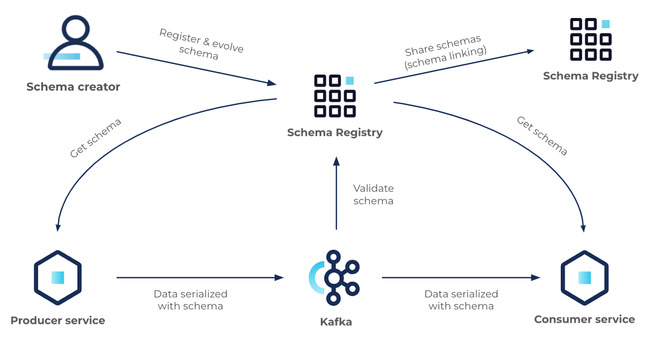
Kafka 기반 데이터 파이프라인에서 메시지 구조를 일관되게 유지하고, 스키마 변경 시 충돌 없이 안정적으로 데이터를 처리하기 위해서는 스키마 관리 시스템이 필수적이다. Schema Registry는 이러한 스키마 정의와 버전 관리를 중앙에서 수행하는 핵심 컴포넌트다.
이 글에서는 Schema Registry의 구조, Avro 포맷의 특징, 스키마 등록 방식, REST API, 호환성 정책까지 전반적으로 설명한다.
Schema Registry
Schema Registry는 Kafka 메시지에서 사용되는 스키마를 중앙 저장소에 보관하고, 스키마 변경 시 호환성을 검사하여 시스템 간 데이터 불일치를 방지한다.
주요 목적
- 메시지 포맷의 구조적 일관성 유지
- 스키마 변경(진화)에 대한 호환성 검증
- 스키마 버전 관리
- Kafka Producer/Consumer가 동일 스키마 정의를 참조하도록 보장
Schema Registry는 데이터 저장을 위해 내부적으로 _schemas라는 Kafka 토픽을 사용하며, REST API 기반으로 스키마를 제공/검증한다.
Avro
Avro는 Kafka Connect에서 가장 널리 사용되는 스키마 기반 직렬화 포맷이다. 바이너리 형태로 구성되어 크기가 작고, 스키마에 기반해 정확한 타입 정보를 갖는다.
특징
- 매우 compact한 바이너리 포맷
- 스키마 기반(type-safe) 구조
- Schema Registry와 결합해 완전한 스키마 진화(Evolution) 가능
- 다양한 언어(Java, Python 등) 간 구조 공유
- 빠른 직렬화/역직렬화 속도
장점
- 데이터 크기가 작아 전송·저장 효율이 좋음
- 타입 구조가 명확하여 Sink(예: JDBC)에서 정확한 컬럼 매핑 가능
- 스키마를 통해 데이터 의미가 명확해짐
- 스키마 호환성 정책을 통해 무중단 진화 가능
- JSON보다 안정적이고 parsing 속도 빠름
Avro vs JSON
| 항목 | JSON | Avro |
|---|---|---|
| 데이터 크기 | 큼 (텍스트 기반) | 작음 (바이너리) |
| 타입 정의 | 없음 | 명확한 타입 정의 |
| 스키마 관리 | 없음 | Schema Registry에서 버전/호환성 관리 |
| 스키마 진화 | 불가능 | 호환성 정책으로 진화 가능 |
| 파싱 비용 | 높음 | 낮음 |
Schema Registry Config
Kafka Connect에서 Avro를 사용하려면 Producer/Consumer 또는 Connector가 Schema Registry를 직접 참조하도록 설정해야 한다.
{
"key.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://localhost:8081",
"value.converter.schema.registry.url":"http://localhost:8081",
}설명
AvroConverter: Avro 포맷으로 serialize/deserializeschema.registry.url: Schema Registry 주소schemas.enable: 메시지에 스키마 포함 여부 (Sink Connector 타입 매핑 시 필수)
Sink, Source Connector 모두 동일한 방식으로 Schema Registry를 사용한다.
Schema Registry 등록 주요 정보
Schema Registry는 스키마를 다음 세 가지 핵심 구성요소로 관리한다.
subjects
스키마가 저장되는 논리적 단위
- Kafka 토픽마다 Key/Value 스키마가 분리됨
<topic-name>-key <topic-name>-value - 호환성 검사(compatibility)는 subject 단위로 수행
- 스키마 version은 subject마다 별도로 증가
- 스키마가 진화할 때 동일 subject 내에서 새로운 schema id와 version 생성
schemas
실제 스키마의 원문
- Avro/JSON Schema/Protobuf 데이터 구조 정의
- 필드, 타입, default 값, logical type 등 포함
- Registry는 스키마마다 고유한
schema id부여
config
전역 또는 subject별 호환성 설정
- global 설정
- subject 설정 (global을 override)
- 스키마 등록 시 기존 스키마와 호환성 검사
Schema
Schema Registry는 스키마 변경 시 기존/신규 Producer·Consumer가 문제 없이 데이터를 처리할 수 있는지 검증한다.
Kafka에서 스키마 진화가 가능하려면 읽기 스키마(read schema) 와 쓰기 스키마(write schema) 개념을 이해해야 한다.
쓰기 스키마 (Writer Schema)
- Producer가 실제로 메시지를 기록할 때 사용한 스키마
- 각 메시지는 스키마 ID를 포함하고 전송됨
읽기 스키마 (Reader Schema)
- Consumer가 메시지를 읽을 때 사용하려는 스키마
- Reader Schema는 필요에 따라 Writer Schema와 비교하여 변환될 수 있음
Schema Registry는 Writer Schema("메시지에 저장된 스키마") 와
Reader Schema("Consumer가 사용하려는 스키마") 를 비교해 호환성을 결정한다.
호환성
BACKWARD
새로운 스키마로 생산된 메시지를 기존 Consumer가 읽을 수 있어야 함
(과거 Reader, 현재 Writer 비교)
예:
기존 필드를 삭제하면 불가능
새 필드를 추가하되 default가 있으면 가능
FORWARD
기존 메시지를 새로운 Consumer가 읽을 수 있어야 함
(현재 Reader, 과거 Writer 비교)
예:
필드 삭제는 가능
새 필드 추가는 Reader가 모르면 무시 가능
FULL
Backward + Forward 모두 만족해야 함
가장 엄격한 정책
NONE
모든 변경 허용
호환성 체크 없음
subject와 호환성의 관계
- 호환성은 subject 단위로 적용됨
topic-valuesubject는 데이터 스키마에 대해 호환성 검사topic-keysubject는 PK 스키마에 대한 검사- 스키마 version은 subject별로 독립적으로 증가
- 스키마 등록 시 현재 subject의 호환성 규칙을 기반으로 기존 version과 비교
