
1. 개요
회사에서 여러 이유로 대쉬보드 관련 툴을 공부해볼 기회가 생겼는데, 공부와 실습 차원에서 대쉬보드 툴로 잘 알려진 Streamlit과 Auto-ML 툴로 잘 알려진 tpot을 결합? 해서 Gui 기반 Auto-ML 서비스를 만들어 보려고 한다. 굳이 따지자면, 코딩이니 뭐니 하기 싫지만 머신 러닝으로 뭔가가 되긴 하는지 보고 싶다- 고 생각하시는 분들을 위한 화면?서비스?를 만들어 보고 싶었다.
2. Tpot
Tpot[티팟]은 모델 선택, Hyper Parameter 최적화 등을 자동으로 수행해 주는 Auto-ML 툴이다. 유전 알고리즘을 활용하여 모델을 선택하고, 성능을 비교할 수 있게 해줄 뿐 아니라 Best Model을 만드는 Python Code까지도 제공한다. 머신 러닝을 잘 모르는(나 같은) 사람도 상대적으로 쉽게 모델을 선택하고, 생성할 수 있게 해준다. 머신 러닝을 좀 아는 사람이 조금 신경쓴다면 물론 훨씬 나은 모델을 만들 수 있겠지만, 그정도의 공수를 들일 수 없거나 들이고 싶지 않은 상황에서는 강력한 도구일 것이다.
3. Streamlit
Streamlit은 간단한 파이썬 스크립트 만으로 꽤 보기 좋은 웹 화면을 만들 수 있게 해주는 Python Library이다. 주로 대쉬보드를 만드는 데에 사용되는 듯 하며 Flask, Dash 등과 비교하여 훨씬 개발 공수가 덜 든다. 아직 완벽하게 Stable한 패키지는 아니여서 있을 것만 같은 기능이 없는 경우도 있지만, 지금의 상황에서, 소규모의 Public한 프로젝트를 진행하기에는 아주 적합한 툴이라고 할 수 있다.
4. 설계
(1) 사용자가 PC에 저장된 csv파일을 Upload해서
(2) 문제 유형(분류/회귀)을 선택하고
(3) Target 을 설정하고,
(4) tpot으로 자동 생성된 모델들을 비교하고,
(5) Best Model을 만들 수 있는 코드를 받는다.
위와 같은 구조로 서비스를 만들려 한다.
5. Code
import streamlit as st
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from tpot import TPOTRegressor
from tpot import TPOTClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics필요한 Library들을 Import한다.
st.title('Streamlit Practice')
st.write("JJ @ Geultto")
st.title을 사용하여 제목을, st.write를 사용하여 일반 텍스트를 작성한다. 참고로, st.write는 참 기가 막힌 친구인데,
- 여러 인자를 동시에 받을 수 있고
- 여러 타입을 동시에 받을 수 있다.
뭐든 쓰고 싶으면..st.write를 사용하는 듯 하다.
def auto_tpot(data,target_col,predict_type, tr_size=0.7,ts_size=0.3, random_state=1123, file_name = "temp.py"):
X_train, X_test, y_train, y_test = train_test_split(data, target,
train_size = tr_size , test_size = ts_size, random_state=42)
if predict_type == 'regressor':
tpot = TPOTRegressor(generations=5, population_size=50, verbosity=0)
elif predict_type == 'classifier':
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=0)
else :
print("predict type must be 'regressor' or 'classifier'")
tpot.fit(X_train, y_train)
df_temp = pd.DataFrame(dict(tpot.evaluated_individuals_.items())).T
df_temp.reset_index(inplace=True)
df_temp["model"] = list(map(lambda x : x.split("(")[0], df_temp['index']))
df_temp.rename(columns={'index':'parameters'},inplace=True)
result = df_temp[['model','internal_cv_score','parameters']].sort_values(by='internal_cv_score',ascending = False).reset_index().drop(['index'],axis=1).head(15)
return X_test,y_test, tpot, result
Data, Target 변수, 문제 유형을 parameter로 받으면 X_test, y_test, tpot 모델, 그리고 모델의 성능을 return하는 함수를 작성하였다.
모델은 가장 좋은 성능을 가진 15개만 보여주게 하였는데, Tpot이 만든 모든 모델을 보여주면 모델이 수백개여서, 임의로 15개만 보기로 설정했다.
st.header('Auto Machine Learning')
uploaded_file = st.file_uploader("Choose a file")(1) st.file_uploader를 사용하여 사용자로부터 file을 받는다.
if uploaded_file is not None:
df_pred = pd.read_csv(uploaded_file, encoding = 'CP949')
st.write(df_pred)
try:
target_col = st.selectbox("target column goes here",tuple(df_pred.columns))
predict_type = st.selectbox("predict_type goes here",('regressor', 'classifier'))
except:
st.error("Target column and Predict type is required!")
eda_col = st.selectbox("select column to explore",tuple(df_pred.columns))(2) selectbox를 만들어서 회귀 문제인지 (Regressor) 분류 문제인지 (Classifier) 선택하게 한다.
(3) selectbox를 만들어서 입력 받은 Data가 갖고 있는 열 중 하나를 Target으로 설정하게 하고,
if st.button("Run AutoML"):
data = df_pred.drop([target_col],axis=1)
target = df_pred[target_col]
try:
df_dtype = pd.DataFrame(data.dtypes,columns=["Dtype"])
cat_cols = list(df_dtype[df_dtype.Dtype == 'object'].index) #categorical columns
num_cols = list(df_dtype[df_dtype.Dtype != 'object'].index) #numerical columns
cat_data = data[cat_cols]
cat_dummy = pd.get_dummies(cat_data)
data_dummy = pd.concat([cat_dummy,data[num_cols]],axis=1)
data_dummy = (data_dummy-data_dummy.min())/data_dummy.max()
data = pd.concat([data_dummy,target],axis=1)
except:
pass
if uploaded_file is not None:
with st.spinner('Wait for it...'):
X_test,y_test, tpot, result = auto_tpot(data, target_col,predict_type, tr_size=0.7,ts_size=0.3, random_state=123)
st.write(result)
preds = tpot.predict(X_test)
if predict_type == 'classifier':
score = metrics.accuracy_score(preds,y_test)
else:
score = metrics.r2_score(preds,y_test)
st.write('Best Model, Scored Internal CV score {}.'.format(score))
st.write("Code to produce the Best Model is below")
st.code(tpot.export())(4) st.button() 을 활용하여 버튼을 만들었다. 버튼을 누르게 되면, 범주형 변수로 생각되는 경우(type이 object인 경우) 더미변수화하여 수치형 변수와 결합한다. 따지고 보면 틀린 방법인데, (숫자로 보여도 범주형일 수 있고, 반대의 경우도 있으므로) "아주 간단한 ML 모델 구축"이라는 본 목적과 구현의 편의를 위해 이와 같이 진행했다.
(5) 버튼이 눌렸고, 업로드된 파일이 있다면, 본격적으로 위에서 만든 함수를 사용하여 모델을 생성, 비교하고, 생성된 모델의 결과를 보여주고, 최고 모델의 코드를 볼 수 있게 해준다.
위와 같은 코드를 streamlit.py로 작성하고, Console에서 (혹은 Jupyter Notebook에서)
streamlit run streamlit.py로 해당 파일을 실행해 주면, 다음과 같은 화면이 완성된다.

최초 진입 화면, 제목과 부제가 보인다.
파일을 업로드 할 수 있다.
데이터를 업로드 하자(iris)데이터가 보이고, Target Column과 문제 유형을 결정하는 Select Box가 나타난다.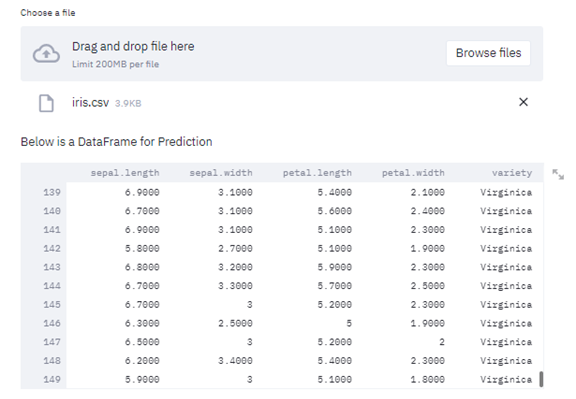
Target과 문제 유형을 적절히 선택하고, Run AutoML 버튼을 클릭하면 사전에 입력해 둔 대로 Wait for it...이라는 메시지가 나타난다. 이후에 한참 기다리면,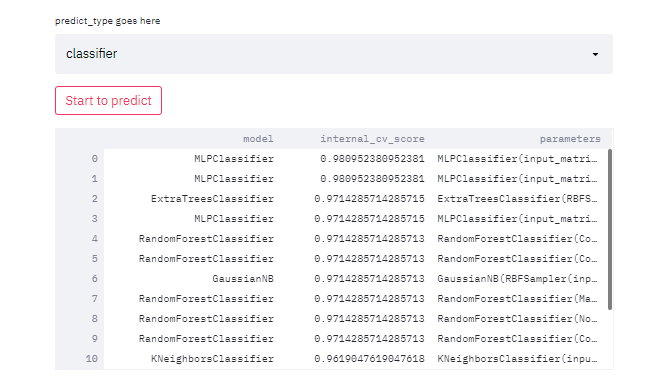
위와 같이 모델별로 성능이 나타나고,
위와 같이 모델생성을 위한 코드도 나타난다.