Domain shift

딥러닝 모델은 훈련데이터와 테스트 데이터 간의 분포가 같은 상황을 가정한 상황에서 높은 성능을 보인다.
하지만 훈련데이터와 테스트 데이터 간의 분포가 같지 않은 domain shift 상황일 경우 모델 성능이 크게 저하가 된다.
- Feature shift : 상황이 바뀌는 경우
- Label shift : class 간 분포가 바뀌는 경우
문제 해결하기 위한 방법론
-
Domain Adaptation : source 데이터와 target 데이터를 일부를 사용하여 분포를 맞추는 방법
-
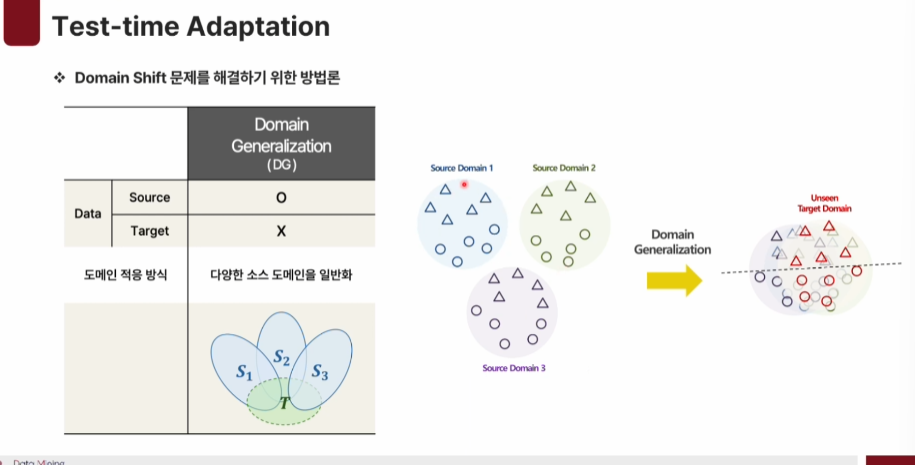
Domain Generalization : 다양한 source domain으로부터 일반화를 시켜 unseen domain에서도 일반화 된 결정경계를 형성할 수 있게한다.

하지만 실제환경에서는 보안문제로 source data에 접근이 불가능해 직접적인 Adaptation이 어렵다.
따라서 Test-Time Adaptation은 테스트 시점에서 Source data 없이, 사전 학습된 모델을 test data에 맞게 조정하여 예측을 잘 할 수 있도록 하는 것이다.

TTA(Test-Time Adaptation)은 타겟 도메인 데이터의 수집/활용 방식에 따라 3가지로 나뉜다.
- Test-time Domain Adaptation (TTDA)
: 모든 배치를 활용하여 adaptation 후 예측 (오프라인 환경에 적합) - Test-time Batch Adaptation (TTBA)
: 각 미니 배치 단위로 adaptation 후 예측 - Online Test-time Adaptation (OTTA)
: 실시간으로 수집되는 데이터에 순자적으로 adaptation 후 예측 (실시간 환경에 적합)
Test-time Domain Adaptation (TTDA)
한번에 많은 target data가 준비되어야 하고 많은 연산을 하기에 실시간 환경에는 적합하지 않다.
Test-time Batch Adaptation (TTBA)
앞선 상황과는 다르게 각 Batch가 들어올때마다 빠르게 adaptation을 하는 방법. 하지만 매 배Batch가 다른 Batch와는 독립적으로 수행하기에 영향을 줄 수 없다는 단점이 존재한다.
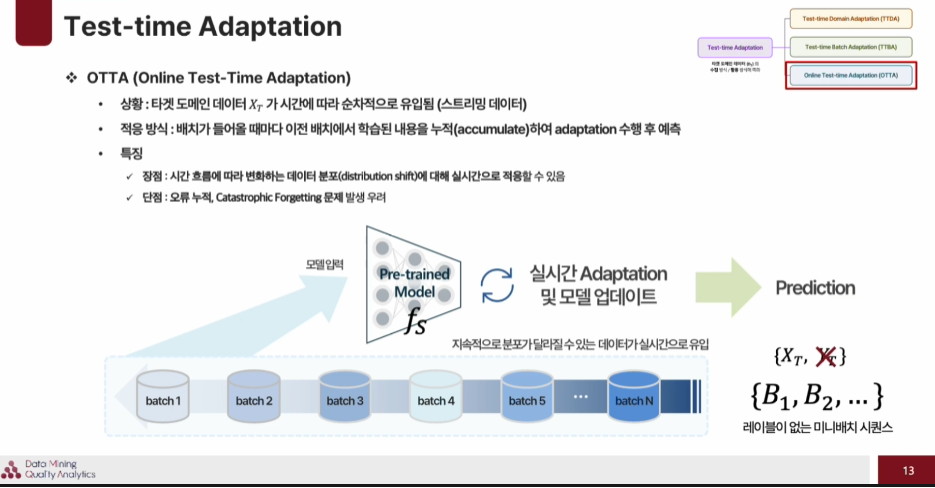
Online Test-time Adaptation (OTTA)

데이터가 들어올때마다 실시간으로 adapatation을 진행. TTBA와 다른점은 이전 배치에서 학습된 내용을 누적하여 adaptation을 수행 후 예측 한다는 것이다. 하지만 단점으로는 오류가 누적되고, 기존에 배웠던 중요한 내용이 사라지는 Catastrophic Forgetting 문제가 발생할 수 있다.
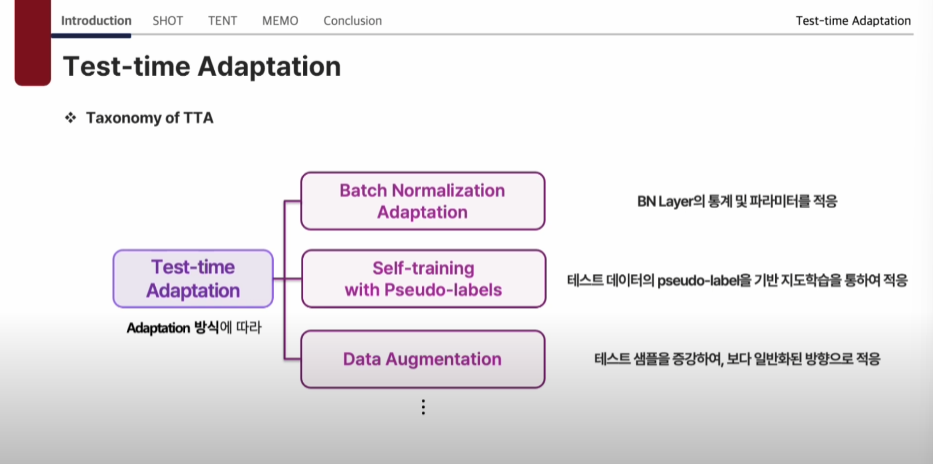
Adapatation 방식에 따라
- Batch NormaIization Adaptation
: BN Layer의 통계 및 파라미터를 적용 - Self-training with Pseudo-labels
: 테스트 데이터의 pseudo-label을 기반 지도학습을 통하여 적용 - Data Augmentation
: 테스트 샘플을 증강하여, 보다 일반화된 방향으로 적응
SHOT(Source Hypothesis Transfer)_TTDA
소스 데이터 없이, classifier는 고정한 채 사전에 수집된 타겟 데이터만으로 도메인 적응을
1) information Maximization, 2) Pseudo-Label 기반으로 Feature Extractor를 업데이트 하여 적응 수행 하는 방법이다.
SHOT의 적응단계
1) SHOT은 먼저 Classifier는 고정한 채로 Feature Extractor만 target데이터로 Information Maximization loss를 최소화 하는 방향을 업데이트를 해준다. -> 모델에 target data가 어느정도 맞춰지는 기능을 한다.
2) Proto type 기반으로 pseudo-label을 생성을 하고 이걸 기반으로 지도학습을 한번 더 진행한다. 이때 loss 는 IM loss 와 pseudo-label을 cross-entropy 방식으로 loss를 최소화 하는 방향으로 진행된다.
이때 Classifier는 고정하고 Feature extractor만을 업데이트 하는 이유는 Feature extractor가 decision boundary에 맞게 나오도록 업데이트 하는 것이다.
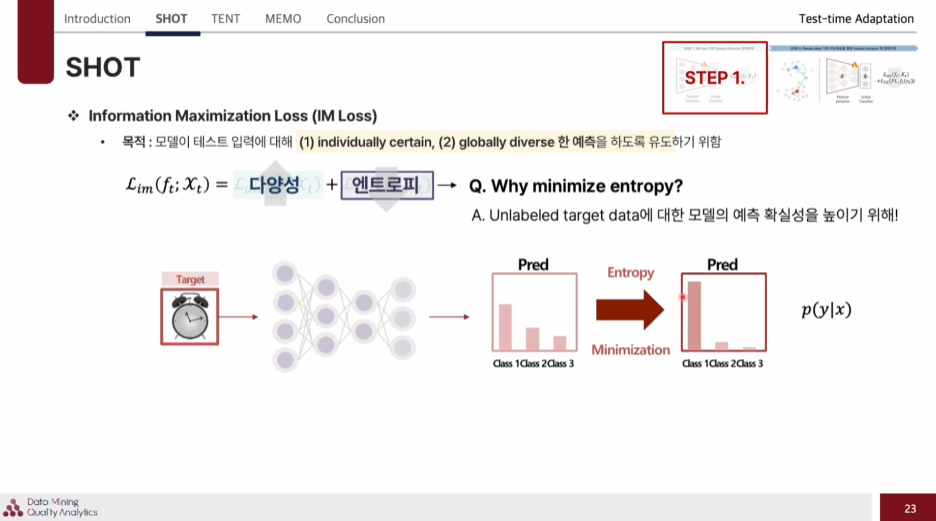
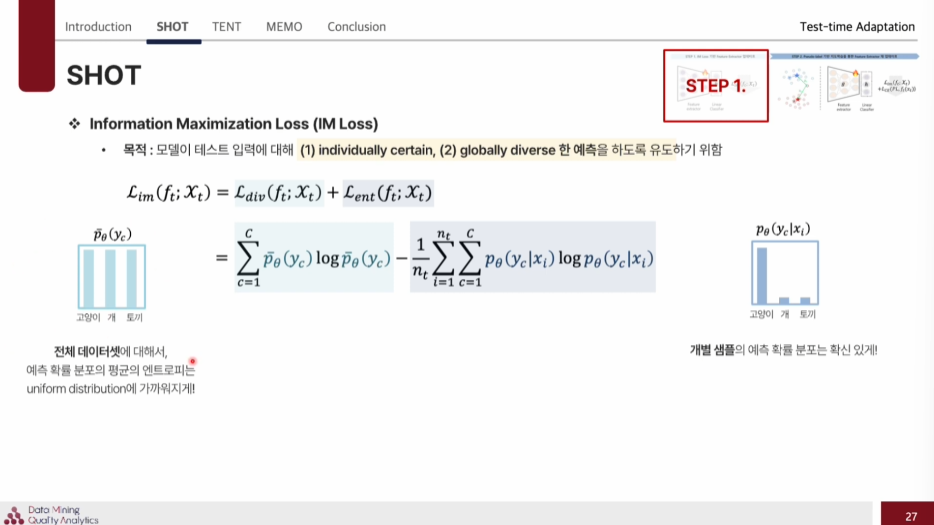
IM loss는

individually certain, globally diverse 한 예측을 하도록 유도하기 위함이다.
-
Entropy
예측이 편중되지 않고 다양성 높여주고
엔트로피 각 샘플의 예측 분포를 더 확신있게 만들도록 유도.
target 데이터는 라벨 정보가 없기에 이것을 엔트로피를 낮추는 방법으로 학습하여 모델의 예측 확실성을 높인다.
하지만 label이 없는 상황에서 엔트로피를 낮추기 위해서 한쪽으로만 예측을 할 수 있기에 항상 좋은 것만은 아니다.
-> 따라서 다양한 class를 보장하는 Loss term이 필요하다. -
Diverse
: 전체 데이터셋에 대해서, 예측 확률 분포의 평균의 엔트로피는 uniform distribution에 가까워지게 해서 특정 class에 쏠리는 것을 막아주는 역할을 한다.
ex)

Pseudo label기반
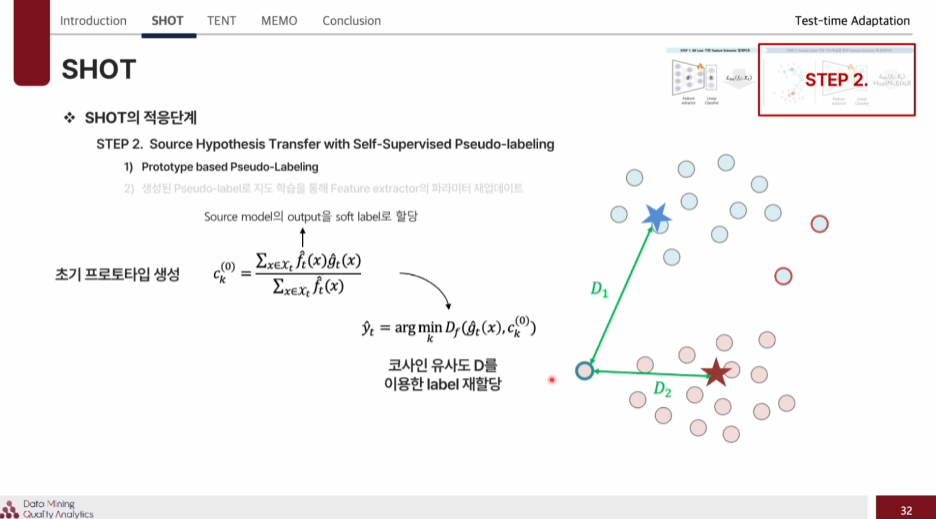
먼저 각 다른 샘플에 대해서 초기 프로토타입을 생성을 하고 코사인 유사도를 기반으로 label을 재할당 한다. 이 과정을 계속 진행하며 프로토타입을 개선해 나간다.
이렇게 pseudo label을 기반으로 feature extractor를 재 업데이트를 해주는 것이다.
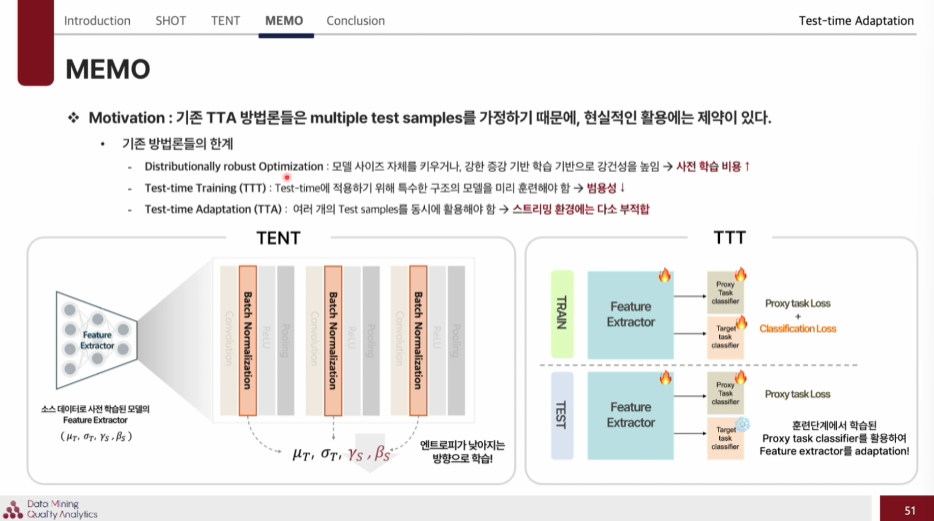
TENT(Test Entropy Minimization)_TTBA
: 테스트 시점에서 입력된 배치 데이터만을 활용하여, 모델이 예측한 확률분포의 엔트로피를 최소화하는 방향으로 BN Layer의 scale, shift 값만을 업데이트 하는 방식이다.
?그러면 SHOT(Source Hypothesis Transfer)_TTDA에서는 엔트로피를 낮추면서 diverse를 다양하기 위한 loss가 따로 있엇는데 TENT에서는 지금 diverse loss가 빠져있는데, 이걸 Batch에서 충분히 다양성을 보장하기 때문에 이렇게 뺀 것인지, 아니면 TENT에 diverse loss를 추가한것이 SHOT으로 생각하면 되는건지 궁금
전체클래스에 대해서 확신있는 예측을 해주기 위해 엔트로피를 낮추는 방식으로 학습을 진행한다.
이때 단일 샘플에 대해서만 엔트로피를 최소화하게 되면, 확실하지 않은 상황에서도 확률을 하나의 클래스에 몰아주는 현상이 발생한다. 그렇기 때문에 배치 단위로 최적화하여, 여러 샘플을 동시에 보고 파라미터를 업데이트 해준다.
(SHOT은 Feature Extractor의 전체 파라미터를 업데이트 하는 방식이면, TENT는 BL layer의 일부 파라미터만 업데이트 하는 방식이라 조금 더 경량화 한 방식이다.)
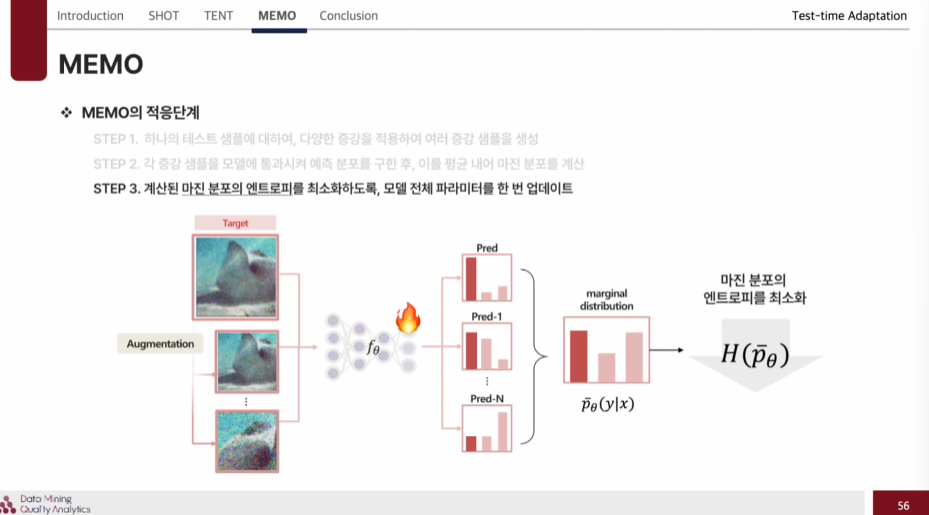
MEMO(Marginal Entropy minimization with one test point )_TTBA
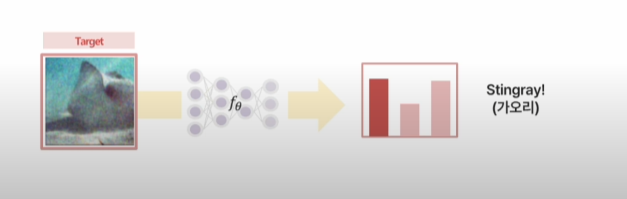
: 하나의 테스트 샘플만으로 모델에 적응 가능한 방법론으로, 단일 테스트 샘플을 다양한 방식으로 증강한 결과에 대하여, marginal entropy 를 최소화하는 방향으로 모델 전체 파라미터를 업데이트하여 적응을 수행한 방식이다.
Motivation
기존 TTA 방법론들은 multiple test samples을 가정하는데, 현실세계에서는 이렇게 batch단위까지 데이터가 모이는 것을 기다리기 힘들다.
따라서 실시간 환경에서는 부적합하다.
-> 이러한 환경을 극복하기 위해 하나의 sample만으로 어떤 사전학습 모델인지 상관없이 적용 가능한 plug and play 방식을 적용 가능한 범용적인 방법이다.
MEMO의 적응단계
1) 먼저 하나의 테스트 샘플에 대해 다양한 증강 방식으로 여러 증강 샘플을 생성한다.
2) 각 증강 샘플을 모델에 통과시켜 예측 분포를 구하고, 이를 평균 내어 마진 분포를 계산한다.
3) 계산된 마진 분포의 엔트로피를 최소화하도록, 모델 저체 파라미터를 한 번 업데이트 한다.
4) 업데이트된 모델로 원본 입력 샘플에 대하여 최종 예측을 수행한다.
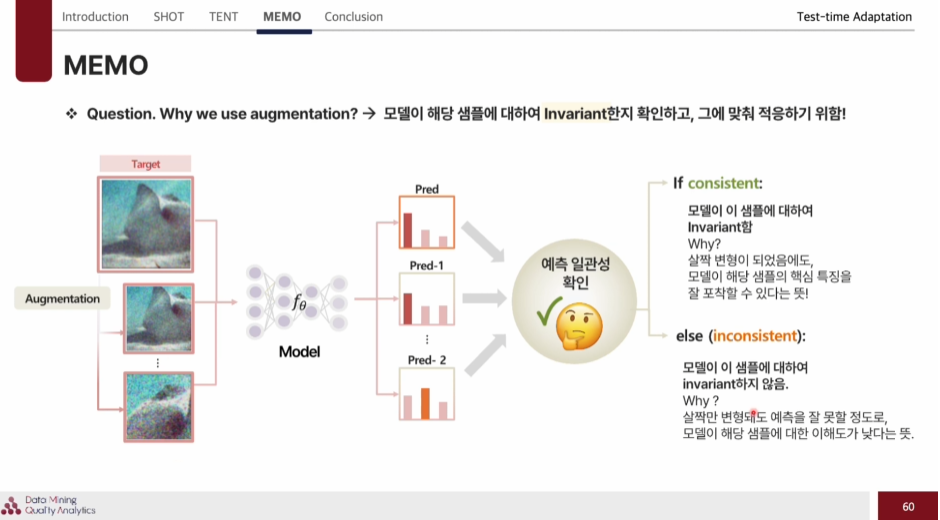
증강을 하는 이유는 : 모델이 해당 샘플에 대하여 Invariant한지 확인하고, 그에 맞춰 적응하기 위함이다.
따라서 모델이 살짝 변형된 sample에도 핵심 특징을 잘 포착한다면 consistent하게 학습되었다고 판단이 가능하다.
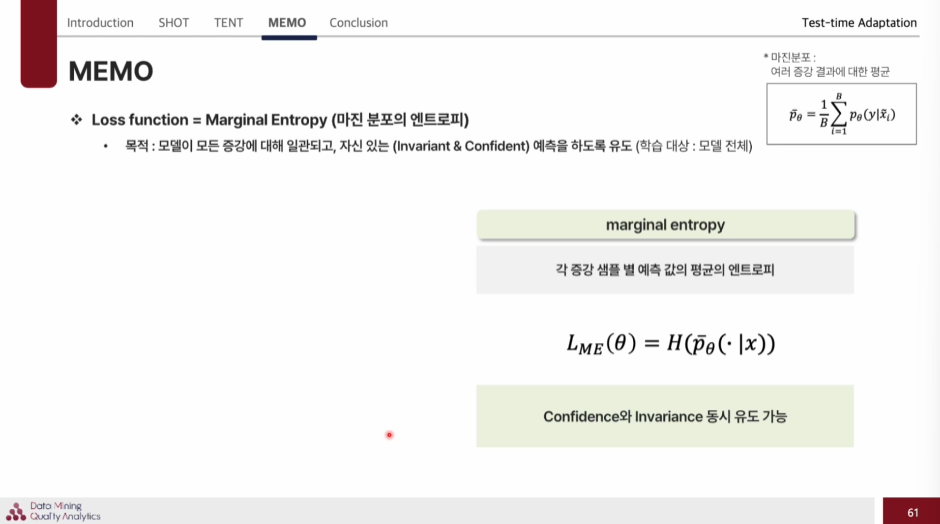
Loss function
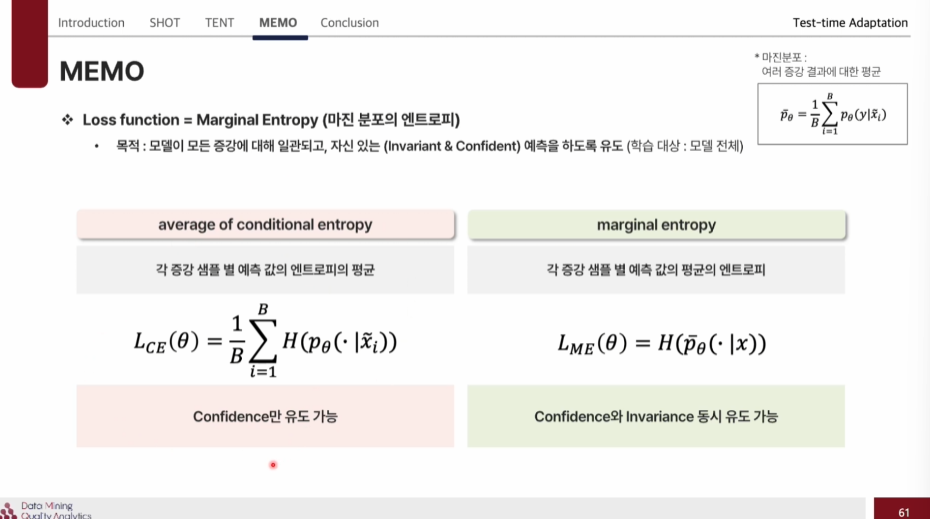
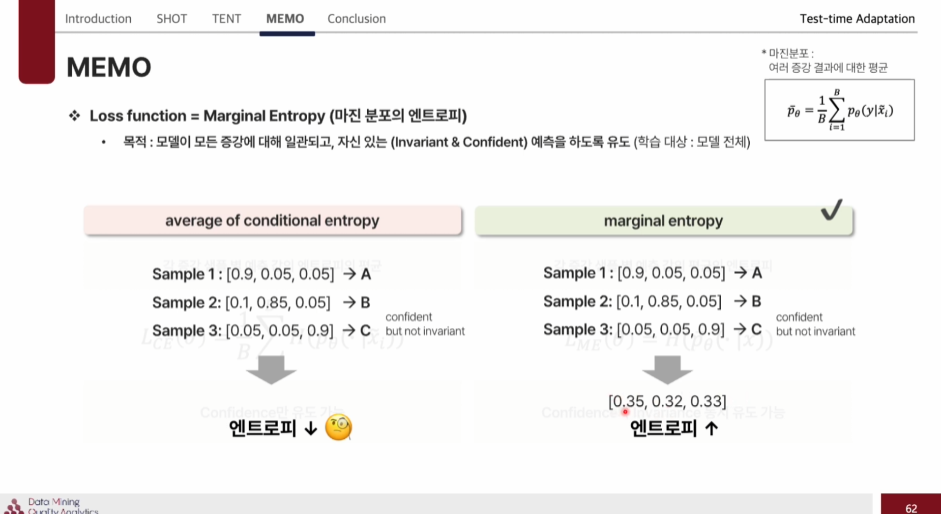
- (사용)Marginal entropy : 각 증강 샘플 별 예측 값의 평균의 엔트로피 ->Confidence 와 Invariance를 동시에 유도 가능하다.
- average of conditional entropy : 각 증강 샘플 별 예측 값의 엔트로피의 평균 -> Confidence만 유도 가능하다.
이렇게 보면 average of conditional entropy은 각 sample별로 예측을 잘하니 entropy가 낮게 나왔다고 판단하고 끝나지만, Marginal entropy은 각열마다의 평균을 또 구해서 loss를 적용해 이것의 엔트로피를 낮춰 Confidence 와 Invariance를 둘 다 가능하게 된다.
?MEMO에서 marginal entropy에서 confidence는 이해가는데 Invariance 부분에서 각 열마다의 엔트로피를 계산해서 높다?
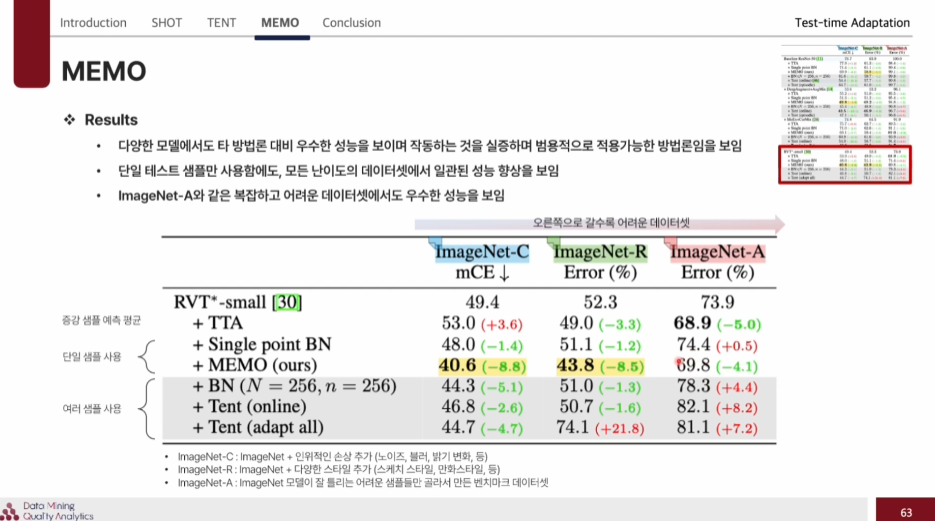
이렇게 예측이 비교적 쉬운, Domain shift의 원인이 명확한 C,R 데이터셋에서는 Batch단위로 적응을 하는 방식이 좋은 성능을 내지만, Domain shift의 원인이 불명확하고, 예측이 어려운 A데이터셋에서는 오히려 Batch단위로 적응한 방식이 에러가 누적되어 성능이 더 나빠질 수도 있다. 하지만 MEMO는 단일 샘플을 기반으로 하기에 이러한 경우에도 성능을 낼 수 있다.
