
해당 강의는 미래연구소 15기에서 진행한 내용입니다 :)
https://futurelab.creatorlink.net/
지난주 과제 코드 : https://github.com/jjaekkaemi/deeplearning/blob/main/Week%202%20Assignment.ipynb
Numpy
다 외우는 것이 아니라 필요한 함수를 찾아서 사용하는 것이 중요
1. shift+tab
2. np.lookfor
3. numpy 공식 사이트 이용
4. 구글링
사용될 함수들
- numpy.exp : x라는 nd array의 원소들을 e^x로 바꿈
- numpy.zeros : 원하는 shape에 맞는 영행렬 생성
- numpy.ndarray.shape : nd array의 shape을 return 한다.
- numpy.arange : np.arange(stop), np.arange(start, stop), np.arange(start, stop, step) 필요한 범위 내에서 array 생성
- numpy.ndarray.reshape : X라는 nd array를 내가 원하는 shape에 맞게 재배열
- numpy.sum : nd array의 원소의 합.
- numpy.ndarray.T : X라는 nd array의 transpose를 구함.
- numpy.multiply : x1, x2라는 nd array끼리 element-wise product
Broadcasting
- broadcast : '퍼뜨리다' -> '방송하다'
- 행렬 연산 시 shape이 맞지 않아도 연산할 때 shape이 작은 array가 알아서 큰 array의 shape에 맞게 확장되는 것.
2주차 핵심 내용
1. Neural Network 작동원리
- Initiallization : w, b 초기값
- Forward Propagation : sigmoid 함수 적용
- Compute Cost : binary cross entropy loss = cost 줄이기
- Backward Propagation : Gradient 하기 전에 필요
- Gradient Descent : w 값을 계속 업데이트
2. Vectorization
- 단점 : Neural Network를 사용할 때 for loop 사용
- numpy로 연산 시간을 줄이는 것.
Neural Network 에 Vectorization 적용
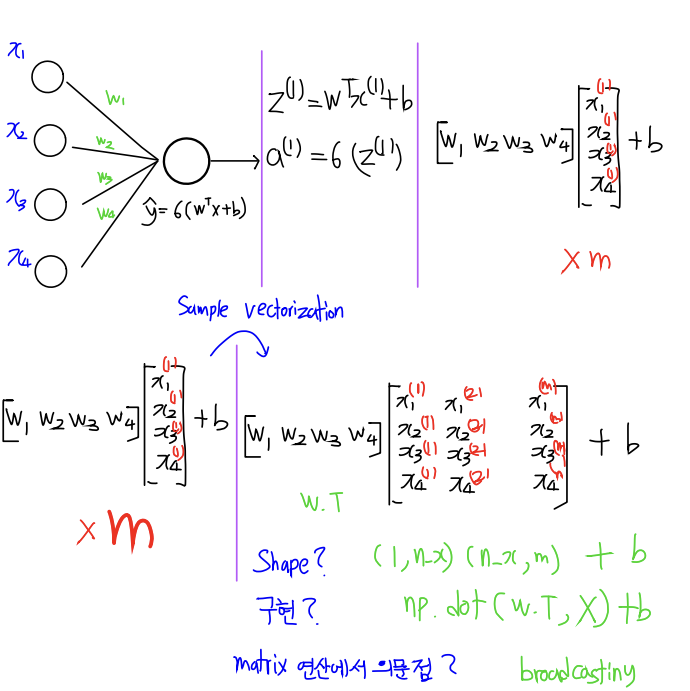
1. propagation 할 때 행렬 x를 각각의 training 데이터로 다른 열에 쌓아 나가는 것으로 정의한다. (n(x),m)
2. W^TX+b 계산 (for loop를 적용할 경우 x(1), x(2) 로 m개씩 연산해야 함. 계산하는 과정에서 소문자 x들을 수평으로 세워놓으면 X로 나타낼 수 있다.) -> 이를 numpy로 표현하면 numpy.dot(W^T,X)가 된다. b는 실수로 1 1의 행렬인데 1 b로 broadcasting 되어 계산.
3. 시그모이드 함수를 사용하여 (이때도 numpy.exp를 사용한다.) 예측 y를 생성한다.

- 중요한 건 3번 loss에서 대해 w를 미분한 걸 알고 싶은 것
- 이러한 과정의 반복을 줄이기 위해 vectorization 사용.

- Backward Propagation, Gradient Descent 과정.
- 합성 함수의 미분으로 각 계산 과정을 값으로 나타낸 것.
- cost에 대해 w를 미분하는 것이 목표 -> 첫번째 gradient 부터 m번째 gradient의 평균!

- 코드로 표현하면 오른쪽으로 나타낼 수 있다.
Node와 layer
- node를 증가 시키고, layer를 증가시키면 정확도가 커질 수 있다.
- node를 증가 시키면 행이 많아 지는 것.
- layer가 늘어나는 건 내부가 깊어지는 것.
- 현재까지 배운 것은 w가 한줄, node가 늘어나면 w의 행도 증가 -> 연산량이 많아질 것.

- training set 내에서 hidden layer 는 보이지 않음.
- input layer - a[0]=X
- hidden layer - a[1]
- output layer - y^ = a[2]=a

vis ta vie