기본 개념
편미분
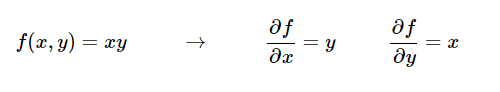 두 변수의 곱으로 이루어진 함수에서 각 변수에 대한 편미분은 다음과 같다.
두 변수의 곱으로 이루어진 함수에서 각 변수에 대한 편미분은 다음과 같다.
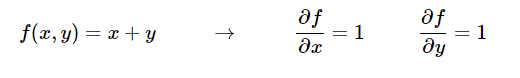 두 변수의 합으로 이루어진 함수에서 각 변수에 대한 편미분은 다음과 같다.
두 변수의 합으로 이루어진 함수에서 각 변수에 대한 편미분은 다음과 같다.
Chain Rule
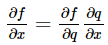
f(q), q(x) 에 대한 합성 함수인 f(x) 에 대해 미분을 취할 때 chain rule을 이용하여 계산할 수 있다.
backpropagation 예제 1
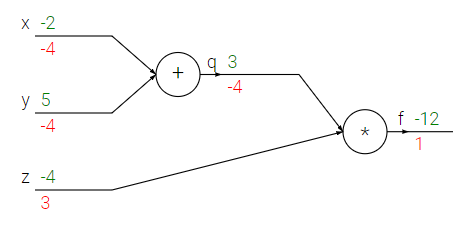 위의 예시를 다뤄보자. 우선 녹색으로 표기된 숫자들은 forward pass에 의한 결과 값들을 의미한다. 즉, 입력 값과 연산자를 이용해서 출력 값을 전방으로 보내는 것이다. x(-2) + y(-5) = q(3) 이며, q(3) * z(-4) = f(-12) 임을 알 수 있다.
위의 예시를 다뤄보자. 우선 녹색으로 표기된 숫자들은 forward pass에 의한 결과 값들을 의미한다. 즉, 입력 값과 연산자를 이용해서 출력 값을 전방으로 보내는 것이다. x(-2) + y(-5) = q(3) 이며, q(3) * z(-4) = f(-12) 임을 알 수 있다.
붉은 색으로 표기된 숫자들은 backward pass에 의한 gradient들을 의미하는데, 이 값들이 어떻게 도출되는지 계산해보자.
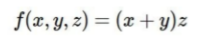 회로도를 함수 형태로 바꾸면 위와 같이 표현되고, 결국 우리가 원하는 값은 최종 output으로부터 각 input 값에 대한 gradient인 , , 이다.
회로도를 함수 형태로 바꾸면 위와 같이 표현되고, 결국 우리가 원하는 값은 최종 output으로부터 각 input 값에 대한 gradient인 , , 이다.
 기본 개념에서 배운 공식에 의해 위와 같은 중간 결과들을 도출할 수 있다.
기본 개념에서 배운 공식에 의해 위와 같은 중간 결과들을 도출할 수 있다.
q = x + y 이므로 q의 각 변수에 대한 편미분은 둘 다 1이 된다.
f = qz 이므로 f의 각 변수에 대한 편미분은 다른 하나의 변수값이 된다.
각 노드에서의 gradient 계산
- df/df = 1 (자기 자신에 대한 gradient)
- df/dq = z = -4
- df/dz = q = 3
- df/dx = = z * 1 = -4 (체인 룰에 의해)
- df/dy = = z * 1 = -4 (체인 룰에 의해)
위의 계산을 통해 예시에 나온 backward pass의 gradient 들을 모두 계산할 수 있었다.
backpropagation 예제 2
추가적인 기본 개념
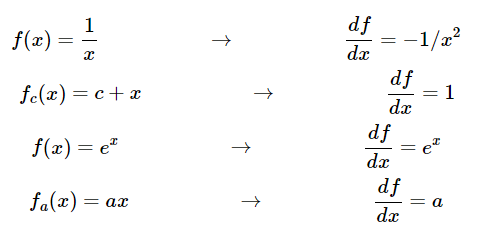 이제는 위와 같은 공식들이 추가로 필요하기 때문에 미리 알아두자.
이제는 위와 같은 공식들이 추가로 필요하기 때문에 미리 알아두자.
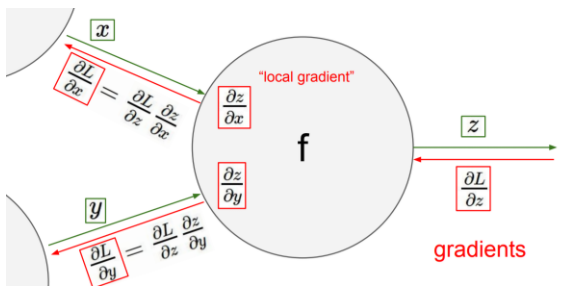 또한 앞으로 출력 부에서 backward pass되는 gradient를
또한 앞으로 출력 부에서 backward pass되는 gradient를 upstream gradient(위의 그림에서 gradients), 출력 부에서 입력 부를 편미분 한 값을 local gradient라고 명명하자.
sigmoid example
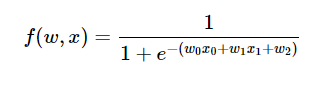 위와 같은 시그모이드 함수의 각 게이트에 대해 역전파를 수행해보자.
위와 같은 시그모이드 함수의 각 게이트에 대해 역전파를 수행해보자.
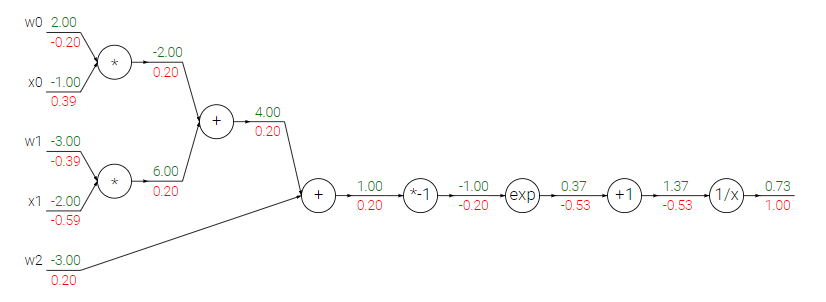 마찬가지로 forward pass output들과 gradient들이 표기되어 있다.
마찬가지로 forward pass output들과 gradient들이 표기되어 있다.
제일 뒤 쪽에 있는 output부터 계속해서 upstream gradient * local gradient를 수행하여 각 노드에서의 gradient를 구해보자.
- 1/x 노드
upstream gradient = 1
local gradient = 에 대한 미분 = = = -0.53
gradient = 1 * -0.53 = -0.53- +1 노드
upstream gradient = -0.53
local gradient = x+1에 대한 미분 = 1
gradient = -0.53 * 1 = -0.53- exp 노드
upstream gradient = -0.53
local gradient = 에 대한 미분 = = = 0.367
gradient = -0.53 * 0.367 = -0.2- 노드
upstream gradient = -0.2
local gradient = 에 대한 미분 = 1 * (-1) = -1
gradient = 0.2- 그 외의 노드들
나머지 노드들은 예제 1에서 했던 것과 같은 작업을 수행해주면 된다.
합연산의 경우 local gradient = 1이므로 gradient = upstream gradient 이고, 즉 +에 걸려있는 input들의 gradient는 모두 0.2가 된다.
곱연산의 경우 local gradient는 다른 하나의 변수값이므로 gradient = upstream gradient와 다른 한쪽 변수의 입력값의 곱이 될 것이다.