-level VQA
2. 개별 객체에 대해 Ego-vehicle 이 취해야 할 행동을 묘사하는 Single-Object-Level VQA
자율 주행 관련 기존 VQA 들이 위와 같이 분류되며,
이는, Multi-object 를 기반으로 Multi-steps 로 추론하는 인간과 사뭇 다름을 이야기한다.
이에,
Perception > Prediction > Planning > Behavior > Motion
5 단계로 이어지는 Logical Reasoning 을 제시하였지만,
본인은 해당 Logical Dependency 가 적합하지 않은 것 같음.
❓
각 단계에 대한 경계가 모호하고,
다음 단계로 이전 단계의 불필요한 Q&A 가 Context 로 전달됨에 따라
판단을 흐릴 수 있다는 생각을 함.
Multi-Objects, Single Scene description 과 같은 핵심 정보만
Context 로서 전달하는 것이 낫지 않을까?
➡️
Logical Dependency 를 다르게 구조화할 필요가 있음
(Perception (Object, Scene) -> Motion Reasoning -> Trajactory)
2.
Trajectory-Tokenizer 의 다음 과정을
- 연속적 좌표 공간 ➡️ 이산적 좌표 공간, 매핑
- Tokenizer Vocabulary 재정의
- 이산적 좌표 공간 ➡️ 연속적 좌표 공간, 매핑
- Trajectory Planning VQA Dataset 기반 Fine Tuning
VLM 의 Bounding Box 기반 CoT 공간적 추론에 활용할 수 있을 것 같음.
중요 객체에 대한 Numercial Bounding Boxes 를 1차적으로 출력하고
이를 기반으로, CoT 추론을 거쳐, 공간적 상황을 정확히 인식하게끔 할 수 있을 듯.
3.
DriveLM-CARLA Annotation Pipeline
➡️ 더욱 Realistic 한 Simulator 에서
➡️ 더욱 Realistic 한 Scenario 를 기반으로
➡️ 더욱 Realistic 한 Route 를 설정한 이후
➡️ Multi-view Setting 을 설정하고
➡️ Keyframe 추출 로직을 변경하고
➡️ Sentence Template 또한 정교화하고
➡️ Logical Depdency 를 수정하여 (e.g, Perception > Reasoning > Trajectory > Behavior (Numeric))
Multi-view Object-Centric-Reasoning 데이터셋을 자동으로 생성하는 파이프라인을 구축할 수 있을 것 같다.
4.
DriveLM-nuScenes Annotation Pipleline
➡️ DriveLM-CARLA 와 같이 Multi-view Object-Centric-Reasoning 데이터셋을 자동으로 생성하는 파이프라인으로 확장해야 함,
5.
주관식 벤치마크 정량적 성능측정 방식
➡️ GPT Score 측정 관련 Zero shot Prompt 를, Few-shot Example 혹은 반복적 대화 등을 통해 더욱 정교화할 수 있을 것 같음
➡️ 최신 Reasoning Model 을 통해 Evaluation 의 Accuracy, Explainability 를 향상시킬 수 있을 것 같음.
➡️ SPICE, GPT Score 외에도 다른 Metric 을 추가하여, 주관식 벤치마크에 대한 정교한 평가 방식을 설계할 수 있을 것 같음.
6.
DriveLM-Agent 파이프라인 수정 관련
BLIP-2 를 Baseline VLM 로 설정
➡️ MUIRBENCH 기반 다중 이미지 VLM 으로 대체 가능 (NVILA 등)Single Image 에 대해 Object-centeric Multi-stage Reasoning 을 수행하여, Motion Trajectory 를 Output 하는 End-to-End 자율주행 VLM 아키텍처를 설계
➡️Multi Image Dataset 으로 확장 필요
➡️Reasoning Stage 수정 필요DriveLM-Agent Piepline:
각 단계에서, 이전 단계의 Text Answer 를 Context 로서 Concatenate 하는 Multi-Stage 방식을 취함.
➡️ 자율 주행 환경에서, Forward 를 여러번 진행하는 것 자체가 현실성이 부족하기에
➡️ 이전 단계의 Text answer 를 다음 단계의 Context 로서 Concatenate 하는 방식이 아닌
➡️ LLaVA-CoT 처럼 애초에 필요한 정보들에만 기반하여, Single Forward Pass 로 단계적 추론을 진행하는 모델 설계 필요
7.
Experiment Results에 관하여
CARLA Task 보다 nuScenes Task 에서 자율주행 성능이 더욱 낮게 나타남.
➡️Real World Dataset 이 중요 (nuScenes, argoverse)Perception, Prediction, Planning 에서 생성된 정보를 Logical Reasoning 에 활용하지 않았을 때,
nuScenes Benchmark 를 가장 잘 해결함.
➡️ Logical Dependency 가 잘못 되었거나
➡️ 현재의 Context Concatenation 을 통한 CoT 방식이 잘못된 것을 추측할 수 있음
8.
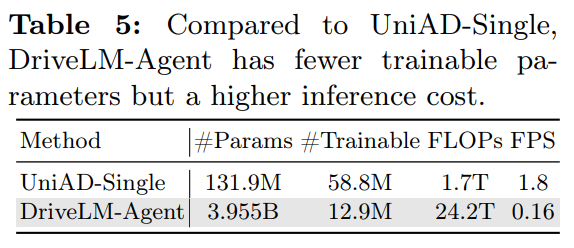
Computational Efficency
Graph structured VQA 를 통해 Multi-round Inerence 를 진행함에 따라,
기존 Driving Specific Architecture 'UniAD' 보다 대략 10배 정도 느림
➡️ LLaVA-CoT 방식에 기반하여, Single Foward Pass 로 CoT 을 수행할 수 있게, 데이터셋을 설계해야함.
9.
불필요한 Q&A 가 많다고 생각함
자세한 사항은 Supplementary 를 참고하면 됨.
➡️ Logical Dependency 를 재설계하고, 각 Logical Step 에서의 핵심 질문 또한 재설계할 필요가 있다고 생각함.