
지난번에 올린 이중 연결 리스트에 대해 다시 복습해보자.
- 이중 연결 리스트는 이전 위치 포인터 + 값 + 다음 위치 포인터 형태로 이루어져 있다.
- head / tail에 대한 삽입, 삭제는 O(1). 탐색 후 원하는 노드에 대한 삽입, 삭제는 O(n)의 시간복잡도를 가진다.
오늘 정리할 자료구조는 원형 연결 리스트이다.
원형 연결 리스트는 단일 연결 리스트에서 단 하나만 바꿔줘도 완료되는 자료구조이지만 분명히 다른 점이 있다.
📘 원형 연결 리스트 (Circle Linekd List)
📌 단일 연결 리스트와의 차이점
값 + 다음 위치 포인터로 이루어져 있는 단일 연결 리스트는 head / tail의 노드가 있었다.
하지만 원형 연결 리스트의 tail 포인터는 head를 가리키고 있기 때문에 head와 tail의 정확한 구분이 없어지게 된다.
돌고 도는 원형의 모습을 갖춘 연결 리스트이기 때문에 단일 연결 리스트에서 기존의 head가 tail이 될 수도, 반대로 tail이 head가 될 수도 있다. 이 말인 즉, 모두가 연결 되어 있기에 특정 노드 구분 없이 모든 노드가 head이자 tail이라는 말이다.
더 쉽게 그림으로 보자.
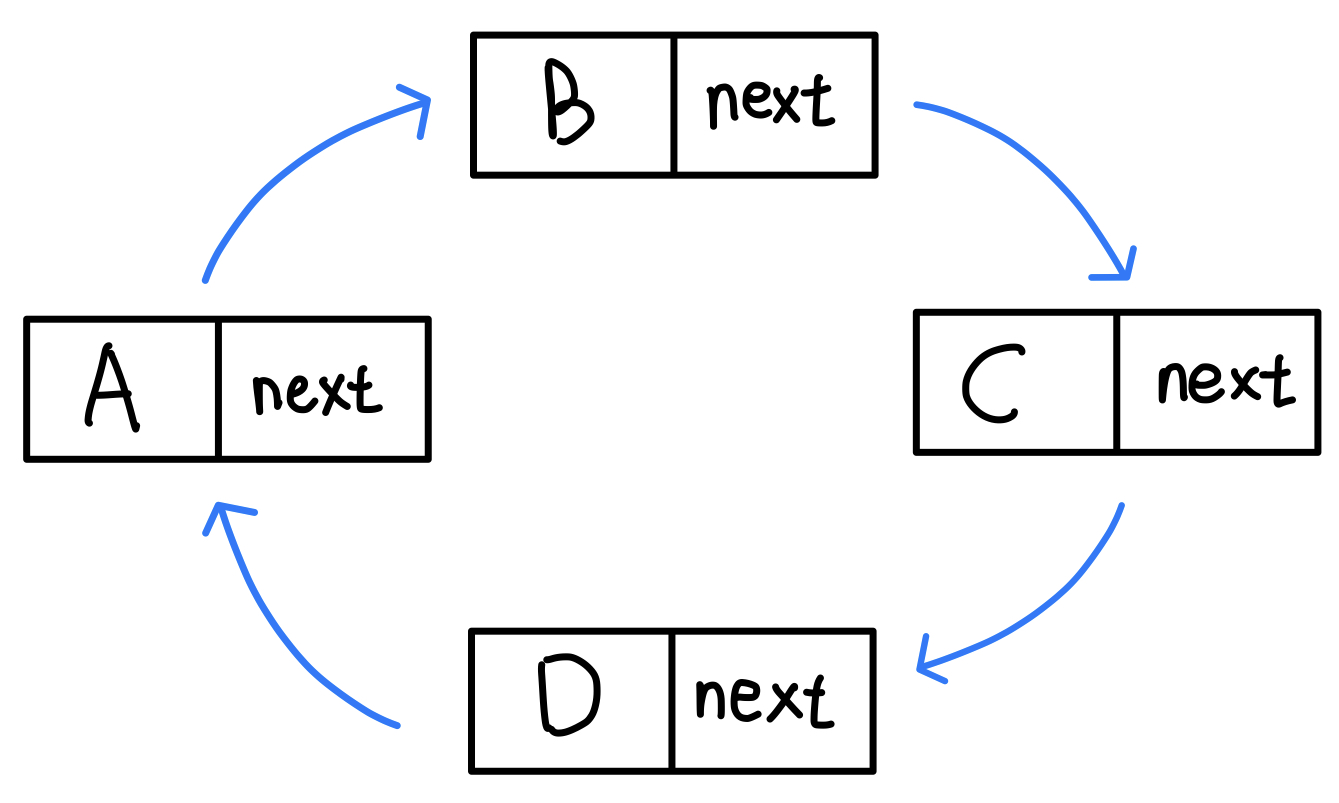
이전에 봤던 단일 연결 리스트와 이중 연결 리스트는 처음과 끝이 있었다.
포인터의 값 중 None이 들어간 노드가 있었기에 충분히 어떤 노드가 head이고 tail인지 구분이 가능했으나
원형 연결 리스트는 모든 포인터가 다음 노드를 가리키고 있기에 사용자가 특정 노드를 지목해서 사용해야 한다.
A가 시작일 경우, D가 끝.
B가 시작일 경우, A가 끝.
C가 시작일 경우, B가 끝.
D가 시작일 경우, C가 끝.
편의상 끝이라는 표현을 사용하긴 했지만 다시 시작으로 되돌아가기 때문에 사실상 끝은 없다.
그렇다면 head와 tail 변수가 모두 필요할까?
📌 if tail.next == head..?
원형 연결 리스트에서 노드에 대한 탐색, 삽입, 삭제를 진행하려면 최소 한 개의 시작점을 정해줘야 한다.
그리고 순회하며 노드에 접근하면 된다. 그렇기에 환형 연결 리스트는 단 하나의 head 또는 tail만 지정해줘도 접근해 탐색, 삽입, 삭제를 진행하는 데에 있어서 큰 문제가 없다.
그럼 임의의 노드를 head로 지정해서 환형 연결 리스트를 살펴보자.

단일 연결 리스트에서 tail.next 값이 None 이었을 때, head 노드의 값을 알아내기 위해선 head에서의 접근이 필요했다.
반대로 전체 노드의 길이가 3 이상일 때, head 노드의 포인터 값은 tail 노드가 아니므로 tail의 값 접근을 위해서는 O(n)만큼 순회해야 했다. 하지만 원형 연결 리스트에서는 tail.next의 값이 head이므로 즉각적인 확인이 가능하다.
이러한 장점이 원형 연결 리스트의 사용 이유이다.
끝나지 않고 계속하여 순회해 데이터를 찾는다는 장점이 있기 때문에 순회를 계속하는 과정 중에서 데이터를 삽입하고 삭제하는 등의 작업이 필요하다면 원형 연결 리스트를 사용한다.
📗 Programming
💻 init
class main:
def __init__(self) -> None:
self.tail = None # 객체 변수 tail 선언삽입, 삭제, 탐색 등의 작업을 진행하기 위해 객체 변수 tail을 선언한다.
💻 end_insert
def end_insert(self,data):
new_node = Node(data) # 새로운 노드 추가
if self.tail is None: # 노드가 빈 상태일 때
self.tail = new_node
else: # 노드가 비어있지 않을 때
self.tail.next = new_node
new_node.next = self.tail
self.tail = new_node노드가 비어있을 때, 새로운 노드를 tail로 선언해주었다. 이후 노드가 비어있지 않는 상황일 땐 tail의 뒤쪽에 새로운 노드를 추가하는 조건문을 작성해주었다.
💻 select_insert
def select_insert(self, data, pick_node):
new_node = Node(data)
search = self.tail
while self.head is not None:
if self.tail.data == pick_node:
new_node.next = self.tail.next
self.tail.next = new_node
self.tail = new_node
break
if search.data == pick_node:
new_node.next = search.next
search.next = new_node
break
search = search.next
if search == self.tail:
return False지정한 노드의 값 뒤에 새로운 노드를 연결해주는 메서드로 첫 조건문에서는 tail이 변동될 때의 조건문을 작성해주었다.
해당 조건이 아닐 경우엔 연결 리스트를 순회하며 해당 노드의 뒤에 새로운 노드를 추가하도록 작성하였다. 하지만 리스트를 모두 순회했음에도 지정한 노드가 탐색되지 않을 시 False를 반환하였다.
💻 select_remove
def select_remove(self, pick_node):
prev_node = self.tail
current_node = self.tail.next
while self.tail is not None:
if self.tail.data == pick_node:
self.tail.next = None
self.tail = current_node
break
if current_node.data == pick_node:
prev_node.next = current_node.next
current_node = None
break
prev_node = current_node
current_node = current_node.next
if current_node == self.tail:
return Falseselect_insert 메서드와는 조금 다르게 이전 노드의 정보와 현재 노드의 정보를 갖고 있는 지역 변수 2개를 선언해주었다.
조건문은 select_insert 메서드와 유사하며, 삭제 시 이전 노드의 포인터를 현재 선택된 노드의 포인터로 변경해주었다.
💻 print_node
def print_node(self):
iterator = self.tail.next
while iterator is not None:
if iterator == self.tail:
print(f'값 : {iterator.data}, 다음 노드의 위치 : {iterator.next}')
break
print(f'값 : {iterator.data}, 다음 노드의 위치 : {iterator.next}')
iterator = iterator.next
연결 리스트를 순회하며 리스트의 노드 정보를 출력하도록 하였고, iterator 지역 변수의 초기값을 tail.next(head)로 지정해주었다. 리스트를 모두 순회하고 다시 tail 노드로 돌아왔을 때는 노드 정보와 포인터 정보를 출력하고 반복문에서 빠져나오도록 작성하였다.
