이전 포스팅에선 Variational inference와 ELBO를 다뤘다. 사실 이건 모두 Variational Autoencoder(VAE)를 위해 다뤘다고 해도 과언이 아니다. 오늘 드디어 그 VAE에 대해서 알아보자.
VAE
VAE는 variational 하다와 AE라는 두 가지 특징의 조화이다.
- VAE에서 우리는 ELBO를 직접적으로 최적화하길 원한다. 이 접근은 variational하다. variational하다는 말은 best qϕ(z∣x)를 위하여 optimization하는 것을 의미한다.
- traditional AE는 input data가 주어졌을 때, 예측하기 위해 스스로 data를 학습하고 intermediate bottlenecking representation step을 겪는다. data를 주고 학습을 통해 representation하는 점이 traditional autoencoder와 유사하기 때문에 autoencoder라고 불린다.
이런 특징을 생각하며 지난 번 ELBO에서 lower bound 수식으로 이용된 Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]부터 다시 시작한다. ELBO는 다음처럼 수식이 쓰일 수 있다.
Eqϕ(z∣x)[logqϕ(z∣x)p(x,z)]=Eqϕ(z∣x)[logqϕ(z∣x)pθ(x∣z)p(z)]=Eqϕ(z∣x)[logpθ(x∣z)]+Eqϕ(z∣x)[logqϕ(z∣x)p(z)]=Eqϕ(z∣x)[logpθ(x∣z)]+DKL(qϕ(z∣x)∣∣p(z))
(지금 우리는 생성모델 VAE를 다루고 있으므로, 이 경우엔 우리는 qϕ(z∣x)를 인코더로 pθ(x∣z)를 디코더로 본다.)
결국 ELBO를 최적화 하는 것은 최종 식의 첫 번째 항을 최대화하고, 두 번째 항을 최소화 한다는 말이다.
최종 식에서 나온 두 항은 각각 이런 의미를 갖는다.
- Eqϕ(z∣x)[logpθ(x∣z)] : reconstruction term
- variational distribution으로부터 decoder의 reconstruction likelihood를 측정한 값을 의미한다.
- DKL(qϕ(z∣x)∣∣p(z)) : Prior matching term
- prior belif인 latent variables (주어진 data에 대한 latent들은 "주어진" 것이기 때문에 사전 지식(혹은 belief라고도 표현함)으로 생각할 수 있다.)와 variational distribution을 얼마나 비슷하게 측정할 건지를 의미한다.
결국 VAE는 parameters ϕ와 θ로 조합된 ELBO를 어떻게 최적화할 것인가의 문제이다. 일반적으로 VAE의 encoder는 multivariative Gaussian (with diagonal convariance) model로, prior를 standard multivariate Gaussian으로 선택된다.
qϕ(z∣x)=N(z;µϕ(x),σϕ2(x)I)p(z)=N(z;0,I)
representation trick
representation에 대해 이야기 하기 전에, Monte carlo와 stochastic approximation에 대해 간단하게 알아보자
Stochastic approximation
E[X]≈N1i=1∑NXi=SN−1+N1(XN−SN−1)
N는 데이터 개수, X는 random variable, XN은 관측된 값 (realization), SN은 추정한 기댓값(estimation)을 의미한다. 이와 같은 관점으로 Monte Carlo도 표현할 수 있다. 살펴보자.
Monte-Carlo (MC) estimate
MC는 policy Π애 대한 state value function이다. 식으로 표현하면
Vϕ(S)=E[Gt∣St=s]
이다. 자세한 MC에 대한 설명은 wiki 참고
앞서 나온 값 N, X, XN, SN을 MC 관점으로 보면 다음 표처럼 볼 수 있다.
| stochastic approiximate | MC | 설명 |
|---|
| N | - | - |
| X | Gt(S) | - |
| XN | Gt(i)(S) | i번째 episode에서 state가 S일 때 값 |
| SN | VN−1(S) | 이전 state value function의 estiamtion |
그래서 이 관점에서 MC도 바로 위의 식처럼 표현가능하다.
Vϕ(S)VN(S)=E[Gt∣St=s]=VN−1(S)+N1(Gt(i)−VN−1(s))
reconstruct term은 Monte Carlo(MC) estimation에 따라서 다음 처럼 다시 쓰일 수 있다.
ϕ,θargmaxEqϕ(z∣x)[logpθ(x∣z)]−DKL(qϕ(z∣x)∣∣p(x))≈ϕ,θargmaxl=1∑Llogpθ(x∣z(l))−DKL(qϕ(z∣x)∣∣p(x))
reparameterization trick
그러나 위 식은 모델로부터 parameterized된 distribution을 sampling하기 때문에 non-differentiable 하다! 미분 안됨! 미분이 안되면 gradient-based 방식을 사용할 수도 없기 때문에 stochastic sampling과 별개로 prediction을 예측하는 것이 필요하다.
(직관적으로 보자면, stochastic한 것 중 일부분을 deterministic하게 변경해서 backpropagation할 수 있게 하자는 것이다!)
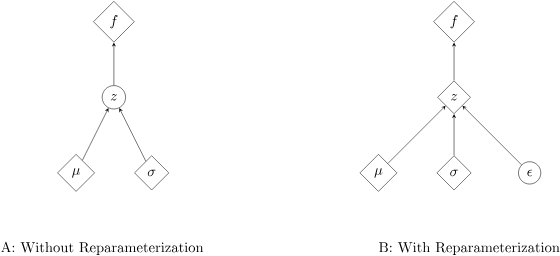
그림출처 : [2]
그래서 reparameterization trick은 random variable을 noise variable의 determination function으로 재정의 하는 것이다. 이를 통해 gradient descent로 non-stochastic terms를 optimization할 수 있다.
기본적으로 sample은 normal distribution x∼N(x;μ,σ2)을 arbitrairy(임의의) mean μ와 variance σ2로 표현된다.
x=μ+σϵ(ϵ∼N(ϵ;0,I))
arbitrary Gaussian distribution은 (ϵ은 sample을 의미.) mean을 zero부터 μ로, variance를 target variance σ2로 확장하여 standard Gaussians로 바꿀 수 있다.
VAE에서는 input x와 noise variable ϵ에 대한 deterministic function으로서 각 z를 다음과 같이 계산한다.
z=μϕ(x)+σϕ(x)⊙ϵ(ϵ∼N(ϵ;0,I))
(⊙은 element-wise product.)
reparametrized된 z는 ϕ로 표현되고 μϕ와 σϕ로 gradient가 계산된다.
❤ Reference
