
오늘은 해시 테이블에 대해 정리하고자 한다.
파이썬에서의 동일한 형태의 자료구조로는 딕셔너리가 있다.
파이썬을 통해 배웠던 딕셔너리의 형태는 key-value 구조로 이루어져 있는데 해시 테이블도 이와 동일하다.
다만, 해시 테이블의 구조와 핵심이라 할 수 있는 해시 함수는 무엇인지를 알아보기 위해
해시 테이블을 학습하고 정리하고자 하는 것이 이번 학습의 목표이다.
📘 해시 테이블 (Hash Table)
📌 자료 저장까지의 흐름
해시 테이블에 대한 공부를 하다보면 책, 블로그, 구글 등등 가장 많이 보이는 그림이 아래 그림이다.
일단 천천히 그림을 읽어나가자면
- keys 아래에 보이는 이름들이 hash function으로 들어간다.
- 각각의 이름은 hash function을 거쳐서 buckets의 인덱스로 바뀐다.
- 그리고 buckets에는 이름에 해당하는 전화번호가 들어간다.
- 여기까지가 단적으로 봤을 때 해시 테이블의 흐름이다.
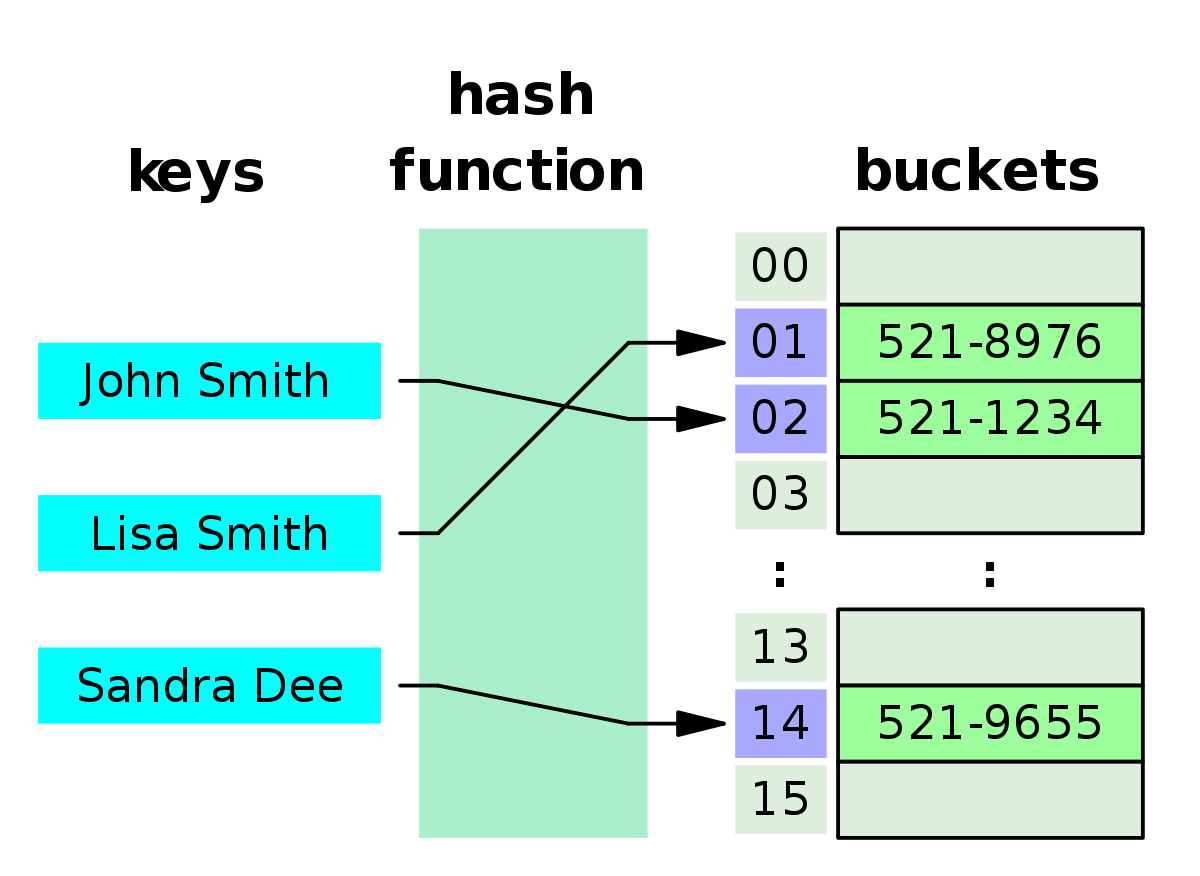
하지만 신기하게도 이게 해시 테이블이라는 자료구조 전체 중 80%이다.
그렇다는 건 나머지 20%만 배우면 끝이라는 말이다.
그래서 오늘의 정리는 여기서 끝이다.
📌 왜 사용할까?
해시 테이블의 사용 이유는 빠른 탐색과 삽입, 삭제이다. key를 통해 값으로 빠르게 접근할 수 있고
해시 충돌이 없다는 가정 하에는 탐색, 삽입, 삭제 모두 O(1)의 시간 복잡도를 보여준다.
다만 해시 충돌이 없다는 전제 하에 O(1)이며, 대개 충돌이 발생하게 되고, 충돌 시 상황을 보완해 사용한다.
해시 함수를 잘 짜놓는다면 해시 테이블은 수많은 데이터 양에서도 빠른 탐색, 삽입, 삭제의 성능을 보여주게 되어 충돌이 적고 되도록 충돌하게 되는 패턴이 일정한 해시 함수가 잘 짜여진 해시 함수라고 볼 수 있다.
📌 좀 더 자세히 보는 흐름
위의 그림을 통해 전반적으로 어떻게 된 건지 이해가 됐을 수도 안 됐을 수도 있다.
이해가 됐다면 더 확연하게. 이해가 덜 됐다면 이해가 되도록 한번 더 자세히 보자.
용어 및 구성 요소 정리
- key = 값을 찾기 위한 요소. hash function을 통해 값이 변화하며, 변화된 값은 bucket의 인덱스로 쓰인다.
- hash function(해시 함수) = key를 받아서 index로 변화시켜준다. 해시 테이블의 가장 중요한 요소이다.
- bucket / slot = 값이 저장되는 공간 (빈 배열 공간)
가장 먼저 해시 테이블의 자료 저장 형태는 key-value라는 것이다. (ex.김김김-1234, 이이이-2345, 박박박-3456)
키를 통해서 값의 삽입, 삭제, 검색이 가능하며 키가 없다면 값의 접근이 불가하기 때문에 이러한 기능 사용도 불가하다.
그렇다면 앞서 봤던 인덱스로 바꿔주는 해시 함수의 형태는 어떻게 되어있을까?
- Division (key mod bucket)
- bucket의 크기보다 큰 수를 줄여 bucket의 크기 안으로 넣기 위해 사용한다.
- bucket의 크기는 2^n이 아닌 수가 효율적이다.
- 숫자 형태의 키를 버킷의 길이로 나눠 나머지를 구한다.- Multiplication (bucket(keyA mod 1))
- Division과 달리 bucket의 크기는 2^n인 수가 효율적이다.
1. 임의의 상수값을 가진 변수 A를 선언한다. (0<A<1)
2. key와 A를 곱한 후 1로 나눠 나머지를 구한다. (이때 소수점 형태로 값이 출력된다)
3. bucket의 길이를 곱한다.- Universal hashing
- 여러 해시 함수가 들어있는 집합에서 랜덤한 키와 해시 함수를 사용해 인덱스를 구한다.
- 1 / bucket 확률로 해시 충돌이 일어난다.
진짜 다시 봐도 Division 밖에 모르겠음
이렇게 대표적으로 3가지의 방법이 있지만 보통의 경우, Division을 통한 해시 함수를 주로 사용하곤 한다.
Division의 경우, 간결하고 동작이 빠르다는 데에 장점이 있지만 대개 높은 확률로 해시 충돌이 일어나기 때문에 이러한 충돌에 대비하는 코드가 필요하다.
📗 Programming
💻 init
class Hash:
def __init__(self, buckets) -> None:
self.size = buckets
self.hashtable = [0 for _ in range(buckets)]
self.cnt = 0메인 클래스 Hash를 통해 처음 객체를 생성할 때, buckets의 길이를 받아 객체 변수 size에 저장해주었다.
또한 buckets 길이만큼의 배열을 0으로 초기화해 hashtable이라는 객체 변수를 생성하였다.
💻 save
def save(self, key, value):
self.hashtable[self.hash_function(key)] = value
self.cnt += 1
return print(self.hashtable)save 메서드에서는 key와 value를 받아 해시 함수를 통해 key 값을 인덱스로 변환하여 value값을 저장해주었다. 또한 return 값으로는 저장 후 hashtable의 저장 상태 확인을 위해 print 출력하였다.
💻 hash_function
def hash_function(self,key):
self.key = ord(key[0]) % self.size
return self.key해시 테이블의 핵심인 해시 함수이다.
가장 먼저 문자열의 첫번째 문자를 기준으로 아스키코드 변환하여 숫자값을 받아왔고,
이런 숫자값을 다시 버킷의 길이로 나누어 나머지 값을 키 값으로 지정해주었다.
이후에는 save 메서드에서 사용할 수 있도록 key 객체 변수를 리턴해주었다.
💻 remove_value
def remove_value(self, key):
if self.hashtable[self.hash_function(key)] != 0:
self.hashtable[self.hash_function(key)] = 0
self.cnt -= 1
return print(self.hashtable)
else:
return False
save 메서드와 동일하게 해시 함수를 통해 해시 값을 지정하고 해당 번지에 저장된 값을 다시 0으로 초기화 해주었다. 다만 해당 번지에 값이 없을 경우(0인 경우)에는 False를 리턴하도록 하였다.
📙 해시 충돌(Hash collision)
🧐 충돌 보완
위의 프로그램는 해시 충돌에 대한 보완을 하지 않은 프로그램이다.
충돌에 대한 보완이 없다면 이전에 들어있던 값은 지워지고 새로운 값으로 덮어 씌워지게 된다.
때문에 기존 값을 보존하려면 덮어 씌워지지 않고 새로운 값을 저장할 여러 방법을 모색해 보아야 한다.
충돌 보완의 방법으로는 대표적으로 2가지가 있다.
📌 Open Hashing
오픈 해싱은 단어의 직역 그대로 개방된 해싱을 뜻한다.
기존의 테이블 외의 추가 공간을 만들어 데이터를 저장하는 방식으로 대표적으로 Chaining 방식이 있다.
주로 연결 리스트를 이용해 값을 저장하며, 노드끼리 연결해 버킷에 저장하는 게 주된 내용이다.
📌 Close Hashing
클로즈 해싱은 오픈 해싱과 반대되는 폐쇠된 해싱을 뜻한다.
기존의 테이블 공간 중 빈 공간을 찾아 값을 저장하며, Linear / Quardratic / Double 해싱이 있다.
하지만 이러한 방식은 Clustering(군집화=데이터 몰림)이 쉽게 발생하기 때문에 이를 잘 해결해야 한다.
Linear : 충돌 발생 시 1칸씩 이동하며 빈 공간을 탐색한다. (Clustering O)
Quardratic : 충돌 발생 시 n^2칸씩 이동하며 빈 공간을 탐색한다. (Clustering O)
Double : 해시 함수가 2개이며, 하나는 해시 값을 찾는 데 활용되고, 다른 하나는 탐사폭을 정하는 데에 활용된다.
1. Open Hashing
💻 Chaining
class Node:
def __init__(self, data, next = None) -> None:
self.data = data
self.next = nextChaining에 사용할 노드를 생성하는 클래스를 선언하였다.
기존 연결 리스트와 같이 값을 저장하는 변수와 다음 노드를 가리키는 포인터 변수를 선언해주었다.
def save(self, key, value):
if self.hashtable[self.hash_function(key)] == 0:
self.hashtable[self.hash_function(key)] = Node(value)
else:
self.hashtable[self.hash_function(key)].next = Node(value)
return self.hashtable이후 저장 부분에서 기존의 코드와 다른 부분은 value 값을 직접적으로 넣어주지 않고 Node에 저장해 연결 리스트 형태로 값을 저장하였다.
2. Close Hashing
💻 Linear hashing
def save(self, key, value):
my_key = self.hash_function(key)
if self.cnt == self.size: # 테이블이 꽉 찼다면 이후 과정없이 False 반환
return False
while self.hashtable[my_key] != 0: # 해시 충돌이 발생한다면 실행
my_key += 1 # 해당 칸으로부터 1칸씩 인덱스 이동
if my_key == self.size: # 빈 공간이 없다면 앞으로 돌아가 탐색
my_key = 0
self.hashtable[my_key] = value
self.cnt += 1Linear Hashing은 선형 탐색 구조로 이루어져있다.
프로그램에서는 my_key라는 변수를 선언하여 해시 값을 할당해주었고 해시 충돌이 발생한다면 해당 공간으로부터 1칸씩 이동하여 빈 공간에 값을 넣도록 작성하였다.
