강화학습 개념정리(3) - 알고리즘 종류, on-policy, off-policy, Q러닝, Policy Gradient, Model-Free, Model-Based
RL from zero to hero
Part2: Kinds of RL Algorithms
Taxonomy of RL Algorithms
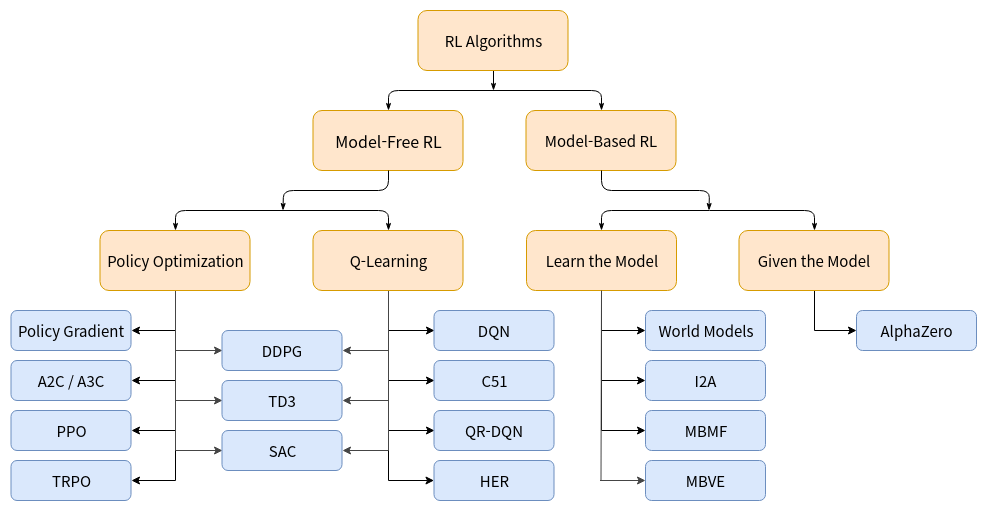
미리 말하자면, 위 분류는 완벽하지 않다. RL의 특성 상 트리 구조로 엄밀하게 분류하기가 힘들기 때문이다. 예를들어 Policy Gradient 와 Value Function을 둘다 사용하는 DDPG, TD3, SAC는 세부적으로 다르게 작동하지만 트리구조 상에서는 같은곳에 위치하게 된다.
그럼에도 불구하고 위 그림의 분류는 개념을 잡기에 상당히 괜찮은 그림이니 헷갈릴때마다 참고하면 되겠다. 아무튼 차치하고 이번 장의 목표를 먼저 적어보자면
- Deep RL 알고리즘이 무엇을 어떻게 배울지에 대한 근본적인 기초 설계 선택지를 배운다.
- 이런 설계 선택지들 간의 Trade off 를 배운다.
- 설계 선택지들 각각에 대응되는 현대의 RL 알고리즘들 중 중요한것들을 배운다
Model-Free vs Model-Based RL
RL 알고리즘 선택지들 간에 가장 중요한 분기점은 바로 'Agent가 환경(Environment)에 대해 알고있는지' 이다. 여기서 환경에 대해 안다는 것은 상태변화와 보상을 예측할 수 있다는 것이다.
환경을 알고있다는것의 가장 큰 장점은, 에이전트가 어떤 액션을 하면 어떤 일이 일어날지를 미리 예측하고 그 중 나은것을 결정할 수 있다는 것이다. 에이전트는 이처럼 미리 계획한것을 학습된 정책으로 옮길 수 있다. 이러한 방식의 대표적인 예가 알파제로이다. 이렇게 하면 (환경의)모델을 모를때 쓰는 방법 보다 Sample Efficiency를 크게 향상 시킬 수 있다.
이러한 방법의 가장 큰 단점은, 보통의 경우 agent가 환경의 모델을 완전히 알기 힘들다는 것이다(체스, 바둑등의 게임세계 같이 모든 Rule을 알고 있는 환경은 굉장히 드물며, Real World에서 환경을 완전히 아는것은 아예 불가능하다.) 이러한 경우에 Model-Based를 쓰고 싶다면, Agent는 순수하게 탐험을 하므로써 환경을 배울 수 밖에 없는데 이는 여러모로 굉장히 힘든 일이다. 가장 큰 문제는 Agent가 (환경의)모델에 존재하는 편향을 잘못 학습하여 학습에 이용한 환경에서는 성능이 뛰어나지만, 실제 환경에서는 매우 형편없게 동작할 수 있다는 것이다. (환경의)모델을 배운다는것은 근본적으로 매우 힘든 일이라 아무리 노력하고 시간을 쏟아 학습시켜도 잘 동작하지 않을 확률이 높다.
위처럼 모델을 쓰는 알고리즘을 model-based 방식 이라고 하고, 모델을 쓰지 않는 알고리즘을 model-free 방식이라고 한다.
model-free는 위에서 언급한 sample efficiency를 포기하지만, 구현 및 튜닝이 상대적으로 훨씬 쉽다. 오늘날에는 model-free가 model-based 보다 더 널리 연구되고, 쓰이고 있다. 우리도 당연히 model-free에 집중한다.
What to learn
'무엇을 배울지'는 RL 알고리즘 선택지들 간에 또다른 중요한 분기점이 된다. RL 알고리즘이 배우는것의 대중적인 선택지는 다음과 같다.
- 확정적(Deterministic), 혹은 확률적(Stochastic) 정책(Policy)
- Action-Value Function (Q-Function)
- Value Function
- Environment Model
What to learn in Model-Free RL
Model-Free RL에서의 학습에는 크게 두가지의 접근 방식이 있다.
Policy Optimization
Policy Optimization에 속한 Family는 명시적 정책(Explicit Policy) 을 가진다. 얘네는 Gradient Ascent 하므로써 직접적으로 파라미터 를 최적화 하거나, 의 국소 근사치를 극대화 하므로써 간접적으로 파라미터 를 최적화 한다.
이러한 최적화는 거의 항상 on-policy 방식으로 행해진다. Policy Optimization은 또한 on-policy value function인 의 approximater인 의 학습을 동반하는데(대표적으로 A2C), 이는 정책을 업데이트 하는데 쓰인다.
on-policy ?
on-policy는 정책 업데이트에 실제로 행동을 하고 있는 가장 최신 버전의 policy로 수집된 데이터만 사용하는 방식이다. Data Efficiency가 떨어지지만 구현이 쉽고 여러 종류의 정책에 적용 가능하다는 장점이 있다.
Policy Optimization 방식의 예는 다음과 같다.
- A2C/A3C: 직접적으로 목표함수 를 극대화 하기 위해 Gradient Ascent를 사용한다.
- PPO: PPO는 반면에, 가 '업데이트로 인해 얼마나 변할지'에 대한 보수적인 추정치를 제공하는 대리 목표 함수(a surrogate objective function)를 극대화 하므로써 간접적으로 목표 함수를 극대화 한다.
PPO(Proximal Policy Optimization)의 설명이 이해가 안되더라도(솔직히 나도 모르겠다) 일단 넘어가자. 추후에 디테일하게 다룰 예정이다.
Q-Learning
Q-Learning Family는 최적 액션-벨류 함수인 에 근사하는 액션-벨류 함수 를 학습한다. 일반적으로 얘네는 벨만 방정식에 기초한 목표 함수를 사용한다. 이러한 최적화는 거의 항상 off-policy 방식으로 행해진다. 정책을 직접 학습하는게 아니므로 내재적 정책(Implicit Policy)를 사용한다고 할 수 있고, 이 정책은 와 의 관계로부터 도출된다.
의 의미는 상태 s에서 a의 액션을 행하고 난 후, 정책 로 끝까지 행동 했을때의 보상의 합이다. 이러한 의미를 생각해 볼때, 위의 수식은 자명하다.
off-policy ?
off-policy는 on-policy와 달리 정책 업데이트에 어떤 데이터를 써도 상관이 없다. 즉, 가장 업데이트된 정책에서 수집된 데이터가 아니라도 정책 업데이트에 사용할 수 있다.
Q-Learning 방식의 예는 다음과 같다.
- DQN: Deep RL의 시초. 모르면 간첩.
- C51: 기대치가 인 리턴의 분포를 학습하는 방식(이게뭔소리지;;)
Trade-offs Between Policy Optimization and Q-Learning
Policy Optimization의 주요 강점은 우리가 원하는 사항을 직접적으로 최적화 한다는 점에서 원칙이라는 것이다. 이러한 경향은 PO를 안정적이고 신뢰할 수 있게 만든다. 이와 반대로 Q-Learning은 Self-consistency equation(벨만방정식)을 만족시키기 위해 를 학습하므로써 간접적으로만 최적화한다. 이러한 학습 방식에는 많은 실패 형태가 있기때문에, 덜 안정적이라 할 수 있다. 하지만 q-learning은 sample efficiency의 관점에서 PO보다 훨씬 뛰어나다는 장점이 있다. 이는 off-policy의 특징으로, 데이터를 재사용 할 수 있기 때문이다.
Interpolating Between Policy Optimization and Q-Learning
PO와 Q-Learning을 대비되게 설명하다보니 뭔가 양립할 수 없는 존재들 같지만, 사실 그렇지 않다. 이 둘은 compatible하며, 특정한 조건이 만족될때는 심지어 동일하다. 실제로 이 양극단 사이에 존재하는 알고리즘들이 있고, 얘네는 PO와 Q-learning의 장/단점을 적절히 조율하여 사용한다. 알고리즘들의 예는 다음과 같다.
-
DDPG: 확정적 정책(Deterministic Policy)과 Q-function을 동시에 배우고, 서로를 이용해서 개선하는 알고리즘
-
SAC: 확률적 정책(Stochastic Policy), 엔트로피 정규화등 여러 트릭을 통해서 학습을 안정화 시키고, 벤치마크에서 DDPG보다 높은 성적을 받은 DDPG의 변형.
What to learn in Model-Based RL
말했듯이, model-based 보다 model-free에서 연구와 성과가 더 활발한데, 이 이유는 그만큼 환경의 모델을 알기 힘들다는 점에 기인한다. 그래서 나도 정리 하기가 싫어서 안할거다ㅋ
아마 나~중에 시간 나고 할거 없을때 하지않을까.. TBC.
Conclusion
on/off policy나 model-based에 대해 헷갈리는 부분이 있었는데, 정리를 하면서 명확해진것 같다. 이제 좀 더 심화적인걸 공부 할 생각에 설렌다(?)
