JOIN에 사용되는 Nested Loop Join보다 빠른 Hash Join
MySQL 8.0.18버전 부터 추가된 기능이며 PostgreSQL, Oracle.. 많은 RDBMS에서는 이전부터 이미 지원하는 기능입니다.
☠️ 하지만 진짜 Hash join이 NLJ보다 무조건 빠르지는 않다.
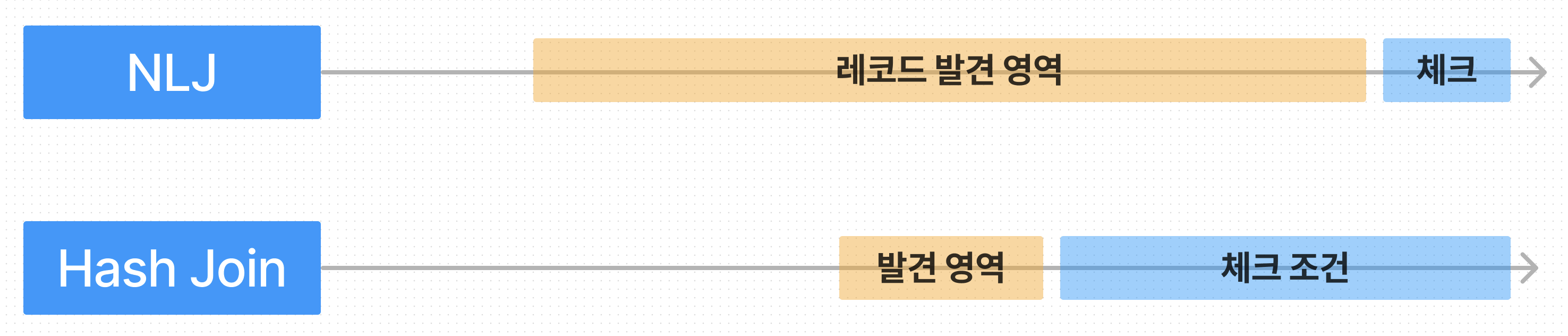
예상대로 NLJ이 hash join보다 필요한 모든 레코드를 늦게 발견합니다.
실질적인 필요 레코드의 탐색이 쿼리의 끝은 아님. 탐색 범위를 줄일 수 없는 체크조건이 포함될 수도 있습니다.
중요한 것은 마지막 레코드 발견 영역은 Hash Join이 앞에 있으나
첫 레코드 발견 영역은 NLJ가 앞에 있습니다.
Hash Join : Best Througput 전략에 적합
Nested Loop Join : Best Response-time 전략에 적합
- MYSQL은 범용 RDBMS (온라인 트랜잭션 처리를 위한 DB서버를 지칭)
- 대용량 데이터 분석을 위해 MySQL 서버는 사용 X
-> MySQL 서버는 주로 조인 조건의 컬럼이 인덱스가 없거나 조인 대상 테이블중 일부의 레코드 건수가 매우 적은 경우 등에 대해서만 Hash Join 알고리즘을 사용
-> Hash Join은 Nested Loop Join이 사용되기에 적합하지 않은 경우를 위한 차선책
- IGNORE INDEX로 Index를 사용할 수 없게 유도
- Extra 컬럼에 "hash join"이 노출
SELECT *
FROM employees e IGNORE INDEX(PRIMARY, ix_hiredate)
INNER JOIN dept_emp de IGNORE INDEX(ix_empno_fromdate, ix_fromdate)
ON de.emp_no=e.emp_no AND de.from_date=e.hire_date;일반적으로 hash join은 Build-phase, Probe-phase 단계로 처리됩니다.
Build-phase : 조인 대상 테이블 중에서 레코드 건수가 적어 해시 테이블로 만들기에 용이한 테이블을 골라서 메모리에 해시 테이블을 생성
Probe-phase : 나머지 테이블의 레코드를 읽어서 해시 테이블의 일치 레코드를 찾는 과정
EXPLAIN FORMAT=TREE를 통해 build, probe table을 확인할 수 있습니다.
해시 조인과정(메모리에서 모두 처리 가능한 경우)

해시 조인과정(메모리에서 모두 처리가 불가능)
Hash table을 메모리에 저장할 때 Join Buffer를 사용합니다.
이러한 경우 build, probe table을 적당한 크기의 청크로 분리한 다음
해시조인을 처리
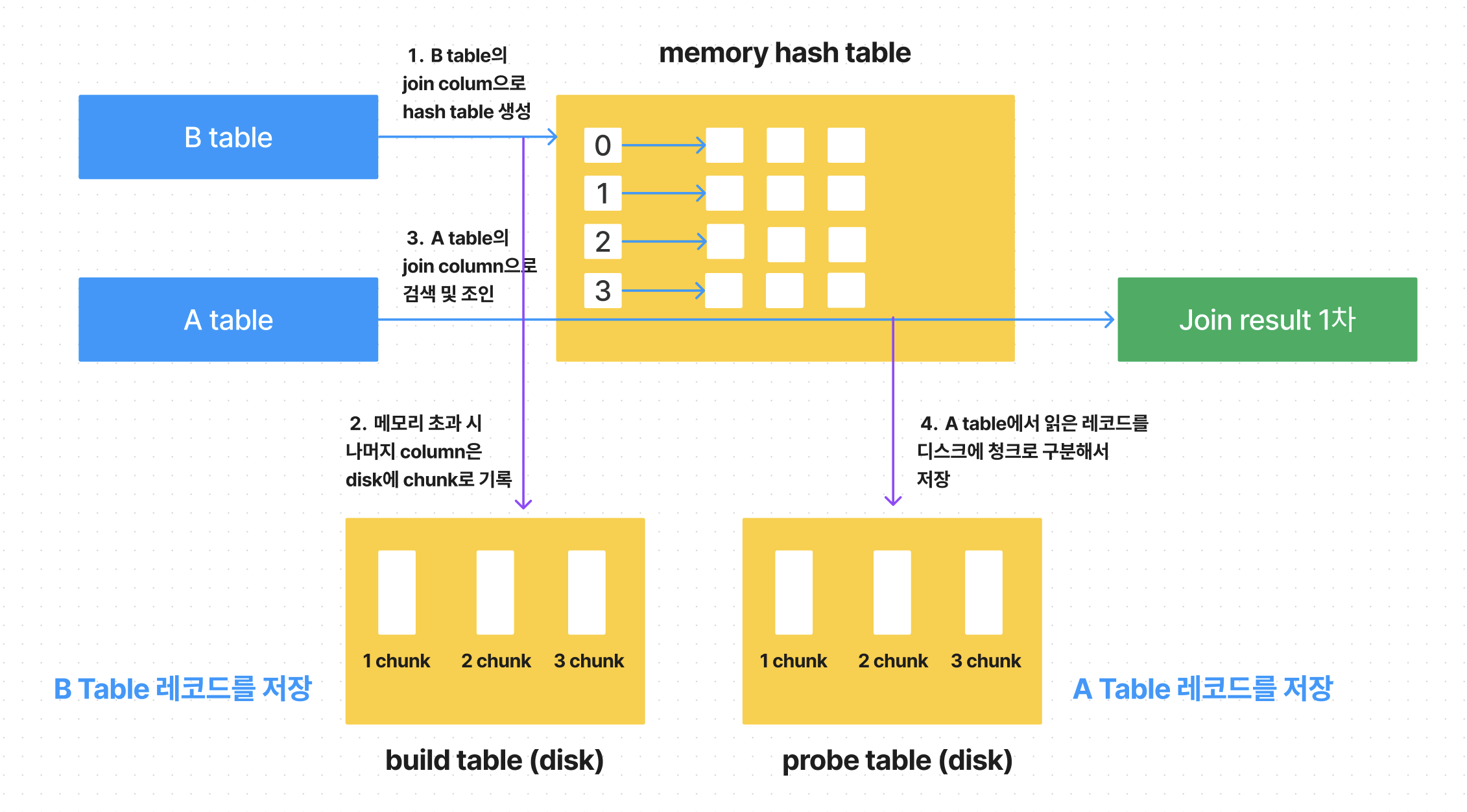
Join result와 probe table의 chunk가 함께 생성
Disk의 build chunk를 hash table에 올리고
probe table의 chunck를 읽어 다시 조인후 결과 생성
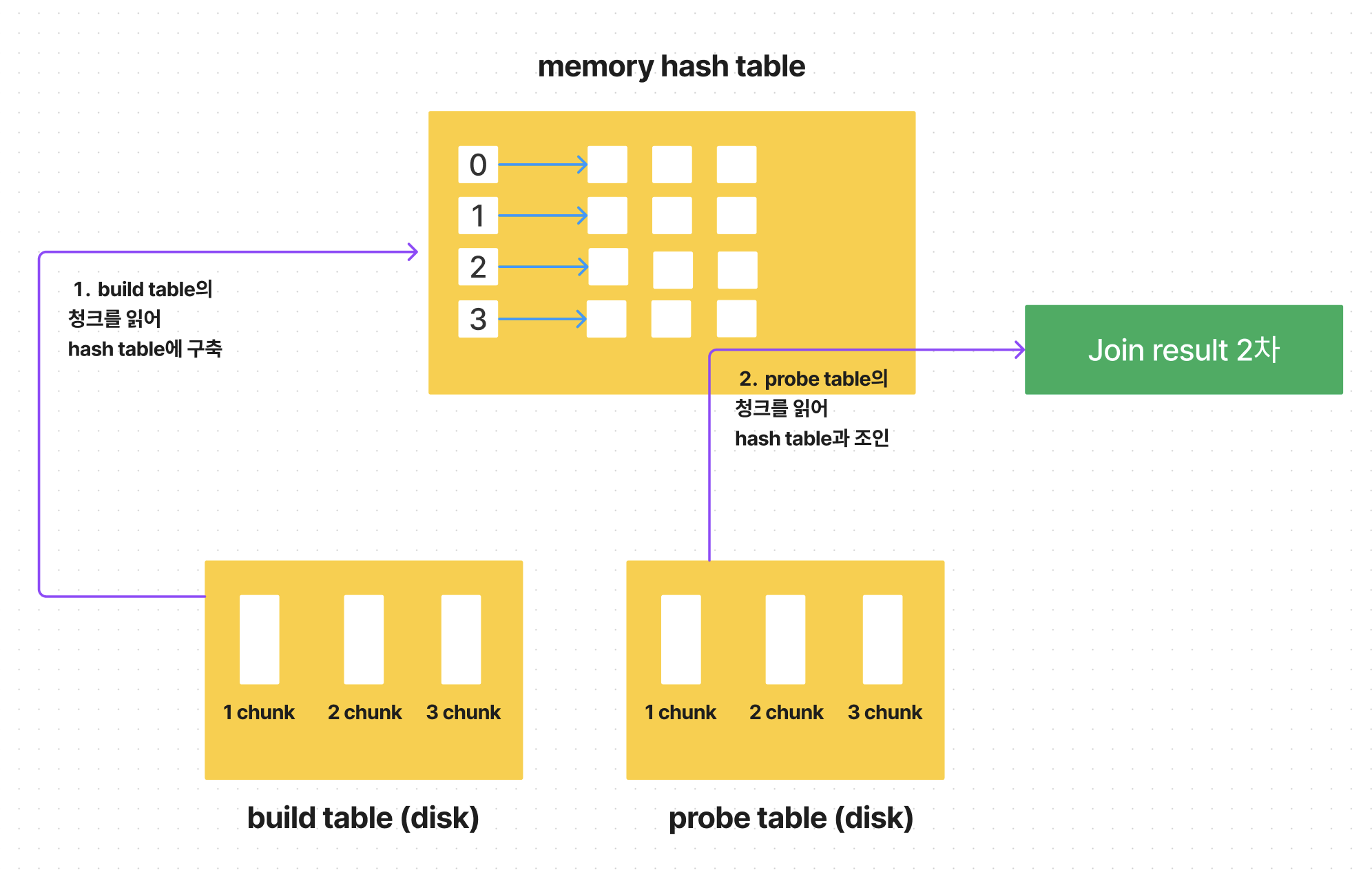
이렇게 디스크에 저장된 청크 개수만큼 반복 처리하여 조인 결과를 완성시킵니다.
