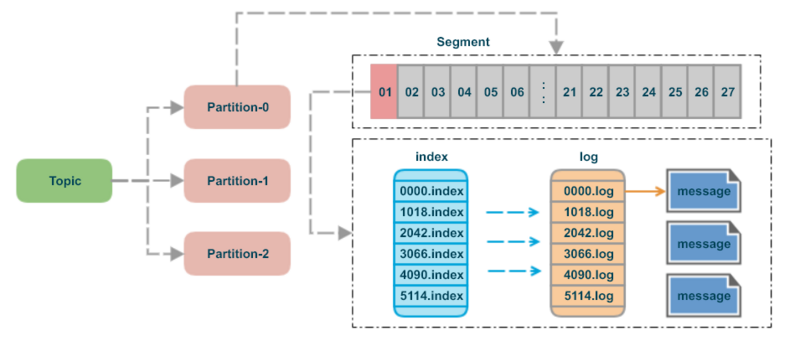
Segment
Kafka는 데이터를 파일 시스템에 저장할 때, 각 파티션을 여러 개의 segment로 나누어 관리한다.
하나의 파티션에는 오직 하나의 active segment만 존재하며 이 Segment에만 새로운 데이터가 write된다. 나머지 Segment는 closed 상태로 전환되어 read-only가 된다.
Kafka는 Segment를 주기적으로 rolling하여 파일 크기를 관리한다.
Segment가 너무 커지면 조회 성능이 저하되고 너무 작으면 파일 수가 많아져 관리 오버헤드가 커지므로 균형을 위해 두 가지 기준으로 롤링이 발생한다.
-
지정된 크기(
log.segment.bytes)를 초과하면 새로운 세그먼트를 생성한다. -
지정된 시간(`log.roll.hours(ms))을 초과하면 데이터 크기와 상관없이 새로운 세그먼트로 전환된다.
즉, 설정값만큼의 용량 또는 시간 중 하나라도 초과되면 롤링이 발생하여 기존 Segment는 닫히고 새 Segment가 활성화된다.
Segment & Index & TimeIndex
Kafka의 각 파티션 디렉토리에는 세 가지 주요 파일이 존재한다.
- Segment (.log)
- 메시지 본문이 저장되는 파일이다. offset 순서대로 데이터가 기록된다.
- Index (.index)
- 특정 offset의 데이터가 Segment 파일 내에서 몇 바이트 위치에 저장되어 있는지(byte position)를 기록한다.
- 모든 offset이 아니라,
log.index.interval.bytes설정값마다 주기적으로 인덱스를 생성한다.
- TimeIndex (.timeindex)
- 메시지의 생성 시간을 밀리초 단위의 Unix Timestamp로 기록하며 해당 시간에 대응되는 offset 정보를 저장한다.
이 세 가지 파일 덕분에 Kafka는 대용량 로그 중에서도 특정 시간대나 특정 offset의 메시지를 빠르게 조회할 수 있다.
Segment Lifecycle
Kafka의 Segment는 다음과 같은 단계를 거친다:
Active → Closed → Deleted / Compacted
-
새 메시지는 항상 Active Segment에 기록되며 용량 또는 시간이 초과되면 Closed 상태로 변경된다.
-
이후 브로커의 Log Cleanup 정책(
log.cleanup.policy)에 따라 삭제되거나 압축(compaction)된다.
Kafka는 오래된 데이터를 관리하기 위해 log.cleanup.policy를 다음과 같이 지정한다.
-
delete: Segment를 주어진 보존 시간(log.retention.hours)이나 저장 용량(log.retention.bytes) 기준을 초과하면 삭제한다.
-
compact: 각 키(key)에 대해 최신 메시지만 남기고 이전 데이터는 제거한다. -
[delete, compact]: 두 정책을 함께 적용한다.
또한, 브로커는 백그라운드에서 주기적으로 Segment 삭제 대상을 검색하며
그 주기는 log.retention.check.interval.ms 설정으로 제어된다.
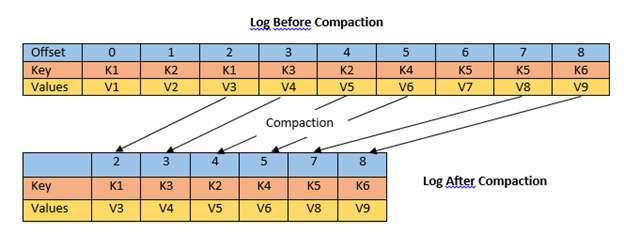
Log Compaction
log.cleanup.policy=compact로 설정된 토픽에서는 Log Compaction이 수행된다.
이는 같은 Key를 가진 메시지 중 가장 최신 값만 남기고 이전 값은 제거하는 방식으로 토픽의 크기를 줄이면서도 최신 상태를 유지하도록 설계되었다.
Log Compaction은 다음과 같은 특징을 가진다:
-
Active Segment는 compaction 대상에서 제외된다.
-
Compaction은 파티션 단위로 수행되며, 여러 세그먼트를 다시 생성(rewrite)하는 방식으로 동작한다.
-
Key가 null인 메시지는 compact되지 않는다.
-
별도의 Log Cleaner 스레드가 백그라운드에서 I/O를 수행하며, 추가적인 디스크 부하가 발생할 수 있다.
Compaction이 완료되면 메시지의 순서(offset)는 변하지 않으며 Consumer는 가장 최신 메시지 값만 읽게 된다.
다만 value가 null인 tombstone 메시지는 일정 시간이 지나면 완전히 삭제된다.
Kafka는 compaction 수행 시 dirty 데이터의 비율(dirty / total)이
log.cleaner.min.cleanable.ratio 설정값 이상일 때만 compaction을 수행한다.
