디지털 이미지
컴퓨터의 입장에서 이미지란?
H(높이) x W(너비) x C(채널) 로 이루어진 3차원 행렬
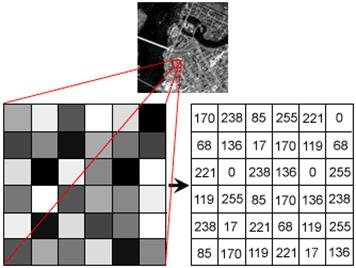
- 각 행렬의 값은
0~255로 이루어져 있다. 이러한 값들을 pixel value, gray level, color depth 등으로 부르는데, 해당 픽셀의 밝기를 의미한다. - 채널은 일반적으로
RGB의 3채널로 이루어져 있다. R(Red), G(Green), B(Blue)를 의미한다.
이미지 분류가 어려운 이유
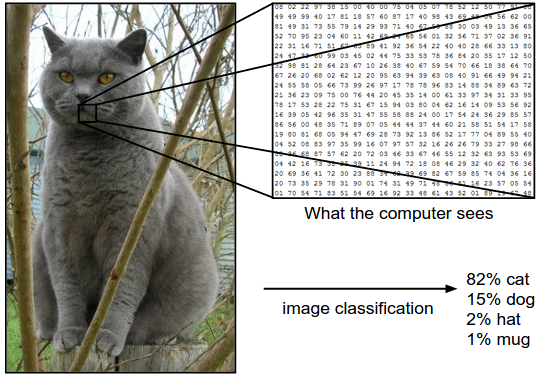
사람은 이미지를 픽셀 단위로 보지 않고, 하나의 거대한 덩어리로 인식한다. 반면에 컴퓨터는 물체를 픽셀 단위로 인지하기 때문에 프로그래머가 적절한 조건(Rule)을 이용하여 의미를 부여해 주어야 한다.
하지만 같은 고양이라도 외형, 색, 사이즈 등이 제각기 달라서 이를 규칙으로 분류하기는 매우 까다롭다.
- View point variation : 보는 관점에 따른 차이
- Scale variation : 크기에 따른 차이
- Deformation : 강체가 아니므로 변형이 일어날 수 있다
- Occlusion : 무언가에 가려지는 경우
- Illumination conditions : 밝기 차이
- Background clutter : 카멜레온처럼 주변환경과 식별하기 힘든 경우
- Intra-class variation : 클래스의 범위가 너무 넓은 경우 ex) 의자
Data-driven Approach
이미지와레이블의 쌍으로 이루어진 데이터를 많이 모으자- 레이블: 각 이미지를 식별할 수 있는 카테고리
- 데이터 셋들로 머신러닝 모델을 학습시키자
- 각 이미지에 대해
모델이 예측한 레이블-실제 레이블을 비교하여 평가하자
Nearest Neighbor Classifier
- 가장 가까운 이웃 데이터들에 의해 자신의 레이블을 결정하는 방식
- 입력된 테스트 이미지와 모든 학습 이미지를 1대1로 비교하여 가장 가까운 이미지의 레이블을 취하는 방식을 사용하였다.
- 가까운 지를 어떻게 평가할까?
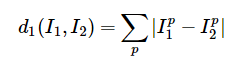 L1 distance (Manhattan distance) 를 이용하자. 즉, 픽셀 단위로 차이 값을 구하고 이 값을 모두 더한다. 이 값이 작을수록 두 이미지는
L1 distance (Manhattan distance) 를 이용하자. 즉, 픽셀 단위로 차이 값을 구하고 이 값을 모두 더한다. 이 값이 작을수록 두 이미지는 비슷하다 = 가깝다를 의미한다.
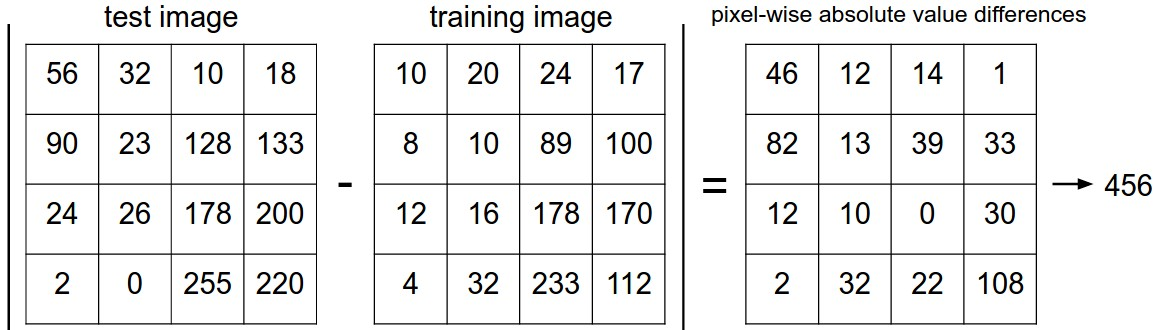
- L1이 아닌 L2 distance를 사용할 수도 있다.
- CIFAR-10 데이터 셋에 대해서 동작시켜보면 약 38.6%의 정확도이다.
K-Nearest Neighbor Classifier
- k개의 가장 가까운 이웃 데이터로 자신의 레이블을 결정하는 방식
- k가 클수록 각 클러스터가 명확히 구분되는 특징을 가진다.

hyper-parameter
- KNN Classifier에서는 k 값에 따라 분류기의 성능이 달라진다. 또 L1, L2 distance 중 어떤 함수를 이용하느냐에 따라서도 결과가 달라질 수 있다. 이처럼 모델을 설계할 때 우리는
하이퍼 파라미터를 선택해야 하는 상황에 항상 놓이게 된다.
Validation and Test set
- 지금 가지고 있는 데이터 셋에 대해서 잘 동작하도록 하이퍼 파라미터를 조정한다면 모델은 당연히 잘 동작할 것이다! 왜냐하면
과적합 (overfitting)되었기 때문에.. - 그러므로 항상 Validation set과 Test set을 Train set과 분리하여 사용해야 한다.
Train set : 모델의 학습을 위한 용도
Validation set : 하이퍼 파라미터를 갱신하기 위한 유효성 검사 용도
Test set : 테스트하여 성능을 평가하는 용도
Cross-Validation

- train data를 여러 fold로 나누고, 각 fold 를 한번씩 돌면서 validation set의 역할을 수행하는 방법이다.
- 데이터 셋이 적을 때는 유리하지만, 느리다는 것이 단점이다.
KNN Classifier의 한계
- KNN은 데이터를 저장하기만 하면 되므로 학습이 빠르지만, 테스트를 할 때마다 모든 학습 이미지와 1대1로 비교해야 하므로 너무나도 느리다. 우리는 학습이 느리더라도 테스트가 빠른 분류기를 원한다.
- 이미지는 고차원 객체이고, 고차원에서 거리라는 개념은 직관적이지 않다.

original 이미지와 우측 3개 이미지와의 L2 distance 차이는 매우 크다.
- 한계를 넘어서기 위해 보다 정확한 분류 모델이 필요하다.
Python, CV, ML, Backend