히스토그램
- 데이터의 분포를 시각적으로 표현하는 도구
- 데이터를 여러 구간(또는 "빈(bin)")으로 나누어 각 구간에 속하는 데이터의 빈도(횟수)를 막대 그래프로 나타낸 것
- 이를 통해 데이터가 어떻게 분포되어 있는지, 특정 구간에 데이터가 몰려 있는지, 분포의 형태(예: 좌우 대칭, 왜도, 첨도 등)를 한눈에 파악할 수 있습니다.
1️⃣ 모집단
- 분석하고자 하는 전체 데이터 집합
- EX. 모든 입찰 참여 기업의 예비가격
- 시뮬레이션에서 생성된 모든 예비 가격 후보 or 결과가 모집단임
- 표본과의 차이 : 모집단 전체를 조사하기 어려울 때, 일부 표본을 뽑아 분석하고 이를 모집단 전체로 일반화
2️⃣ 정규분포(Normal Distribution)
-
평균을 중심으로 좌우 대칭인 종 모양의 분포
-
데에터가 평균 주변에 집중
-
평균에서 멀어질수록 빈도가 급격히 줄어듦
-
히스토그램과의 관계 : 데이터가 정규분포를 따르면, 히스토그램은 중앙이 가장 높고, 양쪽으로 대칭인 모양을 나타냄
3️⃣ 빈도 (Frequency)
- 특정 구간(bin)에 속하는 데이터의 개수
- 히스토그램에서 y축의 막대 높이는 해당 구간에 들어가는 데이터 포인트의 개수를 표시
4️⃣ 구간 (Bin)
- 데이터의 전체 범위를 일정한 크기의 여러 부분으로 나눈것
히스토그램의 x축
bin width: 각 구간의 폭- 너무 좁으면 세부 노이즈가 많아짐
- 너무 넓으면 데이터의 세밀한 분포가 보이지 x
5️⃣ 범위(range)
- bin들이 모여 형성하는 전체 x축의 범위
- ex) 현재 히스토그램에서 x축이 0.97 ~ 1.03 인 경우 => 범위
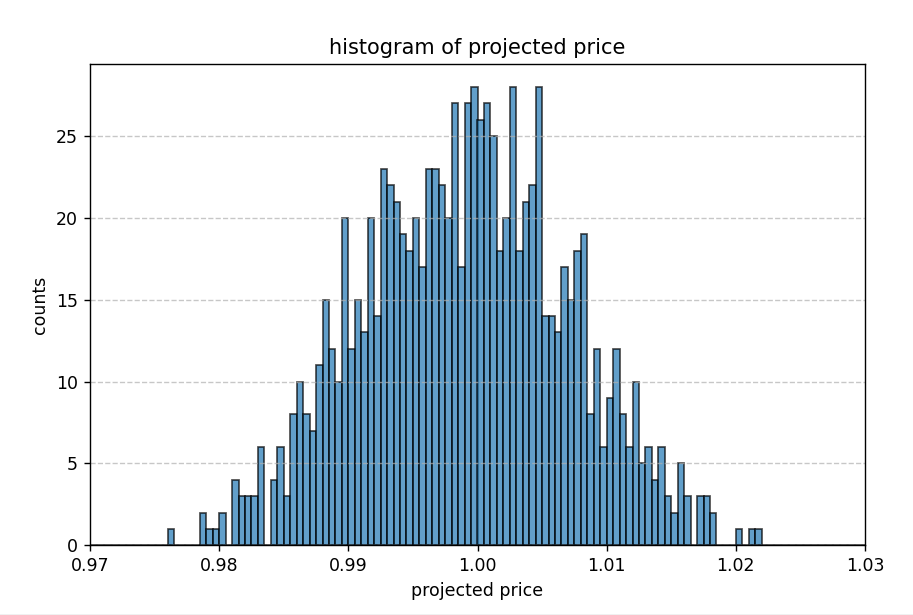
왜 히스토그램에서 범위가 0.97~1.03으로 선택되었는지?
1. 예비가격 후보 생성 과정 (projected_price.py)
예비가격 후보의 범위 정의 (type=3인 경우):
-
코드에서는 15개의 구간을 하드코딩해둠
-
첫 번째 구간은 (0.9700000000, 0.9735000000)로 정의되어 있어, 이 구간에서는 0.97 이상 0.9735 이하의 값이 무작위로 생성됩니다.
-
마지막 구간은 (1.0257142858, 1.0300000000)로 정의되어, 1.03에 가까운 값이 생성됩니다.
-
즉, 모든 구간은 0.97부터 1.03 사이를 커버합니다.
무작위 생성 및 순서 섞기:
각 구간에서 하나의 무작위 값이 생성되고, np.random.permutation(arr)를 통해 이 15개 값의 순서가 랜덤하게 섞입니다.
값들이 섞이더라도, 개별 값은 여전히 0.97에서 1.03 사이에 머무릅니다.
예정가격 산출:
플레이어들이 각자 2개의 카드를 뽑고, 모든 플레이어의 추첨 결과를 모은 후, 빈도수가 높은 4개 구간의 번호에 해당하는 후보 값들을 선택하여 그 산술평균을 계산합니다.
이 평균값도 후보 값들이 속한 0.97에서 1.03 범위 내에 있게 됩니다.
2. 히스토그램 그리기 (bid_graph.py)
히스토그램 함수의 설정:
plt.hist(data, bins=120, range=(0.97, 1.03), ...)에서 x축의 범위가 0.97부터 1.03으로 고정되어 있습니다.
이는 위의 시뮬레이션 결과(예정가격)가 항상 이 범위 내에 존재하기 때문에, 전체 데이터 분포를 제대로 시각화하기 위해 선택된 범위입니다.
왜 이 범위를 선택했는가?
코드 설계에서 예비가격 후보가 ±3% 범위(즉, 0.97 ~ 1.03) 내에서 생성되도록 하였으므로, 그 결과로 산출되는 예정가격 역시 이 범위 내에 있어야 합니다.
따라서 히스토그램의 x축을 이 범위로 지정하면, 모든 데이터가 포함되고 분포 모양을 명확하게 확인할 수 있습니다.
3. 전체 흐름 요약
데이터 생성:
15개의 구간이 0.97부터 1.03 사이로 미리 정해져 있습니다.
각 구간에서 무작위 예비가격(율)이 생성되어 후보 배열을 형성합니다.
후보들은 랜덤하게 섞이지만, 값의 범위는 여전히 0.97에서 1.03 사이입니다.
예정가격 계산:
플레이어들의 카드 추첨 결과를 바탕으로, 가장 많이 뽑힌 4개 구간의 후보값을 골라 평균을 냅니다.
최종 예정가격은 이 평균값이며, 역시 0.97에서 1.03 사이의 값을 가집니다.
히스토그램 시각화:
히스토그램 함수는 이 예정가격 데이터를 0.97부터 1.03 범위로 설정하여, 데이터의 분포와 빈도를 시각적으로 표현합니다.
즉, 시뮬레이션에서 사용된 전체 범위(0.97 ~ 1.03)가 히스토그램의 x축 범위가 됩니다.
왜 1을 넘어갈까?
1. 데이터 생성 방식
예를 들어, 평균이 1.0이고 일정한 표준편차가 있는 정규분포에서 무작위로 값을 뽑는다면, 이론적으로 1보다 큰 값도 충분히 발생할 수 있습니다.
혹은 1을 기준으로 ±x% 변동을 허용하는 알고리즘이라면, 1.02, 1.03 같은 값이 나올 수도 있습니다.
=> 현재 projected_price에서 type : ±3%, ±2% 구간으로 되어있기 때문에 범위가 1을 넘어갈 수 있음
2. 실제 데이터의 특성
“1”이 어떤 특정 기준(예: 100% 또는 목표치)일 뿐, 실제 측정값(가격, 비율, 점수 등)이 기준 이상으로 올라갈 수도 있습니다.
3. 히스토그램의 범위 설정
Matplotlib 등에서 히스토그램을 그릴 때, 기본적으로 데이터의 최솟값과 최댓값을 포함하는 범위로 x축을 설정합니다.
일부 값이 1을 초과한다면, 자동으로 1보다 큰 구간(bin)까지 표시합니다.
- 파이썬 설치 -> 3.13.2 버전 설치
- git repository 받아서 vs code로 열기
bid_simulator라는 이름으로 가상환경 만들기
=> vs code 내부에 만들어야함
py -3.13 -m venv bid_simulator- 다운 받을 때 가상환경 실행 후 그 안에서 다운 받아야함
pip install -r requirements.txt입력 후 가상환경에 필요한 버전으로 다운받기
#requirements.txt 내부 코드
contourpy==1.3.1
cycler==0.12.1
fonttools==4.56.0
kiwisolver==1.4.8
matplotlib==3.10.0
numpy==2.2.3
packaging==24.2
pandas==2.2.3
pillow==11.1.0
pyparsing==3.2.1
python-dateutil==2.9.0.post0
pytz==2025.1
scipy==1.15.2
seaborn==0.13.2
six==1.17.0
tqdm==4.67.1
tzdata==2025.1pip list입력 -> 다운 받았는지 확인하기- ctrl + shift + P -> 팔레트 열림 ->
Python:Select Interpreter

사진 처럼 나오고 거기서 bid_simulator라는 가상환경 누르면 됨 - 평소에 가상 환경 실행 시 =>
. .\bid_simulator\Scripts\activate.ps1코드 입력
- simulator.py 실행시키기
