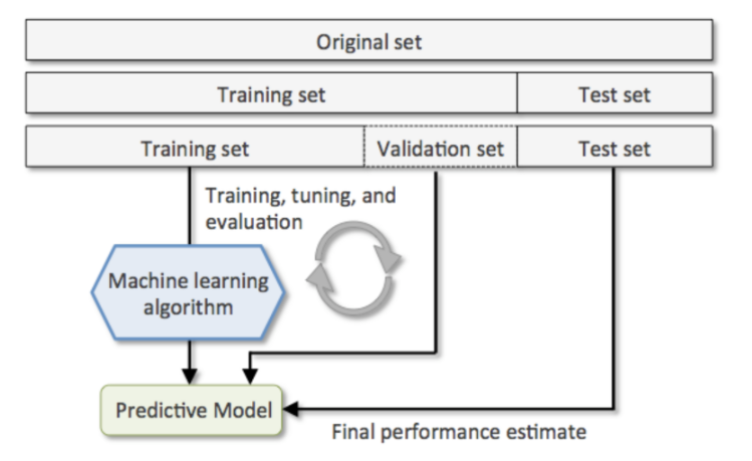
모델 성능 평가를 위한 데이터셋 분리
데이터셋(Dataset)
- Train 데이터셋 (훈련/학습 데이터셋)
- 모델을 학습시킬 때 사용할 데이터셋.
- Validation 데이터셋 (검증 데이터셋)
- 모델의 성능 중간 검증을 위한 데이터셋
- Test 데이터셋 (평가 데이터셋)
- 모델의 성능을 최종적으로 측정하기 위한 데이터셋
- Test 데이터셋은 마지막에 모델의 성능을 측정하는 용도로 한번만 사용되야 한다.
- 모델을 훈련하고 평가했을때 원하는 성능이 나오지 않으면 데이터나 모델 학습을 위한 설정(하이퍼파라미터)을 수정한 뒤에 다시 훈련시키고 평가를 하게 된다. 원하는 성능이 나올때 까지 설정변경(대부분 하이퍼파라미터)->훈련->검증을 반복하게 된다.
- 위 사이클을 반복하게 되면 평가결과를 바탕으로 설정을 변경하게 되므로 검증할 때 사용한 데이터셋에 모델이 맞춰서 훈련하는 것과 동일한 효과를 내게 된다. (설정을 변경하는 이유가 Test set에 대한 결과를 좋게 만들기 위해 변경하므로) 그래서 Train dataset과 Test dataset 두 개의 데이터셋만 사용하게 되면 모델의 성능을 제대로 평가할 수 없게 된다. 그래서 데이터셋을 train 세트, validation 세트, test 세트로 나눠 train set 와 validation set으로 모델을 최적화 한 뒤 마지막에 test set으로 최종 평가를 한다.
- 머신러닝 모델 파라미터
- 성능에 영향을 주는 값으로 최적의 성능을 내는 값을 찾아야 한다.
- 하이퍼파라미터(Hyper Parameter)
- 사람이 직접 설정해야하는 파라미터 값
- 파라미터(Parameter)
- 데이터 학습을 통해 찾는 파라미터 값
Hold Out - Data분리 방식 1
- 데이터셋을 Train set, Validation set, Test set으로 나눈다.
- sklearn.model_selection.train_test_split() 함수 사용
- 하나의 데이터셋을 2분할 하는 함수
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import numpy as npX, y = load_iris(return_X_y=True)
X.shape, y.shape((150, 4), (150,)-> return_X_y = True : input(X), output(y) 값만 조회.(디폴트는 False)
Train/Test set 분리
- 전체 데이터셋에서 Test set을 분리
X_tmp, X_test, y_tmp, y_test = train_test_split(X,
y,
test_size=0.2,
stratify=y,
random_state=0
)
X_tmp.shape, X_test.shape, y_tmp.shape, y_test.shape((120, 4), (30, 4), (120,), (30,))-> stratify 는 분류에스는 필수로 처리해야한다.(원본데이터셋의 클래스별 비율을 유지하면서 나눠지도록 처리)
-> random_state 는 random seed 값 처리
np.unique(y, return_counts=True)(array([0, 1, 2]), array([50, 50, 50], dtype=int64))-> stratify 로 인해 1 : 1 : 1 비율
np.unique(y_tmp, return_counts=True)[1]/120array([0.33333333, 0.33333333, 0.33333333])np.unique(y_test, return_counts=True)(array([0, 1, 2]), array([10, 10, 10], dtype=int64))-> 클래스별 갯수가 다를때 비율확인 해야 한다.
Train/Validation/Test set 분리
- tmp를 train/validation으로 분리
X_train, X_val, y_train, y_val = train_test_split(X_tmp, y_tmp, test_size=0.2, stratify=y_tmp, random_state=0)X_train.shape, X_val.shape, X_test.shape((96, 4), (24, 4), (30, 4))모델 학습->검증->튜닝
max_depth = 1
# max_depth = 2
# max_depth = 3
# max_depth = 5
tree = DecisionTreeClassifier(max_depth=max_depth, random_state=0)
tree.fit(X_train, y_train)
pred_train = tree.predict(X_train)
pred_val = tree.predict(X_val)
train_acc = accuracy_score(y_train, pred_train)
val_acc = accuracy_score(y_val, pred_val)-> max_depth : Decision Tree의 하이퍼파라미터 중 하나
print(f"max_depth: {max_depth}")
print("train set 정확도:", train_acc)
print("val set 정확도:", val_acc)max_depth: 1
train set 정확도: 0.6666666666666666
val set 정확도: 0.6666666666666666max_depth: 2
train set 정확도: 0.9583333333333334
val set 정확도: 1.0max_depth: 3
train set 정확도: 0.9583333333333334
val set 정확도: 0.9583333333333334max_depth: 5
train set 정확도: 1.0
val set 정확도: 1.0Testset으로 최종검증
pred_test = tree.predict(X_test)
test_acc = accuracy_score(y_test, pred_test)
print('test set 정확도:', test_acc)test set 정확도: 0.9666666666666667Hold out 방식의 단점
- train/validation/test 셋이 어떻게 나눠 지냐에 따라 결과가 달라진다.
- 데이터가 충분히 많을때는 변동성이 흡수되 괜찮으나 적을 경우 문제가 발생할 수 있다.
- 이상치에 대한 영향을 많이 받는다.
- 다양한 패턴을 찾을 수가 없기 때문에 새로운 데이터에 대한 예측 성능이 떨어지게 된다.
- 데이터가 충분히 많을때는 변동성이 흡수되 괜찮으나 적을 경우 문제가 발생할 수 있다.
- Hold out 방식은 (다양한 패턴을 가진) 데이터의 양이 많을 경우에 사용한다.
K-겹 교차검증 (K-Fold Cross Validation) - Data분리 방식 2
- 데이터셋을 설정한 K 개로 나눈다.
- K개 중 하나를 검증세트로 나머지를 훈련세트로 하여 모델을 학습시키고 평가한다.
- K개 모두가 한번씩 검증세트가 되도록 K번 반복하여 모델을 학습시킨 뒤 나온 평가지표들을 평균내서 모델의 성능을 평가한다.
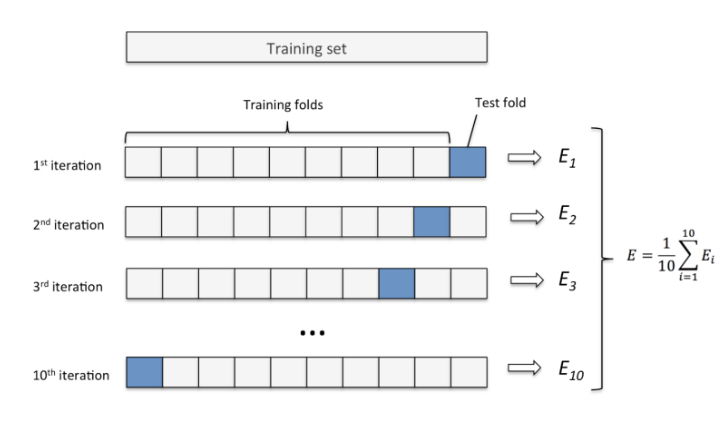
- 데이터양이 충분치 않을때 사용한다.
- 보통 Fold를 나눌때 2.5:7.5 또는 2:8 비율이 되게 하기 위해 4개 또는 5개 fold로 나눈다.
- 종류
- KFold
- 회귀문제의 Dataset을 분리할 때 사용
- StratifiedKFold
- 분류문제의 Dataset을 분리할 때 사용
- KFold
Boston Housing DataSet
보스톤의 지역별 집값 데이터셋
- CRIM : 지역별 범죄 발생률
- ZN : 25,000 평방피트를 초과하는 거주지역의 비율
- INDUS: 비상업지역 토지의 비율
- CHAS : 찰스강에 대한 더미변수(강의 경계에 위치한 경우는 1, 아니면 0)
- NOX : 일산화질소 농도
- RM : 주택 1가구당 평균 방의 개수
- AGE : 1940년 이전에 건축된 소유주택의 비율
- DIS : 5개의 보스턴 고용센터까지의 접근성 지수
- RAD : 고속도로까지의 접근성 지수
- TAX : 10,000 달러 당 재산세율
- PTRATIO : 지역별 교사 한명당 학생 비율
- B : 지역의 흑인 거주 비율
- LSTAT: 하위계층의 비율(%)
- MEDV : Target 지역의 주택가격 중앙값 (단위: $1,000)
import pandas as pd
boston = pd.read_csv('data/boston_hosing.csv')
boston.shape(506, 14)boston.head()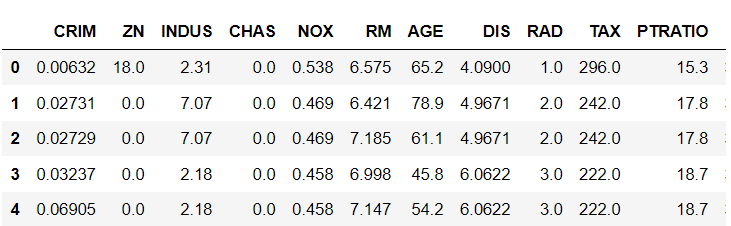
boston.CHAS.value_counts()CHAS
0.0 471
1.0 35
Name: count, dtype: int64boston.info()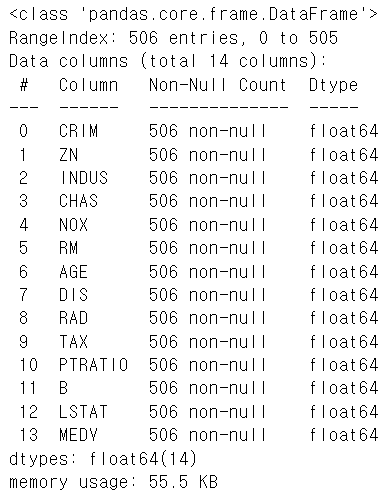
X = boston.drop(columns='MEDV').values
y = boston['MEDV'].values-> X ('MEDV' 컬럼 제외한 데이터), y ('MEDV' 컬럼 데이터)
X[:3]
# 6.3e-03 -> 6.3 ** -3 array([[6.3200e-03, 1.8000e+01, 2.3100e+00, 0.0000e+00, 5.3800e-01,
6.5750e+00, 6.5200e+01, 4.0900e+00, 1.0000e+00, 2.9600e+02,
1.5300e+01, 3.9690e+02, 4.9800e+00],
[2.7310e-02, 0.0000e+00, 7.0700e+00, 0.0000e+00, 4.6900e-01,
6.4210e+00, 7.8900e+01, 4.9671e+00, 2.0000e+00, 2.4200e+02,
1.7800e+01, 3.9690e+02, 9.1400e+00],
[2.7290e-02, 0.0000e+00, 7.0700e+00, 0.0000e+00, 4.6900e-01,
7.1850e+00, 6.1100e+01, 4.9671e+00, 2.0000e+00, 2.4200e+02,
1.7800e+01, 3.9283e+02, 4.0300e+00]])y[:3] # y의 컬럼 타입이 연속형 => Regression(회귀) 문제array([24. , 21.6, 34.7])KFold
- 지정한 개수(K)만큼 분할한다.
- Raw dataset의 순서를 유지하면서 지정한 개수로 분할한다.
- 회귀 문제일때 사용한다.
- KFold(n_splits=K)
- 몇개의 Fold로 나눌지 지정
- KFold객체.split(데이터셋)
- 데이터셋을 지정한 K개 나눴을때 train/test set에 포함될 데이터의 index들을 반환하는 generator 생성
Generator란
- 연속된 값을 제공(생성)하는 객체. 연속된 값을 한번에 메모리에 저장하지 않고 필요시마다 순서대로 하나씩 제공한다.
- 함수형식으로 구현하며 return 대신 yield를 사용한다.
from sklearn.model_selection import KFold
kf = KFold(n_splits=3)
gen = kf.split(X)
type(gen)v1 = next(gen)
print(type(v1), len(v1))<class 'tuple'> 2v1[0].shape, v1[1].shape((337,), (169,))KFold를 이용해 Boston housing dataset 교차검증
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error
import numpy as np
# fold(iteration)별 검증 결과를 담을 리스트
mse_list = []
#1. KFold 객체 생성 - 폴드개수 (K) 를 설정
kfold = KFold(n_splits=5)
#2. split을 이용해서 generator 생성
index_gen = kfold.split(X)
#3. 반복문 -> 각 folder별 iteration을 처리.
tree = DecisionTreeRegressor(random_state=0)
for train_index, val_index in index_gen:
# train/val dataset을 생성
X_train, y_train = X[train_index], y[train_index]
X_val, y_val = X[val_index], y[val_index]
# 모델 학습
tree.fit(X_train, y_train)
# 검증
## 추론
pred_val = tree.predict(X_val)
## 검증 - mse
mse = mean_squared_error(y_val, pred_val)
mse_list.append(mse)
mse_list[11.887843137254906,
34.88990099009901,
28.17247524752476,
54.44178217821782,
52.59029702970297]np.mean(mse_list), np.sqrt(np.mean(mse_list))(36.39645971655989, 6.032947846331832)회귀는 몇 개를 맞췄는지를 볼 수가 없다.
연속된 값이기 때문에
| y | pred | diff |
|---|---|---|
| 4 | 7 | -3 |
| 6 | 9 | -3 |
| 5 | 3 | 2 |
맞았는지, 틀렸는지 확인하기 위함.(거리가 얼마나 멀어졌는지 확인)
위의 차이 만큼을 |-3, -3, 2| 각 제곱해서 평균.
따라서
np.mean(mse_list) 6.03 의 제곱한 값을 산출
-> np.sqrt(np.mean(mse_list)) 6.03 정도의 오차가 발생
StratifiedKFold
- 분류문제일 때 사용한다.
- 전체 데이터셋의 class별 개수 비율과 동일한 비율로 fold들이 나뉘도록 한다.
- StratifiedKFold(n_splits=K)
- 몇개의 Fold로 나눌지 지정
- StratifiedKFold객체.split(X, y)
- 데이터셋을 지정한 K개 나눴을때 train/test set에 포함될 데이터의 index들을 반환하는 generator 생성
- input(X)와 output(y) dataset을 전달한다.
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X, y = load_iris(return_X_y=True)
skf = StratifiedKFold(n_splits=3)
s_gen = skf.split(X, y)
print(type(s_gen))<class 'generator'>v1 = next(s_gen)
print(type(v1), len(v1))<class 'tuple'> 2v1[0]array([ 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29,
30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42,
43, 44, 45, 46, 47, 48, 49, 67, 68, 69, 70, 71, 72,
73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85,
86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98,
99, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127,
128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140,
141, 142, 143, 144, 145, 146, 147, 148, 149])v1[1]array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 50, 51, 52, 53, 54, 55, 56, 57, 58,
59, 60, 61, 62, 63, 64, 65, 66, 100, 101, 102, 103, 104,
105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115])iris dataset 교차 검증
acc_list = []
#1. KFold 객체 생성 - 폴드개수 (K) 를 설정
s_kfold = StratifiedKFold(n_splits=4)
#2. split을 이용해서 generator 생성
index_gen_iris = s_kfold.split(X, y)
#3. 반복문 -> 각 folder별 iteration을 처리.
tree_clf = DecisionTreeClassifier(random_state=0)
for train_idx, val_idx in index_gen_iris:
# train/val dataset을 생성
X_train, y_train = X[train_idx], y[train_idx]
X_val, y_val = X[val_idx], y[val_idx]
# 모델학습
tree_clf.fit(X_train, y_train)
# 검증
## 추론
pred = tree_clf.predict(X_val)
acc = accuracy_score(y_val, pred)
## 검증
acc_list.append(acc)
acc_list[0.9736842105263158, 0.9473684210526315, 0.9459459459459459, 1.0]np.mean(acc_list)0.9667496443812233함수화
def cv(model, X, y, k, metrics):
s_kfold = StratifiedKFold(n_splits=k)
index_gen = s_kfold.split(X, y)
result_list = []
for train_idx, val_idx in index_gen:
X_train, y_train = X[train_idx], y[train_idx]
X_val, y_val = X[val_idx], y[val_idx]
model.fit(X_train, y_train)
pred = model.predict(X_val)
acc = metrics(y_val, pred)
result_list.append(acc)
return result_listresult = cv(DecisionTreeClassifier(random_state=0),
X, y,
4,
accuracy_score)
result[0.9736842105263158, 0.9473684210526315, 0.9459459459459459, 1.0] -> 분류파트는 반복적인 알고리즘이기 때문에 함수화가 가능하다.
Cross Validation Utility 함수
cross_val_score( )
- 데이터셋을 K개로 나누고 K번 반복하면서 평가하는 작업을 처리해 주는 함수
- 주요매개변수
- estimator: 모델객체
- X: feature
- y: label
- scoring: 평가지표
- cv: 나눌 개수 (K)
- 정수: 개수
- KFold 타입 객체
- 반환값: array - 각 반복마다의 평가점수
cross_validate()
- cross_val_score()는 한개의 평가지표만 사용할 수 있는데 반해 cross_validate()는 여러개의 평가지표를 설정할 수 있다.
- 주요 매개변수
- 주요매개변수
- estimator: 모델객체
- X: feature
- y: label
- scoring: 평가지표. 여러개 평가지표를 설정할 경우 list나 tuple로 묶어서 전달한다.
- cv: 나눌 개수 (K)
- 정수: 개수
- KFold 타입 객체
- 반환값: dictionary
# 보스톤데이터셋 - 회귀
df = pd.read_csv('data/boston_hosing.csv')
X_boston = df.drop(columns='MEDV').values
y_boston = df['MEDV'].values
# iris - 분류
X_iris, y_iris = load_iris(return_X_y=True)from sklearn.model_selection import cross_val_score, cross_validate
result_boston = cross_val_score(DecisionTreeRegressor(random_state=0, max_depth=3),
X=X_boston,
y=y_boston,
scoring="neg_mean_squared_error",
cv=4,
n_jobs=-1
)neg 의 값을 주는 이유는 ?? scoring="neg_mean_squared_error"
- acc 같은 경우 0.5 < 0.9 값이 높을 수록 성능이 좋다.
- mean_squared 같은 경우 정답과 모델 예측 데이터 값의 차이를 나타내는 경우이므로 0.5 > 0.9 와 같이 낮을 수록 성능이 좋다.
따라서 해당 평가 scoring 에 neg(음수)를 붙여서 적용시켜준다.
from sklearn.model_selection import cross_val_score, cross_validate
result_boston = cross_val_score(DecisionTreeRegressor(random_state=0, max_depth=3),
X=X_boston,
y=y_boston,
scoring="neg_mean_squared_error",
cv=4, # fold 개수 KFold(n_splits=4)
n_jobs=-1 #병렬처리할 때 사용할 cpu의 프로세서 개수 default 1개, -1 모든 프로세서 사용
)n_jobs
- 모델링 할 때 시간이 오래 걸리기 때문에, 시간을 줄이기 위해 사용할 cpu 프로세서 개수를 설정해주는 파라미터
print(result_boston)
print(-result_boston)
print(np.mean(result_boston))
print(-np.mean(result_boston))[-19.8971664 -23.5349172 -51.40872605 -31.38321557]
[19.8971664 23.5349172 51.40872605 31.38321557]
-31.556006304145065
31.556006304145065# 분류
result_iris = cross_val_score(DecisionTreeClassifier(max_depth=3, random_state=0),
X=X_iris,
y=y_iris,
scoring="accuracy",
cv=4,
n_jobs=-1)
result_iris print(result_iris)
print(np.mean(result_iris))[0.97368421 0.94736842 0.94594595 0.97297297]
0.9599928876244666cv 값은 모델 자체가 상속 받는 클래스가 다르기 때문에 모델을 돌리면 KFold를 사용해야하는지 StratifiedKFold를 사용해야하는지 자체적으로 판단해준다.
# 여러 평가지표를 확인
result = cross_validate(DecisionTreeRegressor(random_state=0, max_depth=3),
X=X_boston,
y=y_boston,
scoring=['r2', 'neg_mean_squared_error'],
cv=4,
n_jobs=-1
)
result{'fit_time': array([0.01562357, 0. , 0. , 0. ]),
'score_time': array([0. , 0.01562357, 0. , 0. ]),
'test_r2': array([ 0.3224128 , 0.76128228, 0.4275699 , -0.08225262]),
'test_neg_mean_squared_error': array([-19.8971664 , -23.5349172 , -51.40872605, -31.38321557])}result.keys()dict_keys(['fit_time', 'score_time', 'test_r2', 'test_neg_mean_squared_error'])fit_time : 모델 돌릴때 시간
score_time : 검증할 때 시간
result['test_neg_mean_squared_error']
-result['test_neg_mean_squared_error'][-19.8971664 -23.5349172 -51.40872605 -31.38321557]
[19.8971664 23.5349172 51.40872605 31.38321557]