Sparse4D 선정 이유
2025.03.10 기준
nuScenes 3D Object Detection Task Leaderboard 에서
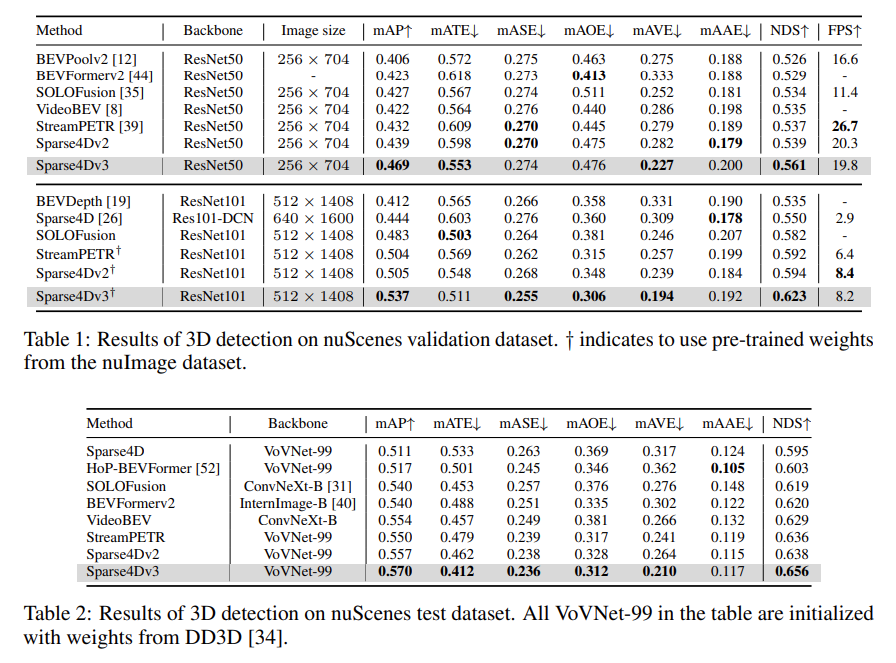
Multi-view Camera Image 만을 사용하는 모델 중, SOTA 를 기록중인 모델이다.
- mAP: mean Average Precision
- mATE: mean Average Translation Error
- mASE: mean Average Scale Error
- mAOE: mean Average Orientation Error
- mAVE: mean Average Velocity Error
- nAAE: mean Average Attiribute Error
- NDS: Nuscenes Detection Score (위 6가지 지표의 가중합)
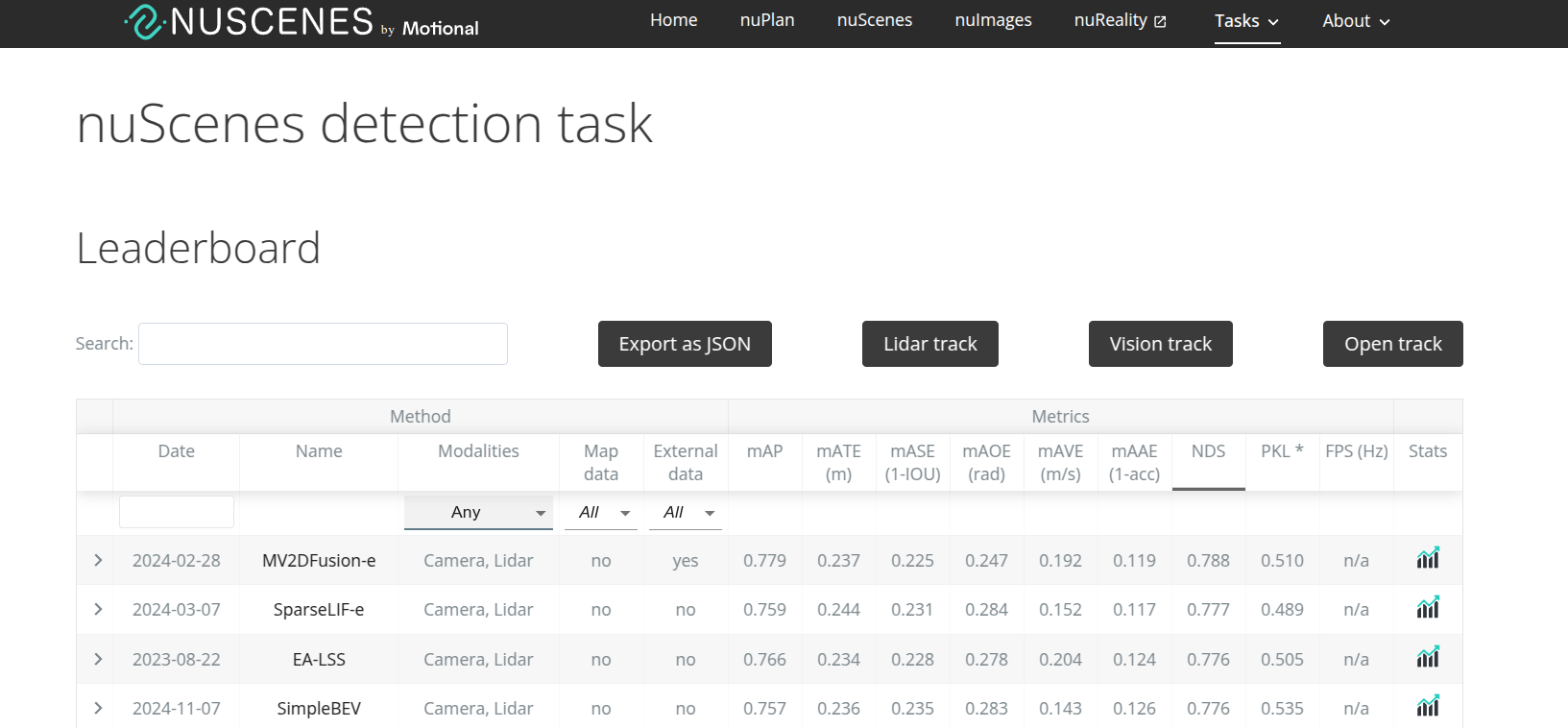
위 6가지 지표를 종합적으로 고려하였을 때, 아래 이미지와 같이
리더보드 상에서, SOTA 성능을 보여주고 있다.
물론, Sensor Modalities Column 을 필터링하지 않은 아래 이미지와 같이,
Camera 뿐만 아니라, Lidar, Rader 등도 사용하는 여타 3D Detection 모델에 비해서는,
mAP, NDS 가 다소 떨어지는 것을 확인할 수 있다.
허나, LiDAR 없이, Multi-View Camera Image 만을 활용하여,
3D Annotation 을 수행해야 하는 제한적 상황이기에,
Camera-Only 3D Annotation 에서만큼은,
최신연구가 아님에도 (23.10) SOTA 를 기록중인
Sparse4D 시리즈를 리뷰하고자 한다.

Sparse4D 시리즈
Multi-view Video 와 같이,
몇 초간의 연속된 Temporal Multi View Input 이 들어왔을 때,
3D Object Detection 을 수행하는 알고리즘은 크게 2가지로 나뉜다.
- Dense-based
Multi-view Image, LIDAR, RADER 신호를 모두 활용하여
Dense 한 Bird's Eye View 3D 공간을 구축한 뒤,
Dense 한 3D Annotation 을 후차적으로 진행하는 방식- Sparse-based
(1) Explicit 한 3D Instance (BB) Anchor,
(2) Implicit 하게 BB 에 대한 전반적 의미를 내포할 Instance Feature
2 가지를 Sparse 하게 Initialize 한 뒤,
Backbone 인코더를 활용하여 Multi-view 2D Image 로부터 Visual Feature 를 추출하고,
Refinement Decoder 에서 Instance Query 와 Image feature 를 Cross-Attention 을 통해 결합하여
Instance Anchor, Instance Feature 를 점점 Denoising 하는 방식앞서 nuScenes 리더보드에서 확인하였듯이,
Semantically Dense 한 3D BEV Space 를 구축하기 위해,
LIDAR, RADER Point Cloud 또한 활용하는 방식이,카메라 이미지만을 활용하는 Sparse-based 방식보다
3D Annotation 성능이 훨씬 뛰어나긴 하지만,실시간으로 3D Annotation 을 진행해야하는 Online 환경에서는
3D Vector Space 를 구축하지 않아도 되는
Sparse-based 방식이 계산 효율성이 더 좋긴 하다.(허나, 본인은 지금 LIDAR 를 활용하지 못하는 상황이기에,
계산효율성과는 상관없이, Camera Only Sparse based Method 를 리뷰하고 있긴 하다...)어쨌든 저자들은, 계산효율성이 더욱 좋은 Camera Only 방식으로서,
Sparse4D-v2 를 baseline으로 선정하였고,
몇 가지 변형을 취함으로써, Camera only 3D Detection 태크스에서 SOTA 를 달성중이다.
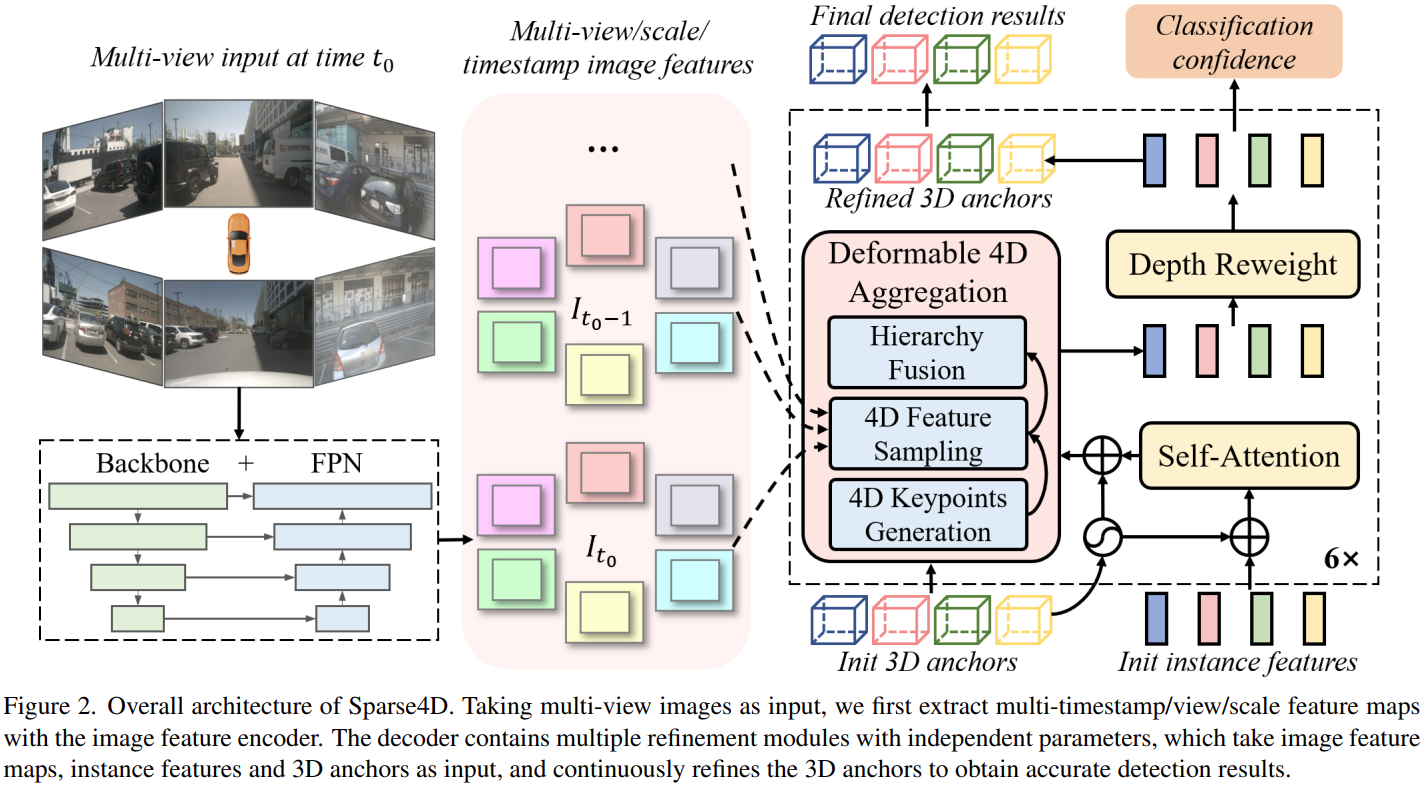
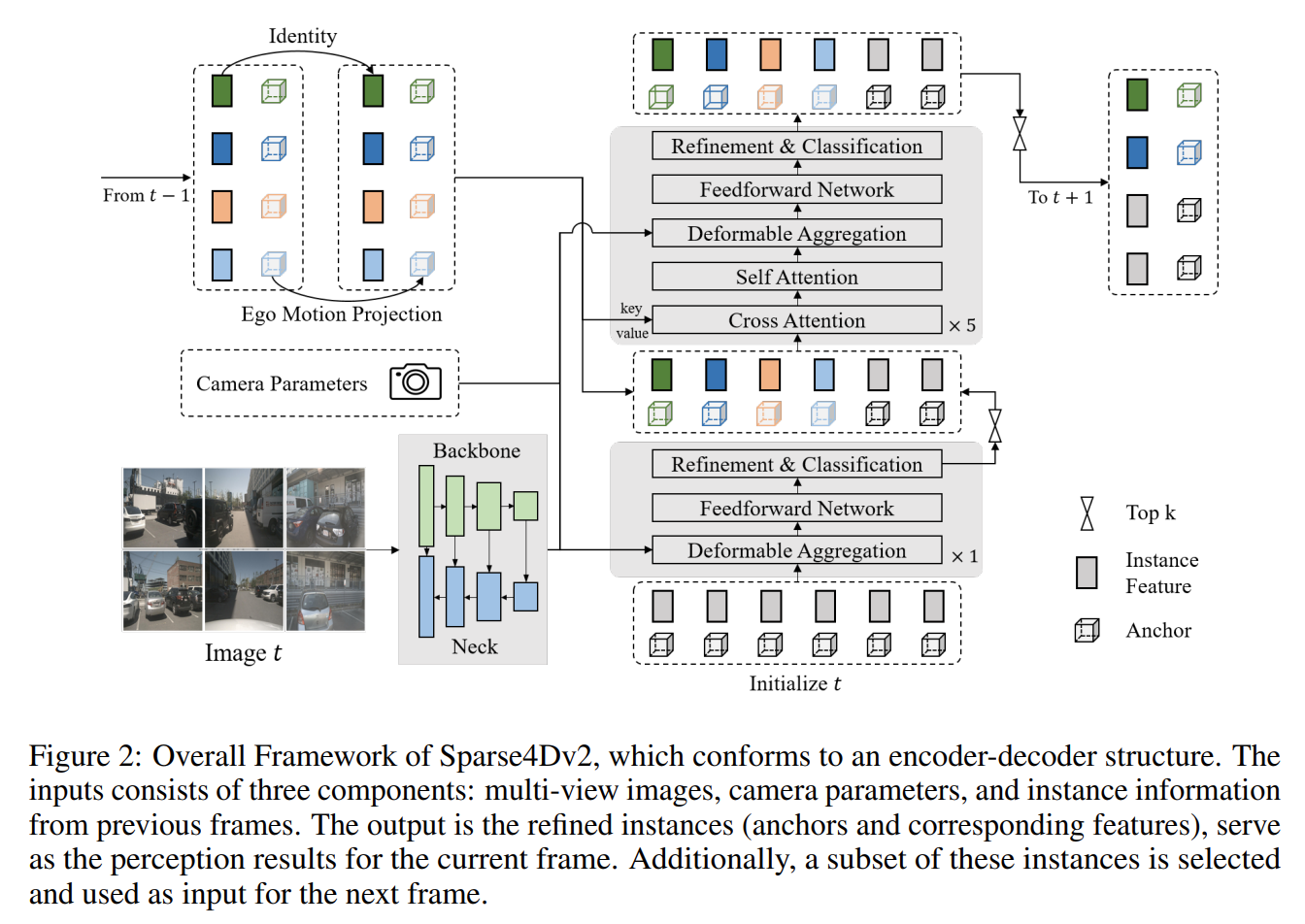
Sparse4D-v1 아키텍처는 다음과 같다.
1. Pre-trained ResNET Backbone 을 활용하여 Multi-scale Feature 를 추출한 뒤,
2. FPN 를 통해, Multi-Scale Feature 에 대해, Semantic Meaning 과 Visual Detail 을 더해줌으로써,Multi-Timestamp 의, Multi View 이미지 각각에 대해, Multi-Scale Feature 를 추출한다.
- Prediction 을 위해 점차 refinement 를 거칠, "3D Instance Anchor", "3D Instance Feature" 를 초기화한다.
3D Instance Anchor 는, Center, Size, Orientation, Velocity 를 지니고3D Instance Feature 는, 향후 BB Confidence 예측에 활용될, Implicit Vector 에 해당한다.
- 여러 Self-, Cross-Attention Layer 등으로 구성된 Decoder 가,
앞서 추출한 "2D Image Feature" 를 기반으로
"3D Instance Anchor", "Implicit Instance Feature" 를 반복적으로 정제함으로써,
3D Bounding Box Annotation 을 예측하게 된다.허나,
Dense 한 3D BEV Space 에서 GLobal Cross Attention 을 진행하는 Dense-based 방식과 달리,
Sparse4D-V1 은, Randomly Initialize한 적은 수의 3D Instance 에 상응하는 (V3 기준 900개)
Image Feature 를 Sparsely 추출한다.부족한 시각적 정보에 기반하여, Bounding Box Annotation 을 진행하기에,
Predicted Objects 의 Quantity 와 Quality 가 부족할 수 밖에 없고,
이에, LIDAR, RADER 를 모두 활용하여, 3D BEV Space 를 구축하는 Dense-based 방식보다
mAP, NDS 가 낮게 나타날 수 밖에 없다.
(Camera, Lidar 2가지를 활용하여 현재 nuScenes 리더보드에서 SOTA 를 달성 중인, MV2DFusion)
이에, Sparse4D-V2 는 Dense 한 Depth 정보를 포함함으로써,
Sparse 한 시각적 정보로 인한, Image Encoder 의 Convergence issue 를 완화하고자 하였고,
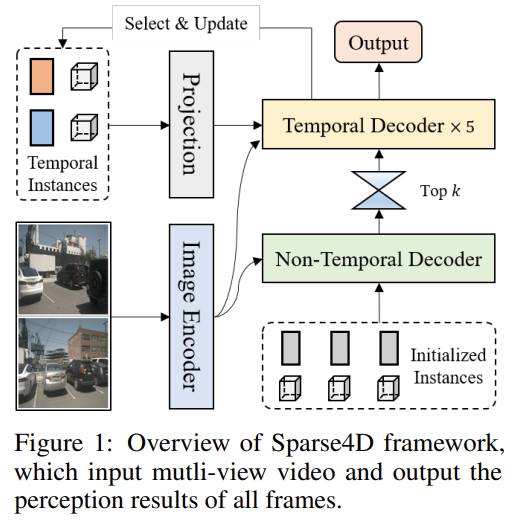
조금의 성능 향상을 달성하였다.[Multi-timestamp, Multi-view, Multi-scale] 2D Image Feature 를 기반으로
Recurrent 하게 3D Instance Annotation 을 예측 및 정제하는
전체 파이프라인은, Sparse4D-V1 과 동일하다.
Sparse4D-V3 는 앞선 V2 와는 달리,
Decoder 의 안정적인 학습을 위해
- Temporal Instance Deonising
- Quality Estimation
- Decoupled Attention
3가지 방식을 적용함으로써,
nuScenes Camera-only 3D Detection Task 에서, SOTA 를 달성 중이다.V2 를 Baseline 으로 설정하여, 추가적인 기법을 적용했을 뿐이기에,
전체적인 틀은 동일하다.
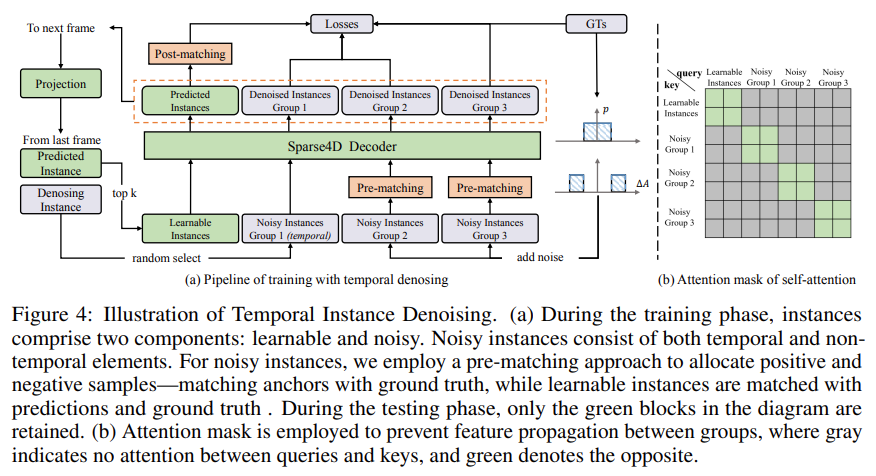
Temporal Instance Denoising
- 해당 Frame의 Ground Truth Bounding Box 에 Noise 를 추가한 것을,
- 이전 Frame 에서 Denoise 한 Bounding Box 에 다시 Noise 를 추가한 것을,
- 그리고, 이전 Frame 에서 Denoise 한 Bounding Box 만을 Learnable Parameter 로
Decoder 에 넣어준 이후,
Positive Bounding Box 는 GT 와 유사하게 Decoding 하고
Negative Bounding Box 는 GT 와 다르게 Decoding 하는 방식을 통해
Decoder 를 Robust 하게 학습하는, Recurrent 한 Instance Denoising 방식이다.Quality Estimation
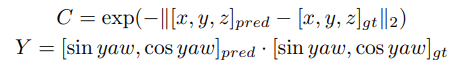
Decoder가 예측 성공한 Positive 3D Bounding Box 값에 대해,
- Yawness 에는 cross-entropy loss 를 적용하고,
- centerness 에는 focal loss 를 적용함으로써,
Predicted Sample 각각의 정확도를 엄밀히 측정하는 방식이다.
Decoupled Attention
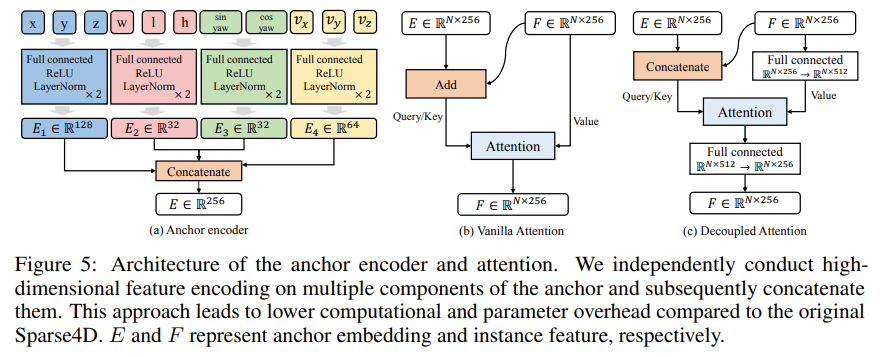
3D Bounding Box 를 구성하는
- Instance anchor
-- Translation
-- Rotation
-- Size
-- Velocity- Instance Feature
다양한 구성요소를 별도로 Encoding 한 이후,
해당 정보들을 하나의 Feature 로 합침에 있어,
더하지 않고 이어붙임으로써 (Concatenate)
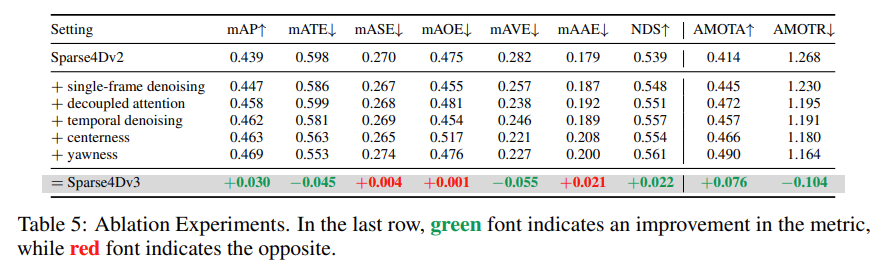
Decoder 에 Flexibility 를 더해주는 방식이다.Ablation 결과
- Temporal Instance Deonising
- Quality Estimation
- Decoupled Attention
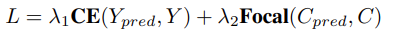
Sparse4D-V3 구현
데이터셋
nuScenes Full dataset (v1.0) https://www.nuscenes.org/nuscenes
- 1000 scenes
- Scenes distribution: / training 700 / validation 150 / testing 150
- Each scene: 20 초 영상 (2 FPS)
- 6 viewpoint images
카메라 이미지만 활용할 시, 총 데이터셋 용량 400GB 이내일 것으로 추정
깃허브
Main: https://github.com/HorizonRobotics/Sparse4D
Quick Start: https://github.com/HorizonRobotics/Sparse4D/blob/main/docs/quick_start.md시도 예정
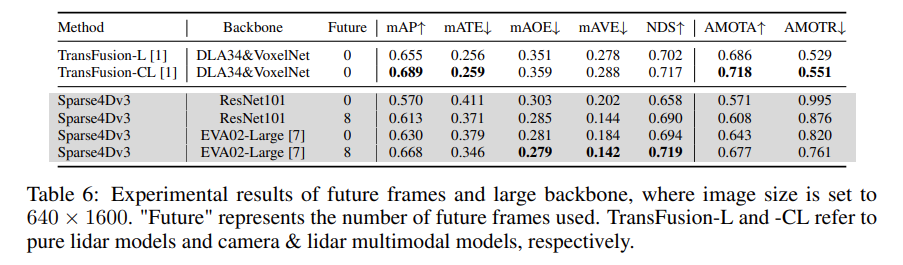
- 현재, SOTA 성능은, ResNet101 이 아닌,
Transformer based EVA02-Large 를
Backbone Encoder 로 활용한 결과
➡️ EVA02 혹은 여타 Transformer-backbone (e.g. Swin) 활용 가능
- 현재, SOTA 성능은, 실시간이 아닌, Offline Annotation 을 가정하고
Future 8 frames (2 FPS) 를 추가적으로 포함하여,
multi-frame sampling 을 수행한 결과
➡️ 어차피 Offline Annotation 진행할 것이기에, Future Frames 무조건 활용하자.
- Image resolution, Backbone encoder 에 따라, 성능 향상.
➡️ 이미지 해상도 올려보자
➡️ 어차피 Offline Annotation 진행할 것이기에, Transformer backbone (e.g. Swin) 활용 가능