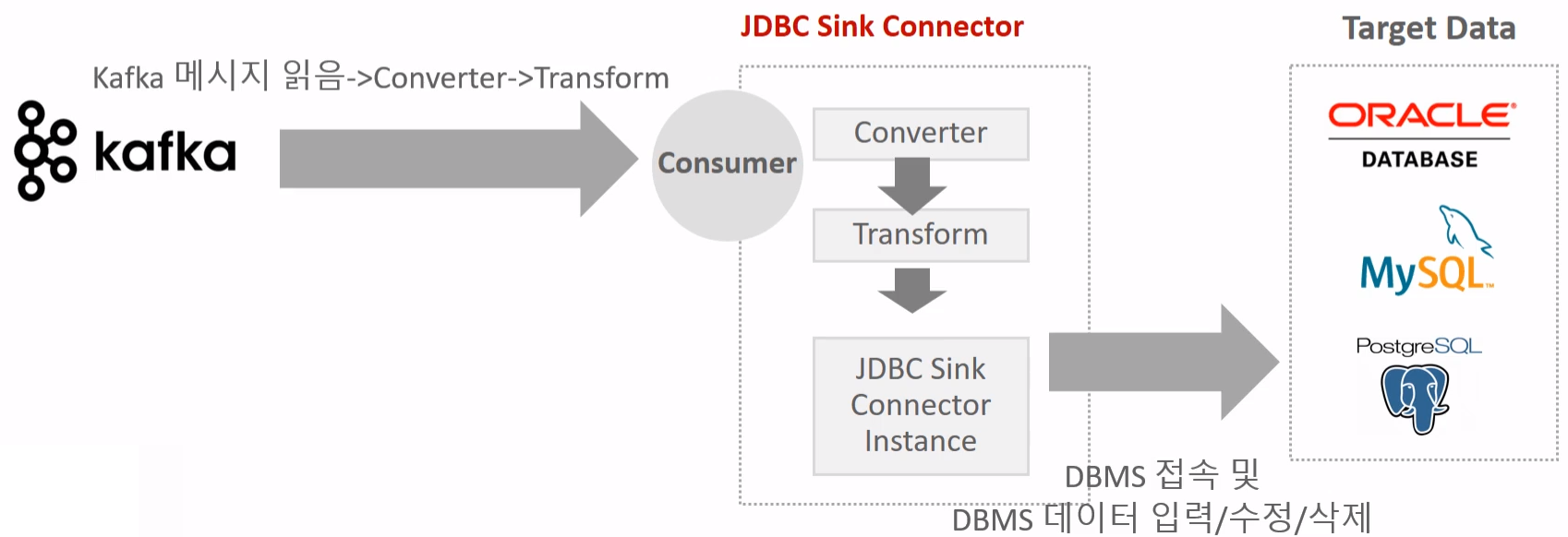
JDBC Sink Connector는 Kafka의 메시지를 RDBMS에 적재하기 위한 Sink Connector다.
Kafka Consumer 역할을 수행하면서 Kafka 토픽의 데이터를 읽고, JDBC Driver를 이용해 대상 데이터베이스 테이블에 Insert, Update, Delete를 수행한다.
데이터 파이프라인의 종착지 역할을 하며, Kafka에서 처리된 이벤트를 최종적으로 DB에 저장하거나 상태를 동기화할 때 사용된다.
Config
아래는 일반적으로 사용되는 JDBC Sink Connector 설정 예시다.
{
"name": "jdbc-sink-om",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "mysql_om_customers",
"connection.url": "jdbc:mysql://localhost:3306/om_target",
"connection.user": "connect_dev",
"connection.password": "connect_dev",
"auto.create": "true",
"auto.evolve": "true",
"insert.mode": "upsert",
"pk.mode": "record_value",
"pk.fields": "customer_id",
"delete.enabled": "true",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": true
}
}주요 파라미터 설명
-
connector.class: JDBC Sink Connector 클래스 지정 -
tasks.max: 생성할 최대 Task 개수 -
topics: 적재 대상 Kafka Topic -
connection.url,connection.user,connection.password: DB 접속 정보 -
auto.create: 테이블 자동 생성 여부 (비추천) -
auto.evolve: 스키마 변화(column 추가 등) 자동 반영 여부 -
insert.mode: DB 적용 방식 (insert,update,upsert) -
pk.mode: Primary Key 추출 방식 (record_key,record_value,none) -
pk.fields: Primary Key로 사용할 필드명 -
delete.enabled: Kafka 메시지 value가 null일 때 Delete 수행 여부 -
value.converter.schemas.enable: 메시지에 Schema 포함 여부(DB 컬럼 타입 매핑 시 필수)
Update
Update는 Primary Key가 존재해야만 가능하다.
JDBC Sink Connector는 PK를 기준으로 메시지를 DB 행과 매칭하고, 존재하면 Update를 수행한다.
Insert 모드와 관계없이, Update 동작의 기반은 다음 두 가지이다:
- PK 매핑 (레코드의 Key 또는 Value에서 추출)
- 메시지 필드를 컬럼에 맵핑하는 Schema
Upsert
가장 많이 사용하는 방식이다.
- PK와 매칭되는 행이 DB에 없으면 → Insert
- PK와 매칭되는 행이 DB에 있으면 → Update
Kafka 메시지 (update 와 insert시 메세지는 같아보인다.)
{
"payload": {
"customer_id": 1,
"full_name": "testuser_01_updated",
"email_address": "update_email@test.com"
}
}Delete
Delete 처리 방식은 delete.enabled=true 설정과 Value = null 여부에 따라 결정된다.
조건
- Kafka 메시지의 value가 null이어야 한다.
delete.enabled=true이어야 한다.- PK가 설정되어 있어야 한다.
예: Kafka 메시지(Delete 이벤트)
key: {"customer_id": 1}
value: null날짜·시간 관련 데이터 변환
JDBC Sink Connector는 Kafka 메시지에 포함된 날짜·시간 타입을 DB에 적재하기 위해 내부적으로 Connect Schema Type → JDBC 타입 변환을 수행한다.
이때 변환은 Unix Epoch(1970-01-01 00:00:00 UTC)를 기준으로 한 값으로 처리된다.
DATE
- Connect 타입:
org.apache.kafka.connect.data.Date - 내부 표현: INT32
- 변환 방식: 날짜(Date) 값에서 Unix epoch(1970-01-01)까지의 일(day) 단위 차이를 정수로 변환하여 전달한다.
TIME
- Connect 타입:
org.apache.kafka.connect.data.Time - 내부 표현: INT64
- 변환 방식: 시간(Time) 값을 자정(00:00:00)을 기준으로 microseconds 단위의 경과 시간으로 변환한다.
DATETIME
- Connect 타입:
org.apache.kafka.connect.data.Timestamp - 내부 표현: INT64
- 변환 방식: datetime 값에서 Unix epoch까지의 차이를 밀리초(milliseconds) 단위 정수로 변환한다.
TIMESTAMP
- Connect 타입:
org.apache.kafka.connect.data.Timestamp - 내부 표현: INT64
- 변환 방식: DATETIME과 동일하며 Unix epoch까지의 차이를 밀리초(milliseconds) 단위로 변환하여 전달한다.
Kafka 메시지
{
"schema": {
"type": "struct",
"fields": [
{
"field": "system_upd",
"type": "int64",
"name": "org.apache.kafka.connect.data.Timestamp"
}
]
},
"payload": {
"system_upd": 1763018927310
}
}