Data 전처리(Data Preprocessing)란
- Raw Data을 학습하기 전에 변경하는 작업
- Garbage in, Garbage out.
- 좋은 train dataset으로 학습 해야 좋은 예측 결과를 만드는 모델을 학습할 수 있다.
- 좋은 train dataset을 만드는 것은 모델의 성능에 가장 큰 영향을 준다.
- Garbage in, Garbage out.
- 목적에 따른 전처리 분류
- 학습이 가능한 데이터셋을 만들기 위한 전처리
- 머신러닝 알고리즘은 숫자만 처리할 수 있다. (수식이므로) 그래서 결측치, 문자열이 있으면 학습이나 추론을 할 수 없다.
- 학습이 더 잘되도록 만들기 위한 전처리
- 공학적 전처리 (Feature Engineering)
- 도메인 지식에 의한 전처리
- 학습이 가능한 데이터셋을 만들기 위한 전처리
결측치 처리
-
결측치 (Not Available-NA, NaN, None, Null)
- 수집하지 못한 값. 모르는 값.
-
머신러닝 알고리즘은 데이터셋에 결측치가 있으면 학습이나 추론을 하지 못하기 때문에 적절한 처리가 필요하다.
- 결측치 처리는 데이터 전처리 단계에서 진행한다.
-
결측치 처리방법
- 제거 (열단위, 행단위)
- 행단위를 기본으로 하는데 특정 열에 결측치가 너무 많을 경우 열을 제거할 수 있다.
- 다른 값으로 대체
- 가장 가능성이 높은 값으로 대체
- 수치형: 평균, 중앙값,
- 범주형: 최빈값(출연 빈도가 가장 많은 값)
- 그 Feature의 결측치를 예측하는 머신러닝 알고리즘을 모델링해서 추론
- 결측치 자체를 표현하는 값을 만들어서 대체
- 나이에 -1, 혈액형에 ? 같와 같이 그 Feature가 가질 수 없는 값으로 결측치를 표현하는 값을 정한 뒤 대체한다.
- 가장 가능성이 높은 값으로 대체
- 제거 (열단위, 행단위)
결측치 제거
- Pandas
dataframe.isnull(),dataframe.isna()- 원소별 결측치 인지 여부 확인
dataFrame.dropna(axis=0, subset=None, inplace=False)- 결측치 제거
- axis=0(default): 결측치가 있는 행을 삭제, axis=1: 결측치가 있는 열을 삭제
- subset: 결측치가 있으면 제거할 열이나 행을 지정한다.
- inplace=False(default): 결측치를 제거한 결과 DataFrame을 생성해서 반환. inplace=True: 원본 dataframe에 적용한다.
결측치 다른 값으로 대체
- Pandas
dataframe.fillna(value)- value: 결측치를 채울 값을 지정한다.
- scalar: 지정한 값으로 모두 채운다.
- dictionary: key-컬럼명, value-채울값
- 컬럼별로 다른 값으로 채운다.
- value: 결측치를 채울 값을 지정한다.
- scikit-learn
sklearn.impute.SimpleImputertransformer 클래스 사용- 주요 매개변수
- strategy="mean"
- 결측치를 어떤 값으로 변경할지를 설정.
- "mean": default로 평균값으로 변경한다.
- "median": 중앙값으로 변경한다.
- "mean", "median"은 연속형 feature에 적용한다.
- "most_frequent": 최빈값으로 변경한다. 범주형 feature에 적용한다.
- "constant": 매개변수 fill_value에 설정한 값으로 변경한다.
- strategy="mean"
- 주요 매개변수
전처리 예시 적용
import pandas as pd
import numpy as np
data = {
"col1":[10, np.nan, 30, 40],
"col2":['A', 'A', 'C', np.nan],
"col3":[10.5, 2.8, np.nan, 9.7]
}
df = pd.DataFrame(data)
df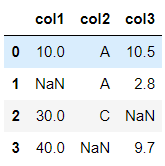
# 결측치 확인
df.isna().sum()col1 1
col2 1
col3 1
dtype: int64
#### 제거
df.dropna()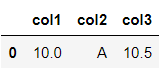
df.dropna(subset=['col1' ,'col3'] 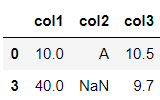
df.dropna(axis=1, subset=[1, 2])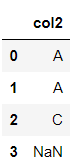
#### 변경
df.fillna(10)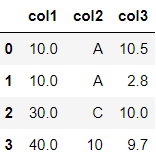
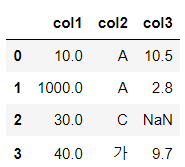
df.fillna({
"col1":1000,
"col2":"가"
})
from sklearn.impute import SimpleImputer
imputer_con = SimpleImputer(strategy="median")
imputer_cate = SimpleImputer(strategy="most_frequent")
# 연속형
r1 = imputer_con.fit_transform(df[['col1', 'col3']])
r1array([[10. , 10.5],
[30. , 2.8],
[30. , 9.7],
[40. , 9.7]])# 범주형
r2 = imputer_cate.fit_transform(df[['col2']])
r2array([['A'],
['A'],
['C'],
['A']], dtype=object)np.concatenate([r1, r2], axis=1)array([[10.0, 10.5, 'A'],
[30.0, 2.8, 'A'],
[30.0, 9.7, 'C'],
[40.0, 9.7, 'A']], dtype=object)이상치(Outlier) 처리
-
의미 그대로 이상한 값, 튀는 값, 패턴을 벗어난 값으로 그 Feature를 가지는 대부분의 값들과는 동떨어진 값을 말한다.
-
오류값
- 잘못 수집 된 값.
- 처리
- 결측치로 변환 후 처리를 한다.
-
극단치(분포에서 벋어난 값)
- 정상적인 값이지만 다른 값들과 다른 패턴을 가지는 값.
- 일반적으로 극단적으로 크거나 작은 값
- 처리
- 그 값을 그대로 유지한다.
- 결측치로 변환 후 처리를 한다.
- 다른 값으로 대체한다.
- 보통 그 값이 가질 수 있는 Min/Max값을 설정한 뒤 그 값으로 변경한다.
Feature 타입 별 전처리
통계에서의 데이터 타입
-
어떤 종류의 값을 모았는지에 따라 크게 범주형과 수치형으로 나눈다.
통계적으로 데이터형식을 나누는 기준은 여러가지가 있다.
-
범주형(Categorical) 변수
- 개별값들이 이산적(Discrete)이며 값이 가질수 있는 대상값이 몇가지 범주(Category)로 정해져 있는 데이터 타입.
- 명목(Norminal) 변수/비서열(Unordered) 변수
- 범주에 속한 값 사이에 서열(순위)가 없는 변수로 단순 분류가 목적인 타입.
- 성별, 혈액형
- 순위(Ordinal) 변수/서열(Ordered) 변수
- 범주에 속한 값들 사이에 서열(순위)가 있는 변수.
- 성적, 직급, 만족도
이산적(Discrete): 대상 값이 연속적이지 않고 떨어져 있는 형태
- 수치형(Numerical) 변수
- 숫자 데이터 타입이다. 보통 중복된 값이 없거나 적고 값으로 올수 있는 대상이 정해져 있지 않다. 이산형과 연속형 변수로 구성된다.
- 이산형(Discrete)
- 수치적 의미를 가지나 실수(소숫점형태)로 표현되지 않는 값들을 의미한다.
- 물건의 재고량, 가격(원), 사고발생 건수
- 연속형(Continuous)
- 수치적 의미를 가지고 실수(소숫점)로 표현이 가능한 측정 할 수 있는 값들을 의미한다.
- 키, 몸무게, 시간
- 동일한 데이터도 어떻게 표현하느냐에 따라 다양한 타입으로 표현가능하다.
- 예를들어 몸무게는 그 자체가 연속형이지만 50kg대, 60kg대,.. 이렇게 묶어서 표현하면 범주형이 된다.
- 파이썬 데이터 타입별
- 실수형 데이터로 구성된 Feature는 연속형 값이다.
- 문자열 데이터로 구성된 Feature는 단순 문자열값이거나 범주형 값이다.
- 정수형 데이터로 구성된 Feature는 범주형이거나 일반 수치형(이산형) 값이다.
- 몇개의 고유값으로 구성되었는지를 봐야 한다.
범주형 데이터 전처리
- Scikit-learn의 머신러닝 API들은 Feature나 Label의 값들이 숫자(정수/실수)인 것만 처리할 수 있다.
- 문자열(str)일 경우 숫자 형으로 변환해야 한다.
- 범주형 변수의 경우 전처리를 통해 정수값으로 변환한다.
- 범주형이 아닌 단순 문자열인 경우 일반적으로 제거한다.
범주형 Feature의 처리
- Label Encoding
- One-Hot Encoding
레이블 인코딩(Label encoding)
-
범주형 Feature의 고유값들 오름차순 정렬 후 0 부터 1씩 증가하는 값으로 변환
-
숫자의 크기의 차이가 모델에 영향을 주지 않는 트리 계열 모델(의사결정나무, 랜덤포레스트)에 적용한다.
-
숫자의 크기의 차이가 모델에 영향을 미치는 선형 계열 모델(로지스틱회귀, SVM, 신경망)에는 사용하면 안된다.
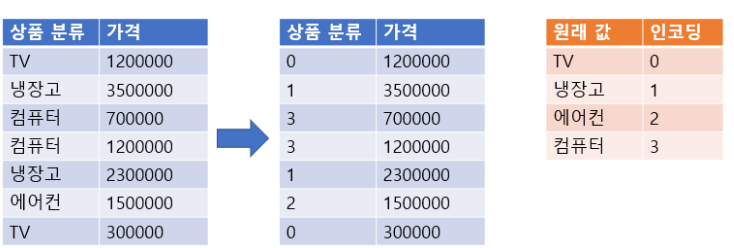
-
sklearn.preprocessing.LabelEncoder 사용
- fit(): 어떻게 변환할 지 학습
- transform(): 문자열를 숫자로 변환
- fit_transform(): 학습과 변환을 한번에 처리
- inverse_transform():숫자를 문자열로 변환
- classes_ : 인코딩한 클래스 조회
items = ['TV', '냉장고', '컴퓨터', '컴퓨터', '냉장고', '에어콘', 'TV', '에어콘']
from sklearn.preprocessing import LabelEncoder
# LabelEncoder생성
le = LabelEncoder()
# 학습
le.fit(items)
# 변환
item_label = le.transform(items)
item_labelarray([0, 1, 3, 3, 1, 2, 0, 2])# 인코딩된 클래스를 확인
le.classes_ array(['TV', '냉장고', '에어콘', '컴퓨터'], dtype='<U3')# 디코딩 (class(인코딩된 정수)->class name(원래 문자열))
le.inverse_transform([3, 2, 2, 1, 0, 0])array(['컴퓨터', '에어콘', '에어콘', '냉장고', 'TV', 'TV'], dtype='<U3')####### fit()과 transform()의 대상이 같은경우 -> fit_transform()
le2 = LabelEncoder()
item_label2 = le2.fit_transform(items)
print(item_label2)
print(le2.classes_)[0 1 3 3 1 2 0 2]
['TV' '냉장고' '에어콘' '컴퓨터']####### fit() 대상과 transform()대상이 다른경우
class_names = ["냉장고", "TV", "에어콘", "컴퓨터", "노트북", "스마트폰"]
le3 = LabelEncoder()
le3.fit(class_names)
print(le3.classes_)['TV' '냉장고' '노트북' '스마트폰' '에어콘' '컴퓨터']item_label3 = le3.transform(items)
print(item_label3)[0 1 5 5 1 4 0 4]# 학습대상에 없는 class를 변환하면 Exception 발생.
le3.transform(["컴퓨터", "녹차"])adult dataset 에 label encoding 적용
- Adult 데이터셋은 1994년 인구조사 데이터 베이스에서 추출한 미국 성인의 소득 데이터셋이다.
- target 은 income 이며 수입이 $50,000 이하인지 초과인지 두개의 class를 가진다.
- https://archive.ics.uci.edu/ml/datasets/adult
데이터 로딩
cols = ['age', 'workclass','fnlwgt','education', 'education-num', 'marital-status', 'occupation','relationship', 'race', 'gender','capital-gain','capital-loss', 'hours-per-week','native-country', 'income']
import pandas as pd
data = pd.read_csv('data/adult.data',
header=None, # 첫번째 줄을 Data로 읽는다.
names=cols, # 컬럼명 지정
skipinitialspace=True,
na_values="?")
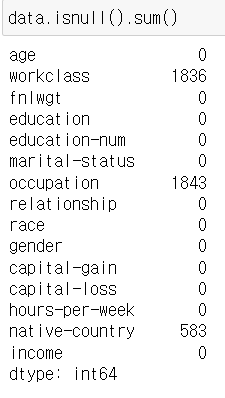
data.shape(32561, 15)data.head()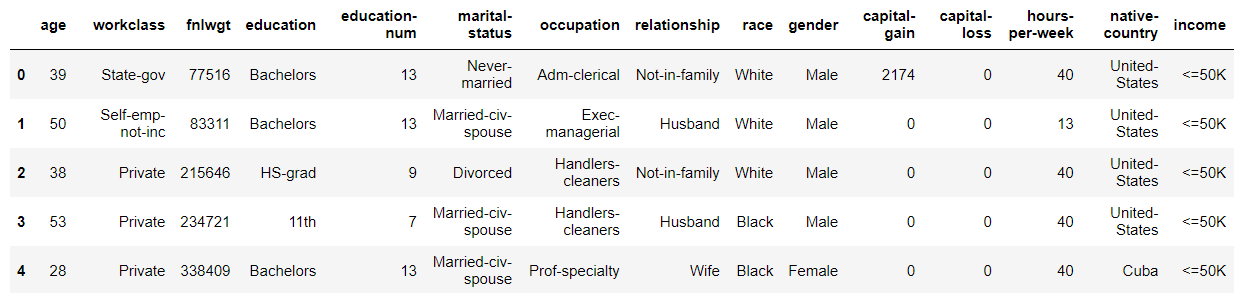
# 결측치를 제거
df = data.dropna()
data.shape, df.shape((32561, 15), (30162, 15))
df['income'].value_counts()income
<=50K 22654
>50K 7508
Name: count, dtype: int64df['income'].value_counts(normalize=True)income
<=50K 0.751078
>50K 0.248922
Name: proportion, dtype: float64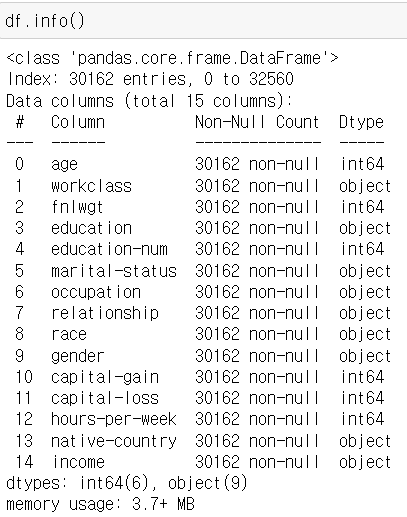
TODO: adult dataset - 레이블 인코딩 처리
- 범주형: 'workclass','education', 'marital-status', 'occupation','relationship', 'race', 'gender','native-country', 'income'
- 연속형: 'age', fnlwgt', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week'
encoding_columns 컬럼들은 Label Encoding 처리,
not_encoding_columns 컬럼들의 값들은 그대로 유지.
encoding_columns의 값들은 LabelEncoding 된 값으로 not_encoding_columns의 값들은 원래값 그대로 구성된 DataFrame을 생성해서 반환한다.
주의: LabelEncoding은 Feature(컬럼) 별로 처리해야 한다. 한번에 여러컬럼을 하나의 LabelEncoder로 처리할 수 없다.
adult_df = df.copy()
from sklearn.preprocessing import LabelEncoder
encoding_class = ['workclass','education', 'marital-status', 'occupation','relationship', 'race', 'gender','native-country', 'income']
not_encoding_class = ['age', 'fnlwgt', 'education-num', 'capital-gain', 'capital-loss', 'hours-per-week']
le4 = LabelEncoder()
for column in encoding_class:
adult_df[column] = le4.fit_transform(adult_df[column])
adult_df.head()
Adult dataset의 income 추론 모델링
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score데이터 분할
- X, y 나누기
- train/validation/test set 나누기
# adult_df 에서 X, y 분리
X = adult_df.drop(columns='income')
y = adult_df['income']# Train set, Validation set, Test set 분리
X_tmp, X_test, y_tmp, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=0)
X_train, X_val, y_train, y_val = train_test_split(X_tmp, y_tmp, test_size=0.2,
stratify=y_tmp, random_state=0)
print(X_train.shape, X_val.shape, X_test.shape)
print(y_train.shape, y_val.shape, y_test.shape)(19303, 14) (4826, 14) (6033, 14)
(19303,) (4826,) (6033,)모델링
- 모델: DecisionTreeClassifier
- 평가지표: 정확도(accuracy)
max_depth = 7
# 모델 생성
tree = DecisionTreeClassifier(max_depth=max_depth, random_state=0)
# train(학습/훈련)
tree.fit(X_train, y_train)
# 검증 (train/val set)
## 추론
pred_train = tree.predict(X_train)
pred_val = tree.predict(X_val)
## 정확도 검증
train_acc = accuracy_score(y_train, pred_train)
val_acc = accuracy_score(y_val, pred_val)
# 검증결과 확인(출력)
print(f"max_depth: {max_depth}")
print(f"train 정확도: {train_acc}, validation 정확도: {val_acc}")max_depth: 7
train 정확도: 0.8564471843754857, validation 정확도: 0.855781185246581-> train 정확도 < validation 정확도 일 경우의 하이퍼파라미터를 사용하는 것이 더 좋다.
최종평가
- test set으로 최종평가
best_model = DecisionTreeClassifier(max_depth = 7, random_state = 0)
best_model.fit(X_train, y_train)
pred_test = best_model.predict(X_test)
accuracy_score(y_test, pred_test)0.8488314271506713
원핫 인코딩(One-Hot encoding)
- N개의 클래스를 N 차원의 One-Hot 벡터로 표현되도록 변환
- 고유값들을 피처(컬럼)로 만들고 정답에 해당하는 열은 1로 나머진 0으로 표시한다..
- 숫자의 크기 차이가 모델에 영향을 미치는 선형 계열 모델(로지스틱회귀, SVM, 신경망)에서 범주형 데이터 변환시 Label Encoding보다 One Hot Encoding을 사용한다.
- DecisionTree 계열의 알고리즘은 Feature에 0이 많은 경우(Sparse Matrix라고 한다.) 성능이 떨어지기 때문에 Label Encoding을 한다.
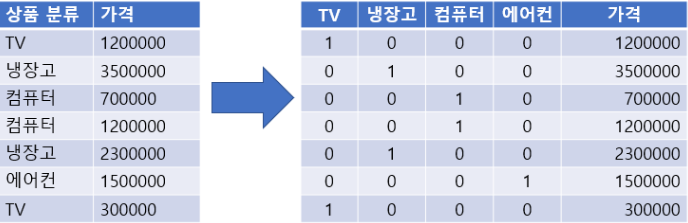
One-Hot Encoding 변환 처리
- Scikit-learn
- sklearn.preprocessing.OneHotEncoder 이용
- fit(데이터셋): 데이터셋을 기준으로 어떻게 변환할 지 학습
- transform(데이터셋): Argument로 받은 데이터셋을 원핫인코딩 처리
- fit_transform(데이터셋): 학습과 변환을 한번에 처리
- get_feature_names_out() : 원핫인코딩으로 변환된 Feature(컬럼)들의 이름을 반환
- 데이터셋은 2차원 배열을 전달 하며 Feature별로 원핫인코딩 처리한다.
- DataFrame도 가능
- 원핫인코딩 처리시 모든 타입의 값들을 다 변환한다. (연속형 값들도 변환) 그래서 변환려는 변수들만 모아서 처리해야 한다.
- sklearn.preprocessing.OneHotEncoder 이용
import numpy as np
items=np.array(['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서', "냉장고"])
items.shape(9,)
-> 데이터셋이 1차원 배열로 구성되어 있어서 원핫인코딩 처리가 불가능하다.
items = items[..., np.newaxis] # 더미 추가 / items.reshape(-1, 1) 가능
print(items.shape)
itemsarray([['TV'],
['냉장고'],
['전자렌지'],
['컴퓨터'],
['선풍기'],
['선풍기'],
['믹서'],
['믹서'],
['냉장고']], dtype='<U4')from sklearn.preprocessing import OneHotEncoder
# OneHotEncoder 객체 생성
ohe = OneHotEncoder()
# ohe = OneHotEncoder(sparse_output=False) # 결과를 ndarray로 반환. True(기본값) : csr_matrix로 반환.
# 굳이 ndarray로 반환할 필요는 없으나 값을 확인하려면 변경해서 확인해야한다.
# 학습
ohe.fit(items)
# 변환
result = ohe.transform(items)
result.shape(9,6)
ohe.get_feature_names_out()array(['x0_TV', 'x0_냉장고', 'x0_믹서', 'x0_선풍기', 'x0_전자렌지', 'x0_컴퓨터'],
dtype=object)result.toarray()array([[1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 1.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 1., 0., 0., 0., 0.]])type(result)scipy.sparse._csr.csr_matrix
pd.DataFrame(result.toarray(), columns=ohe.get_feature_names_out())
수치형 데이터 전처리
Feature Scaling(정규화)
- 데이터의 속성인 각 feature들간의 값의 척도(Scale)를 같은 기준으로 통일한다.
척도: 값을 측정하거나 평가하는 단위. ex) cm, km, kg
- 트리계열을 제외한 대부분의 머신러닝 알고리즘들이 feature간의 서로 다른 척도(Scale)에 영향을 받는다.
- 선형모델, SVM 모델, 신경망 모델
- Scaling(정규화)은 train set으로 학습(fitting) 한다. test set, validation set 그리고 모델이 예측할 새로운 데이터는 train set으로 학습한 scaler를 사용해 변환만 한다.
- test set과 validation set은 모델이 앞으로 예측할 새로운 데이터에 대해 어느 정도 성능을 가지는지를 평가하는 용으로 쓰인다. 그런데 새로운 데이터들이 모델링할 때 사용할 데이터셋(sample)의 scale과 같다라고 보장할 수 없으므로 전체 sample 데이터셋을 학습 시킨 뒤 train/validation/test 으로 나누는 것은 모델의 정확한 성능평가를 할 수 없다.
종류
- 표준화(Standardization) Scaling
- StandardScaler 사용
- Min Max Scaling
- MinMaxScaler 사용
-> StandardScaler 와 Min Max Scaling 둘 중 어떤 Scaling을 사용해야 하는지에 대한 기준은 없다. 둘 다 해보고 결과를 보고 판단.(보통 StandardScaler 의 경우가 성능이 좋게 나옴)
