Multi Range Read, Batched Key Access
💬 구글, 유튜브 검색 결과 거의 없음
- nested Loop Join의 단점을 개선하기 위해 도입
Nested Loop Join
N개의 집합을 N개의 중첩된 반복을 통해 사용해 조인하는 알고리즘, 대량의 테이블을 조인하는데 효율이 좋지않음, OLTP성 쿼리에 적합
- 줄여서 NR JOIN이라고도 불림
- 조인해야 할 데이터가 적은 경우 유용한 방식
- 드라이빙 테이블에서 조건에 만족하는 데이터를 선택한 후, 이 값을 대상 테이블에 반복적으로 검색하면서 결과를 만들어내는 방식
- 랜덤 액세스를 기반으로 하기 때문에 탐색 횟수만큼 랜덤I/O 발생
- 시간 복잡도 O(n * m)
- 드라이빙 테이블 숫자가 적어야 유리하다.
MySQL 8.0 nested-loop join docs
https://dev.mysql.com/doc/refman/8.0/en/nested-loop-joins.html
Block Nested Loop
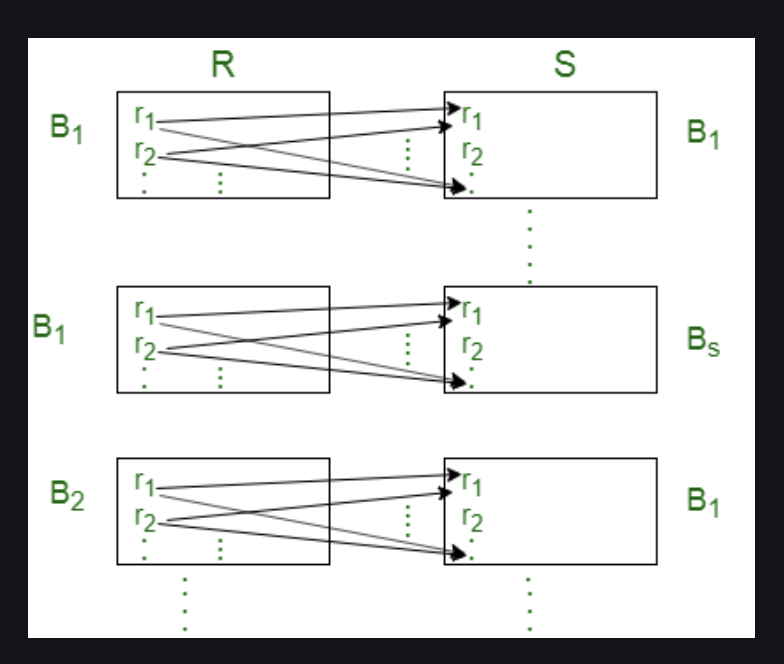
Buffer를 사용하여 Join하는 방식
MySQL 서버에서 사용되는 대부분의 조인은 NL Join이나 조인의 연결 조건이 되는 컬럼에 모두 인덱스가 존재하면 Block Nested Loop사용
하지만 Sort Join이나 Hash Join에 비해 퍼포먼스가 안나옵니다.
(MySQL8 이전에 PostgreSQL, Oracle에서는 이미 Sort, Hash Join을 제공)
MySQL 8.0.20부터 Block Nested Loop Join말고 Hash Join 알고리즘이 사용
NL Join과 BNL Join의 차이 2가지
- 조인 버퍼의 사용 여부
- 조인에서 드라이빙 테이블, 드리븐 테이블이 어떤 순서로 조인이 되는가
Index Condition Pushdown ⭐️
선행 개념
MySQL은 서버 엔진과 스토리지 엔진이 분리된 구조로 되어 있다.
MySQL 서버 엔진은 쿼리 파싱과 실행 계획 생성 및 수행을 담당하고, 각 스토리지 엔진이 데이터와 인덱스 및 물리적인 I/O 작업을 관리한다.
ALTER TABLE employees ADD INDEX ix_lastname_firstname(last_name, first_name);
SELECT * FROM employees WHERE last_name = 'Acton' AND first_name LIKE '%sal%';
MySQL 5.6 전에는 MySQL 엔진이 인덱스 사용이 가능한 조건의 레코드(last_name=Acton)를 스토리지 엔진에게 넘겨 첫 번째 조건만 충족하는 레코드를 들고옵니다.
MySQL 5.6 부터는 스토리지 엔진에게 조건에 포함된 모든 컬럼을 스토리지 엔진에 밀어버립니다.
last_name + first_name의 조건에 충족하는 레코드를 한번에 MySQL Engine에 전달합니다.
이런 기능이 사용되면 Extra에 Using index condition이 출력됩니다.
쿼리의 성능이 몇 배 ~ 몇십 배 향상되는 중요한 기능
ICP 관련 포스팅
https://jojoldu.tistory.com/474
Use Index Extensions
세컨더리 인덱스에 자동으로 추가된 프라이머리 키
세컨더리 인덱스를 사용하여 레코드를 찾을 때 세컨더리 인덱스에 포함된 클러스터 인덱스의 PK를 찾아갑니다.
그렇다면 idx_time(time) 인덱스는 (time, pk)으로 세컨더리 인덱스가 생성됩니다.
이렇게 pk까지 인덱싱의 용도로 사용하는 것을 Use Index Extensions라고 합니다.

MySQL Use Index Extensions Docs
https://dev.mysql.com/doc/refman/8.0/en/index-extensions.html
Index Merge
각각 조건이 서로 다른 인덱스를 사용하여 실행 계획을 선택
- 보편적으로 옵티마이저는 테이블별로 하나의 인덱스만 사용하도록 계획을 수립
- 여러 개의 조건이 있다면 1개만 인덱스를 사용해 작업의 범위를 줄이고 나머지는 체크 조건을 사용하는 것이 일반적
intersection, sort union, union 3가지 방식을 통해 병합을 할 수 있습니다.
intersection(교집합, AND 연산)
각 인덱스를 검색해 두 결과의 교집합만 찾아서 반환하는 것
.. COUNT(*) .. WHERE first_name='Georgi' AND emp_no BETWEEN 10000 AND 20000
1번 Index - first_name='Georgi'를 부합하는 값이 100개
2번 Index - emp_no BETWEEN 10000 AND 20000를 부합하는 값이 10000개
2개의 조건에 부합하는 값이 10개라면
1번 Index만 사용하면 90개를 버리고 2번 Index만 사용하면 9990개를 버리는 것 입니다.
이러한 경우 옵티마이저는 index merge intersection를 사용합니다.
index merge union(합집합, OR 연산)
WHERE절에 사용된 2개 이상의 조건이 각각의 인덱스를 사용해 OR 연산으로 연결된 경우 사용되는 최적화
.. SELECT * .. WHERE first_name = 'Matt' OR hire_date = '1987-03-31'
first_name = 'Matt'의 결과와 hire_date = '1987-03-31'의 결과를 Primary Key를 기준으로 중복을 제거, 나열합니다. (별도로 정렬을 수행하지 않음, heap을 사용한 우선순위 큐)
Tip
And 연산은 1개라도 인덱스를 사용할 수 있으면 인덱스 레인지 스캔이 수행합니다. 하지만 OR 연산에서는 둘 중 하나라도 인덱스를 사용하지 못하면 풀 테이블 스캔으로밖에 처리를 하지 못함
index merge sort union
???
semi join
MySQL 8.0부터 도입된 세미 조인 쿼리 성능 개선을 위한 최전화 전략
- Table Pull-out 1️⃣
- Duplicate Weed-out
- First Match
- Loose Scan
- Meterialization
MySQL 5.7 이전에서는 특히 세미 조인 형식의 쿼리를 사용하지 말자
다른 RDBMS에서는 서브 쿼리가 먼저 실행되고 그다음 아우터 테이블의 쿼리가 실행되지만 MySQL 서버는 아우터 테이블을 풀스캔 하면서 한 건 한 건 서브 쿼리의 조건에 일치하는지 비교
Table Pull-out
요약 : 세미 조인의 서브쿼리에 사용된 테이블을 아우터 쿼리로 끄집어낸 후에 쿼리를 조인 쿼리로 재작성하는 형태의 최적화
서브쿼리를 작성해도 실행 계획에 같은 id를 가지면 조인으로 처리됐음을 의미
사용 조건
- 서브 쿼리 부분이 UNIQUE 인덱스나 프라이머리 키 룩업으로 결과가 1건인 경우
- MySQL에서는 가능하다면 Table pullout을 최대한 적용
- 서브쿼리 테이블을 아우터 쿼리로 가져와 조인으로 풀어쓰는데, 서브쿼리의 모든 테이블이 아우터 쿼리로 끄집어 낼 수 있다면 서브쿼리 자체가 사라짐
- 조건을 만족한다면 이제부터 서브쿼리를 조인으로 풀어서 사용할 필요가 없음.
First Match
요약 : IN 형태의 세미 조인을 EXISTS 형태로 튜닝한 것과 비슷한 방법
First Match최적화가 사용되면 Extra에 FirstMatch(e)라고 출력됩니다.
서브 쿼리와 메인 쿼리가 동일한 id로 출력됩니다.(아마도)
FirstMatch 이름처럼 한 건만 찾게 되면 Exists처럼 검색을 종료합니다.
- MySQL 5.5에서 수행했던 최적화 방법인
IN-TO-EXISTS와 비슷한 처리 로직을 수행 - First Match는 원래 쿼리에 없던 동등 조건을 옵티마이저가 자동으로 추가, 더 많은 조건이 주어지므로 더 나은 계획을 수립할 수 있음
- 5.5의
IN-TO-EXISTS는 아무런 조건 없이 변환 가능한 경우에는 무조건 수행을 했으나 FirstMatch는 일부 테이블에 대해서만 수행에 대한 취사선택이 가능한 것이 장점
특정 형태의 서브쿼리에서 자주 사용되는 최적화입니다.
First Match의 제한 사항과 특성
- 하나의 레코드만 검색되면 검색을 멈추는 Short-cut path이기 때문에 그 서브쿼리가 참조하는 모든 아우터 테이블이 먼저 조회된 이후 실행
- 상관 서브쿼리(Correleted subquery)에서도 사용될 수 있음
- GROUP BY나 집합 함수가 사용된 서브쿼리의 최적화에는 사용될 수 없음
Loose Scan
요약 : GROUP BY의 Loose Scan과 비슷한 방법을 사용
Meterialization
요약 : 세미 조인에 사용된 서브쿼리를 통째로 구체화해서 쿼리를 최적화(임시 테이블)
Duplicated Weed-out
요약 : 세미 조인 서브쿼리를 일반적인 INNER JOIN 쿼리로 바꿔서 실행하고 마지막에 중복된 레코드를 제거
Use invisible indexes ⭐️
MySQL 8.0부터는 인덱스의 가용 상태를 제어할 수 있음
ALTER TABLE ... ALTER INDEX [ VISIBLE | INVISIBLE ]
옵티마이저가 ix_hiredate index를 사용하지 못함
ALTER TABLE employees ALTER INDEX ix_hiredate INVISIBLE;
원상 복귀
ALTER TABLE employees ALTER INDEX ix_hiredate VISIBLE;
