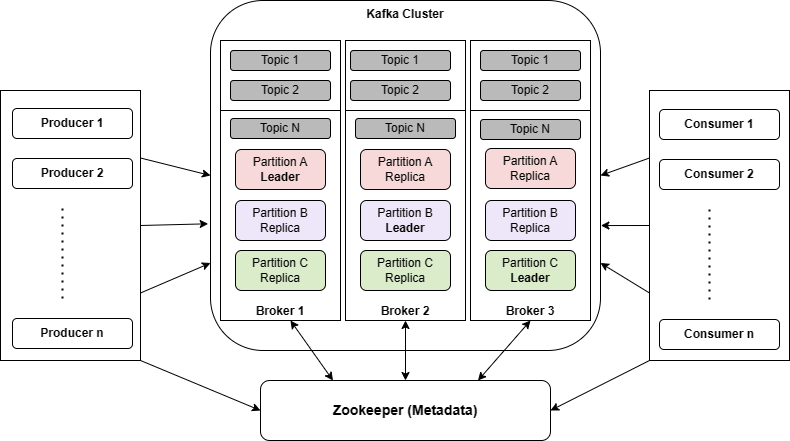
Multi Node Kafka Cluster
Kafka cluster는 여러 대의 Broker Node로 구성되어 있다.
Producer는 bootstrap.servers에 지정된 Broker 리스트 중 하나에 접속하여 Metadata를 가져오고 이후 자신이 전송할 Topic의 Partition Leader가 위치한 Broker로 직접 연결된다.
브로커 간에는 서로의 파티션 및 리더 정보를 공유하며 Cluster의 확장성과 내결함성을 위해 복수의 Broker가 하나의 Topic을 분산 저장한다.
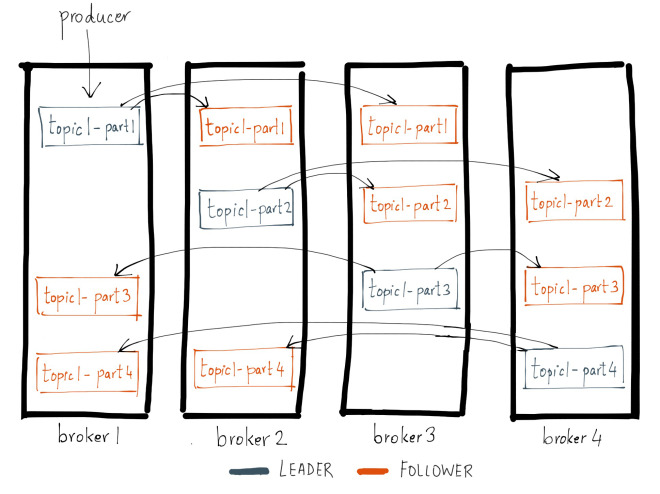
Replication
Kafka는 데이터의 신뢰성을 확보하기 위해 Replication 구조를 사용한다.
각 파티션은 1개의 Leader와 N개의 Follower로 구성되며 replication.factor 값에 따라 복제본이 생성된다.
- Producer와 Consumer는 Leader Partition을 통해서만 쓰기·읽기를 수행한다.
- Follower Partition은 Leader로부터 Fetch 요청을 통해 데이터를 복제한다.
이 구조 덕분에 Leader 장애 시 Follower 중 하나를 새 Leader로 승격시켜 서비스가 지속된다.
ISR (In-Sync Replicas)
ISR은 Leader와 완전히 동기화된 Follower들의 집합이다.
Follower는 Leader에게 Fetch 요청을 보내며 자신이 복제할 offset을 전달한다.
Leader는 Follower의 offset과 자신의 최신 offset을 비교해 Follower가 정상적으로 복제 중인지 판단한다.
min.insync.replicas
min.insync.replicas는 acks=all 모드일 때,
Producer가 메시지를 성공적으로 전송했다고 판단하기 위해 필요한 최소한의 ISR 수를 의미한다.
예를 들어 replication-factor=3, min.insync.replicas=2라면
3개 중 2개의 ISR이 정상적으로 메시지를 복제해야 Producer는 성공 응답(ACK)을 받는다.
이는 데이터 손실을 방지하기 위한 핵심 보장 메커니즘이다.
replica.lag.time.max.ms
Follower가 Leader로부터 데이터를 가져오는 데 허용되는 최대 지연 시간이다.
이 시간 내에 Follower가 데이터를 Fetch하지 못하면 ISR에서 제외된다.
Follower가 너무 느리게 복제하면 "비동기 복제"로 판단되어 데이터 일관성을 보장할 수 없다고 간주된다.
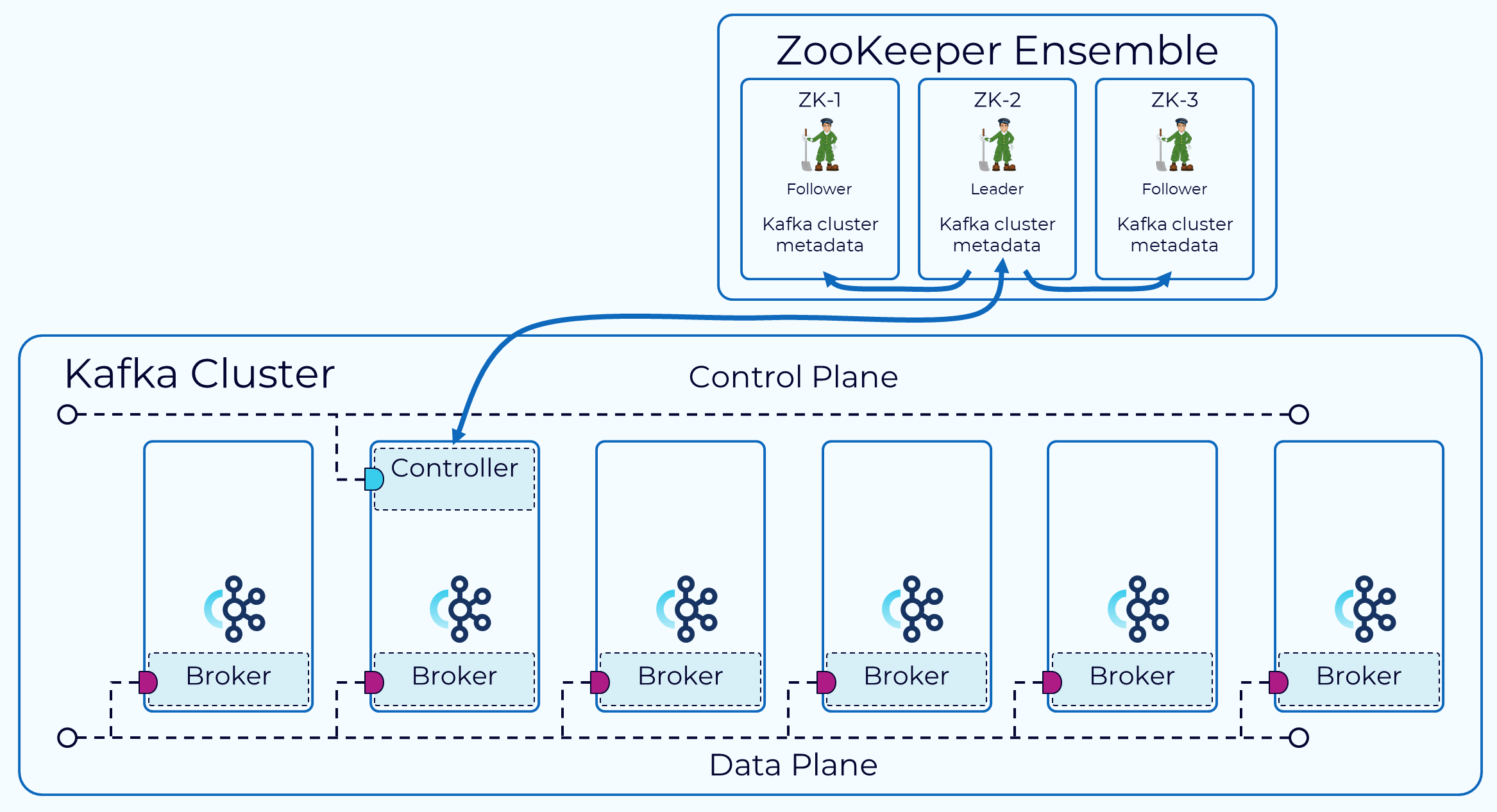
Zookeeper
Zookeeper는 Kafka 클러스터의 Metadata와 상태 정보를 관리하는 Coordination 시스템이다.
역할
- Controller Broker 선출: 가장 먼저 연결된 Broker를 Controller로 지정.
- Broker Membership 관리: Broker의 등록, 해제, 장애 감지를 수행.
- Topic/Partition 정보 관리: Partition 수, replicas 구성 등 Metadata를 유지.
- Watch Event: Broker나 Partition 상태 변경 시 Controller에 즉시 통보.
Heartbeat 및 장애 감지 메커니즘
모든 Kafka Broker는 주기적으로 Zookeeper에 접속하여 Session Heartbeat을 전송한다.
이를 통해 자신의 상태를 지속적으로 보고한다.
zookeeper.session.timeout.ms이내에 Heartbeat을 받지 못하면,
Zookeeper는 해당 Broker의 노드 정보를 삭제하고 Controller 노드에게 변경 사실을 통보한다.- Controller 노드는 다운된 Broker가 관리하던 파티션들에 대해 새로운 Leader 선출(Leader Election) 을 수행한다.
- 만약 다운된 브로커가 Controller였다면 Zookeeper는 즉시 모든 노드에게 그 사실을 알리고 가장 먼저 접속한 다른 브로커가 새로운 Controller가 된다.
이 메커니즘은 Kafka의 고가용성과 빠른 장애 복구를 가능하게 한다.
Controller Broker
Zookeeper에 가장 먼저 접속한 Broker가 Controller 역할을 수행한다.
Controller는 Partition의 Leader 선출 및 Broker 상태 변화를 감시하며 새로운 Leader/Follower 구성을 Zookeeper에 반영한다.
Leader Election 과정
- Zookeeper는 다운된 Broker의 세션이 만료되면 해당 노드를 제거.
- Controller는 Watch Event를 통해 Broker의 Down 정보를 수신.
- 해당 Broker가 관리하던 파티션에 대해 새로운 Leader를 선출.
- 새 Leader/Follower 정보를 Zookeeper에 업데이트하고 관련 Broker에 통보.
- 모든 Broker의 Metadata cache를 갱신하여 최신 리더 정보를 반영.
Preferred / Unclean Leader Election
Preferred
Kafka는 각 파티션의 기본 리더(Preferred Leader) 를 지정한다.
리더 선출 시 가능한 한 Preferred Leader를 선택하여 데이터 분산의 균형과 성능을 유지한다.
leader.imbalance.check.interval.seconds
Preferred Leader의 불균형을 감지하는 주기이다.
auto.leader.rebalance.enable=true 로 설정된 경우 컨트롤러는 이 시간 간격마다 클러스터 내 리더 분포를 점검하고 불균형이 발견되면 Preferred Leader로 리더를 재할당한다.
Unclean Leader Election
만약 모든 ISR이 다운되고 Follower 중 일부만 남아 있다면 Kafka는 unclean.leader.election.enable 설정에 따라 비정상적인 리더 선출을 허용할 수 있다.
- true: ISR 외의 복제본 중 하나를 Leader로 승격 (데이터 손실 위험 존재)
- false: 새 Leader를 선출하지 않음 (가용성은 낮아지지만 데이터 일관성 유지)
