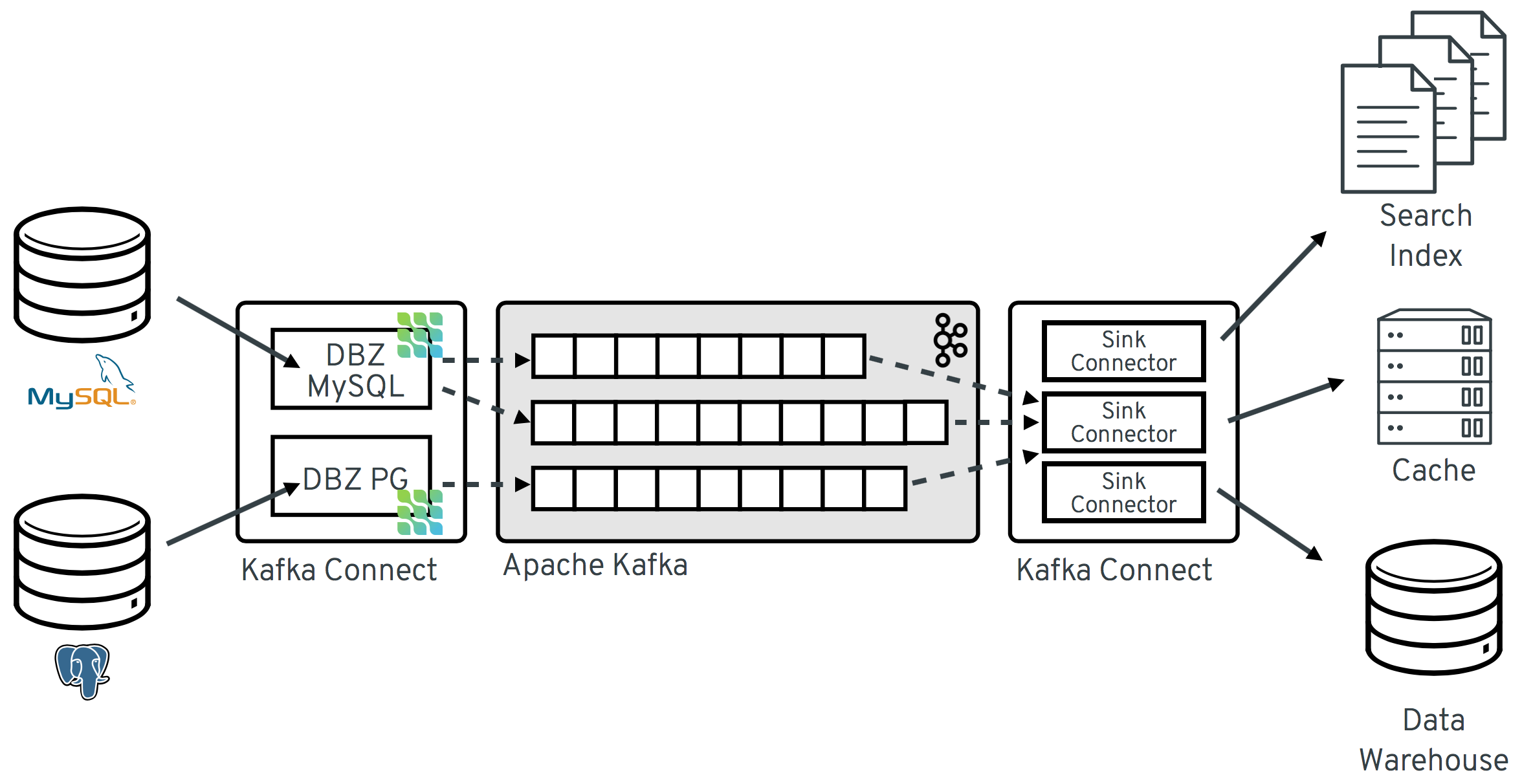
CDC(Change Data Capture)
CDC는 데이터베이스에서 발생하는 Insert Update Delete와 같은 변경 사항을 실시간에 가깝게 감지해서 외부 시스템으로 전달하는 기술이다.
일정 주기마다 전체 테이블을 조회하는 방식이 아니라 데이터베이스 내부의 트랜잭션 로그를 읽어서 변경된 데이터만 추출한다.
이 덕분에 원본 DB에 주는 부하는 적고 변경 이력은 빠르게 외부로 흘려 보낼 수 있다.
CDC & Replication
복제는 데이터베이스 간 데이터를 동일하게 맞추는 것이 목적이다.
주로 장애 대비나 읽기 부하 분산을 위해 사용하고 동일한 데이터를 다른 DB 인스턴스에 그대로 복사한다.
CDC는 데이터 그 자체보다 변경 행위에 초점을 둔다.
어떤 row가 생성되었는지 어떤 값으로 수정되었는지 어떤 row가 삭제되었는지를 이벤트 형태로 외부로 내보낸다.
정리하면
- Replication은 DB 간 동기화와 복제를 위한 기술
- CDC는 변경 이력을 이벤트 스트림으로 만드는 기술
log 기반 CDC
로그 기반 CDC는 데이터베이스가 내부적으로 유지하는 트랜잭션 로그를 읽어 변경 사항을 추출하는 방식이다.
로그에는 Insert Update Delete가 어떻게 수행되었는지가 기록되며 CDC 시스템은 이 로그를 분석해 실제로 어떤 레코드가 어떻게 바뀌었는지 확인한다.
로그 기반 CDC에서 자주 등장하는 개념은 다음과 같다.
-
Statement 기반
실행된 SQL 문장을 로그에 기록한다. 예를 들어UPDATE orders SET status = 'DONE' WHERE id = 10같은 형태가 로그에 남는다.
어떤 컬럼의 값이 어떻게 바뀌었는지 직접적으로 드러나지 않고 조건에 따라 결과가 달라질 수 있어 재현성이 떨어진다. -
Row 기반
변경된 레코드 값을 통째로 로그에 기록한다.
Insert는 after 값만 Update는 before와 after 값을 모두 Delete는 before 값만 기록한다.
Debezium 같은 CDC 도구는 이 Row 기반 로그를 읽어서 변경 메시지를 만든다.
Row 기반 로그는 어떤 컬럼까지 포함할지에 따라 보통 다음과 같이 나뉜다.
-
full
레코드의 모든 컬럼을 그대로 기록한다. -
minimal
PK와 변경에 필요한 컬럼만 기록한다. -
noblob
full과 비슷하지만 용량이 큰 blob text 컬럼은 제외한다.
Debezium Source Connector
Debezium은 로그 기반 CDC를 Kafka Connect Source Connector 형태로 구현한 오픈소스 프레임워크다.
MySQL PostgreSQL Oracle SQL Server 등 다양한 DB의 트랜잭션 로그를 읽어서 Kafka 토픽으로 변경 이벤트를 보낸다.
JDBC Source Connector와 비교하면 다음과 같은 차이가 있다.
- JDBC Source는 주기적으로 테이블을 조회하는 polling 방식이다.
- Debezium은 트랜잭션 로그를 직접 읽는 log 기반 방식이다.
그래서 Debezium은
- 원본 DB 부하가 상대적으로 적고
- Insert Update Delete를 모두 안정적으로 감지하고
- 변경 전(before)과 변경 후(after)를 함께 전달할 수 있고
- 오프셋을 기반으로 재시작 시점도 맞출 수 있다.
Config
{
"name": "mysql_cdc_oc_source",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "192.168.56.101",
"database.port": "3306",
"database.user": "connect_dev",
"database.password": "connect_dev",
"database.allowPublicKeyRetrieval": "true",
"database.server.id": "184054",
"database.server.name": "mysql_oc",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.mysql_oc",
"table.include.list": "om.orders,om.order_items",
"include.schema.changes": "true",
"decimal.handling.mode": "precise",
"time.precision.mode": "connect",
"database.connectionTimeZone": "Asia/Seoul",
"snapshot.mode": "initial"
}
}-
name: Connector 이름 -
connector.class: 사용할 Debezium Connector 클래스 -
tasks.max: 생성할 Task 최대 개수 -
database.hostname: CDC 대상 MySQL 서버 주소 -
database.port: MySQL 포트 -
database.user: Binlog 읽기 권한이 있는 사용자 -
database.password: 위 사용자 비밀번호 -
database.allowPublicKeyRetrieval: MySQL 8 환경에서 public key를 획득하도록 허용 -
database.server.id: Replication용 server id -
database.server.name: Kafka 토픽 prefix가 되는 논리적 서버명 -
database.history.kafka.bootstrap.servers: 스키마 변경 이력을 저장할 Kafka 브로커 -
database.history.kafka.topic: 스키마 변경 이력 저장 토픽 -
table.include.list: CDC 대상 테이블 목록 -
include.schema.changes: 테이블의 DDL 변경 사항을 Kafka로 전송 -
decimal.handling.mode: decimal의 precision scale 유지 방식 -
time.precision.mode: 시간 타입의 정밀도 표현 방식 -
database.connectionTimeZone: 날짜 시간 해석 기준 타임존 -
snapshot.mode: Snapshot 초기 수행 방식
특징
-
하나의 Source Connector로 여러 테이블을 추출할 수 있다.
-
하나의 테이블은 하나의 Topic으로 생성된다.
-
Source 테이블의 PK는 자동으로 Kafka 메시지의 Key로 생성된다.
-
토픽 이름은 기본적으로
database.server.name.database.table형식이다. -
SMT를 통해 토픽 이름을 변경할 수 있다.
-
Source 테이블의 DDL 변경 사항을 Kafka에 저장한다.
-
메시지는 JDBC Source와 다르게 before after 구조다.
-
JDBC Sink Connector에서 사용하려면 SMT로 after-only 형태로 바꾸어야 한다.
-
tombstone 메시지 생성을 위해 SMT를 설정해야 한다.
-
date datetime numeric decimal 등은 Sink가 이해할 수 있는 타입으로 변환해야 한다 .
Debezium 메시지 예시
{
"before": {
"order_id": 1001,
"status": "READY"
},
"after": {
"order_id": 1001,
"status": "SHIPPED"
},
"op": "u",
"ts_ms": 1710000000100
}메시지 구조는 다음과 같다.
- Insert는 before는
null메세지는 after만 존재한다 - Update는 before와 after가 존재한다
- Delete는 before만 존재하고 이후 tombstone 메시지가 추가될 수 있다
Debezium & SMT
JDBC Sink Connector와 연동하기 위해서는 Debezium 메시지를 after-only 형태로 바꾸는 것이 일반적이다.
가장 많이 사용하는 SMT는 ExtractNewRecordState이다.
{
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"transforms.unwrap.delete.handling.mode": "rewrite"
}SMT 적용 후 메시지는 다음과 같이 변환된다.
{
"order_id": 1001,
"status": "SHIPPED"
}Snapshot
snapshot.mode = initial
- 최초 실행 시 대상 테이블 전체를 Snapshot으로 읽어 Kafka에 전송한다
- Snapshot 종료 후에는 Binlog를 기반으로 이벤트만 전송한다
snapshot.mode = schema_only
- 테이블 레코드를 읽지 않고 스키마 정보만 저장한다
- 기존 데이터는 별도 파이프라인으로 적재하고 Connector 생성 이후 변경된 이벤트만 Debezium이 처리한다
