Score Function
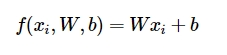
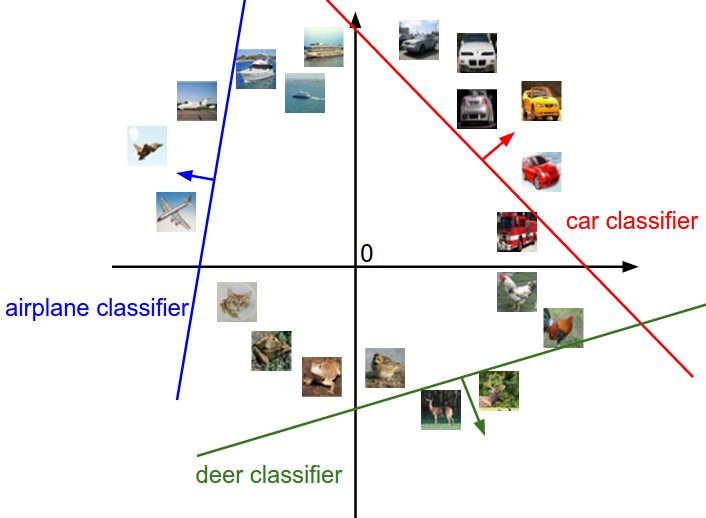
x_i = input image
W = weight matrix (weights)
b = bias vector (parameters)
우선 우리가 분류하고자 하는 클래스의 갯수를 k라 하자.
이미지(x_i)를 1차원으로 flattening 하면 D x 1의 matrix가 된다.
W는 이미지에 대한 weight matrix이며, k x D 의 형태를 가진 matrix 이다.
b는 이미지와 직접적인 상호작용을 하진 않지만 결과에 영향을 주는 bias vector이다.
- 학습을 할 때에는 W와 b가 업데이트 되고,
- 테스트를 할 때에는 업데이트된 W와 b로 구성된 함수 f에 x_i를 넣어서 분류 결과를 내보낸다.
- kxD * Dx1 + kx1 이므로 kx1의 벡터가 결과로 산출된다.
- 이 함수는 이미지에 대한 classfication score function이라고 볼 수 있다.
 이미지를 stretch하여 x_i에 넣고, 함수 f를 수행한 예시이다. 각 클래스에 해당하는 score 값들로 구성된 열벡터가 결과로 나온다. 위의 경우는 cat score가 -96.8인데에 비해 dog score를 437.9로 가장 유력하게 평가하였으므로 W와 b가 잘 학습되지 않았음을 의미한다.
이미지를 stretch하여 x_i에 넣고, 함수 f를 수행한 예시이다. 각 클래스에 해당하는 score 값들로 구성된 열벡터가 결과로 나온다. 위의 경우는 cat score가 -96.8인데에 비해 dog score를 437.9로 가장 유력하게 평가하였으므로 W와 b가 잘 학습되지 않았음을 의미한다.
Linear classifier
이미지를 펼치면 (flatten) Dx1 이 되고, 이는 D차원 상에 위치한 한 점이라고 볼 수 있다.
f=Wx+b에서 x가 D차원 공간에서의 점이라면
f, 즉 classfication score vector는 D차원 공간에서의 선형 함수가 된다.
위의 이미지는 이러한 선형 함수들을 그린 것이다. 각 함수에 그려진 화살표는 증가 방향을 의미하므로, 화살표가 가리키는 방향에 위치한 이미지들과 그렇지 않은 이미지로 분류하는 함수임을 의미한다.
이런 관점에서 본다면 W는 함수의 기울기, b는 이동에 관여한다고 해석할 수도 있다.

위의 사진들은 W를 이미지화 한것이다. 각 이미지들은 해당 클래스의 특징을 다소 추상적으로 포함하고 있는데, 예를 들면 horse는 말의 머리가 양쪽으로 나와있고 car는 여러 자동차가 가지고 있는 다양한 색과 방향의 특징을 포함하고 있다. 계속해서 x에 이미지를 넣어 W를 업데이트 할수록 해당 클래스의 특징을 W로 일반화 시킬 수 있을 것이다.
Bias trick
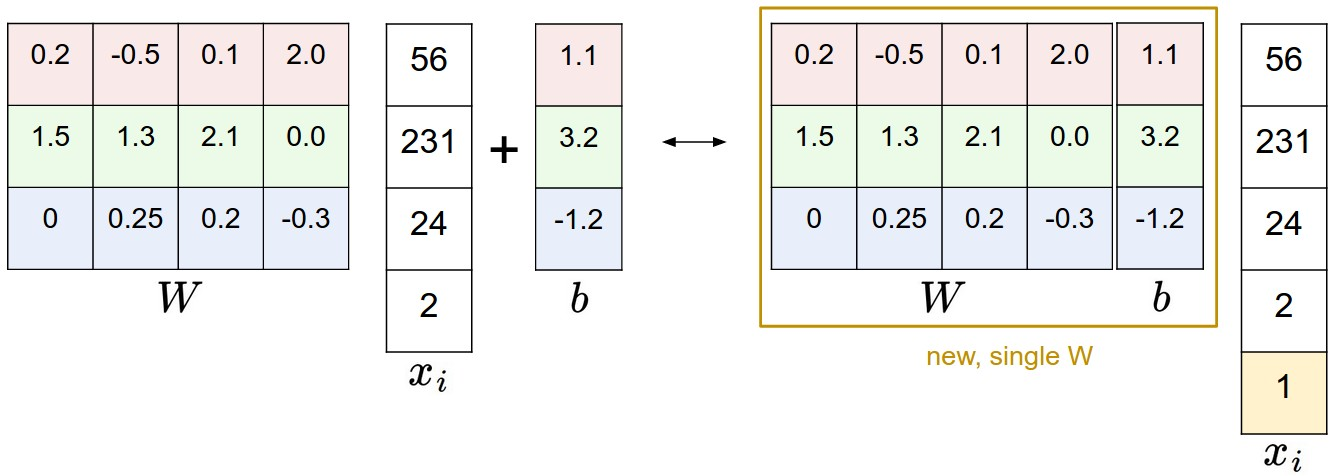 이미지에 1차원만 추가한다면, bias vector를 위와 같이 W에 넣을 수도 있다. 이 트릭을 사용하면 W와 b가 아닌 W만 학습하면 된다.
이미지에 1차원만 추가한다면, bias vector를 위와 같이 W에 넣을 수도 있다. 이 트릭을 사용하면 W와 b가 아닌 W만 학습하면 된다.
데이터 전처리
참고로 위의 예에서는 raw pixel value의 범위가 0~255인데 머신러닝에서는 이러한 입력 값을 정규화 시키는 것이 유리하다. [-127, 127] 로 zero mean centering을 수행하고, 여기에서 [-1, 1]로 입력 pixel value의 범위를 조정할 수 있다.
Loss Function
우리는 이제까지 score function에 대하여 배웠다. 우리는 특정한 이미지를 함수에 넣어서 W, b 와의 상호작용을 통해 classfication score를 얻어낼 수 있다.
이제는 W를 업데이트하기 위하여 정답에 비해 얼마나 틀렸는 지를 평가하는 loss function에 대해 알아보자.
Multiclass Support Vector Machine
SVM을 통해 loss function을 정의해본다면 다음과 같을 것이다.
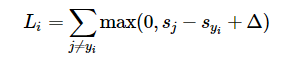
정답 클래스를 제외한 각 클래스의 score에서 정답 클래스의 score를 빼서 delta 만큼 더한 각각의 값(음수인 경우 = 0)을 모두 더 한 값이 loss라고 할 수 있다.
s = [13, -7, 11] 이고 true class는 0번째라고 한다면 loss는 다음과 같다.
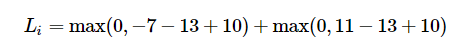
좌측 항에서 1번 클래스의 score(-7)에서 0번 클래스의 score(-13)를 빼면 -20이 되고, 여기에 delta=10을 더한다고 해도 -10 으로 여전히 음수이므로 최종 값은 0이 된다.
우측 항에서 2번 클래스의 score(11)에서 0번 클래스의 score(13)을 빼면 -2이지만, delta=10을 더하는 순간 8이 되어 최종 값은 8이 된다.
두 값을 더하면 0 + 8이므로, 최종 loss는 8이다.
즉, 이 loss function은 정답 클래스의 점수가 다른 클래스의 점수보다 최소한 10만큼은 커야한다는 의미를 내포하고 있다. 그렇지 않으면 각 항에서의 loss가 점차 누적될 것이다.

참고: max(0,−) 는 종종 hinge loss라고도 불리며, 결과 값이 항상 0이상이 되도록 하는 함수이다.
Regularization
모든 샘플에 대해 정확히 분류하는 W가 있다고 해보자. 이러한 W는 수도 없이 많을 것이며, unique하지 않으므로 해가 지나치게 많아진다는 단점이 있다. 왜냐하면 W에 스칼라 배수를 취한다고 해도 score는 균등하게 늘어날 것이고, 역시 모든 샘플을 정확히 분류할 것이다.
이러한 모호성을 줄이기 위해 loss function에 L2 norm으로 구성된 regularization penalty 항을 추가할 수 있다.
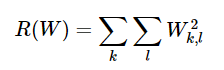
weight matrix (W)의 모든 element를 제곱하여 더하면 가 된다.
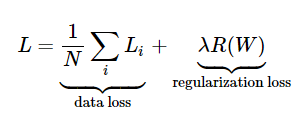
에 임의의 값을 곱하여 기존 loss function에 더해주면 정규화 패널티가 포함된 새로운 loss function이 된다.
기존 loss function은 오로지 data loss만 고려하였으므로 데이터를 잘 분류할 수 있도록 하는 데에만 치중된 방식이다.
반면에 정규화 패널티가 추가된 새로운 loss function은 W에 outlier noise가 많을수록 R을 증가시켜서 결과적으로 loss를 증가시키므로 overfitting을 방지하는 데에도 도움을 준다.
w1=[1,0,0,0] , w2=[0.25,0.25,0.25,0.25] 라고 해보자.
각 w에 위에서 정의한 즉, L2 loss를 적용해보면 w1은 1, w2는 0.25가 된다.
두 w 모두 element를 다 더 해보면 결국 1이지만, loss는 w2가 더 작은 값이 나왔다.
w2는 값이 더욱 분포되어 있고, 각각의 값이 한 쪽으로 몰린 경우보다 더 작은 값들로 구성된다.
이런 특성에 의해 R은 입력 데이터의 특정 값이 아닌 전체 데이터를 골고루 반영할 수 있게 하며, 일반성을 높이고 결국 overfitting을 방지하도록 도와준다는 것을 알 수 있다.
참고: binary classfication의 경우 클래스가 단 2개이므로 다음과 같이 식을 단순화 할 수도 있다.
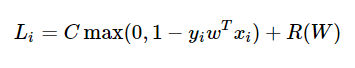
Softmax Classifier
각 score를 unnormalized log probability로 해석하고, cross entropy loss를 활용한다면, 전체 loss는 각 샘플 데이터에 대한 정규화 항 을 포함한 의 평균과 같다.

아래와 같은 함수를 softmax function이라 하는데, score vector를 입력받아서 벡터 내 원소 값을 0~1 사이로 바꾸고 합이 1이 되게 한다.
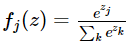
softmax classifier는 참 값에 해당하는 분포 p와, 예측 값에 해당하는 분포 q의 cross-entropy를 최소화 한다.
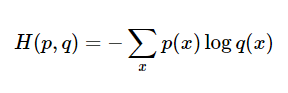
SVM vs Softmax
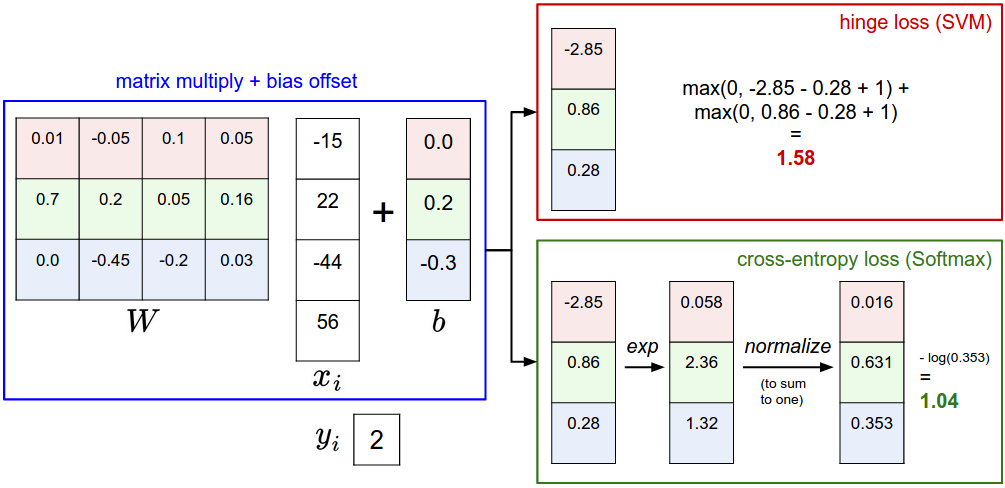
위의 그림을 보면 두 loss function의 동작 방식을 이해할 수 있다.
두 경우 모두 동일한 스코어 벡터 f를 계산하지만, softmax가 SVM과 구별되는 가장 큰 차이점은 각 클래스의 예측 결과를 확률 값으로 산출한다는 것이다.