교차검증
- 과적합 : 모델이 학습 데이터에만 과도하게 최적화된 현상 그로 인해서 일반회된 데이터에서 예측 성능이 과하게 떨어지는 현상
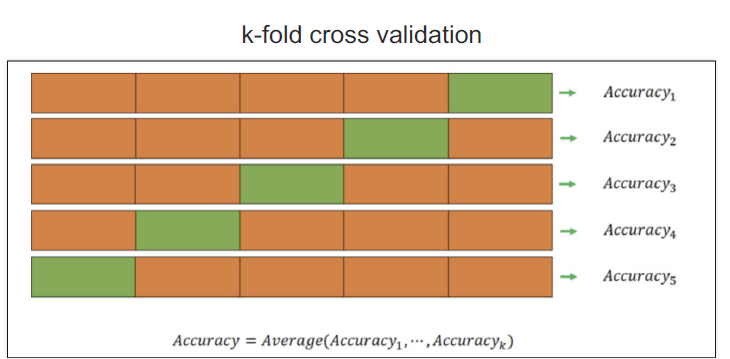
simple example
import numpy as np
from sklearn.model_selection import KFold
X = np.array([
[1,2], [3,4], [1,2], [3,4]
])
y = np.array([1,2,3,4])
kf = KFold(n_splits=2)
print(kf.get_n_splits(X))
print(kf)
for train_idx, test_idx in kf.split(X):
print('---idx')
print(train_idx, test_idx)
print('---train data')
print(X[train_idx])
print('---validation data')
print(X[test_idx])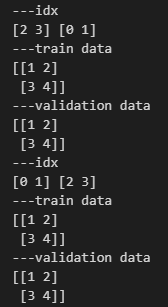
다시 와인 데이터 확인하기
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state= 13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print('Train ACC : ', accuracy_score(y_train, y_pred_tr))
print('Test ACC : ', accuracy_score(y_test ,y_pred_test))
위의 데이터를 통해서 교차 검증 시작 KFold
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)KFold는 index를 반환한다.
for train_idx, test_idx in kfold.split(X):
print(len(train_idx), len(test_idx))
5197 1300
5197 1300
5198 1299
5198 1299
5198 1299
각각의 fold에 대한 학습 후 acc
cv_accuracy = []
for train_idx, test_idx in kfold.split(X):
X_train = X.iloc[train_idx]
X_test = X.iloc[test_idx]
y_train = y.iloc[train_idx]
y_test = y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))
cv_accuracy
[0.6007692307692307,
0.6884615384615385,
0.7090069284064665,
0.7628945342571208,
0.7867590454195535]
StratifiedKFold
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_accuracy = []
for train_idx, test_idx in skfold.split(X, y):
X_train = X.iloc[train_idx]
X_test = X.iloc[test_idx]
y_train = y.iloc[train_idx]
y_test = y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_accuracy.append(accuracy_score(y_test, pred))for 구문 말고도 cross_val_score 사용가능하다.
하지만 데이터 처리할 때 원초적인 원리를 사용하여 데이터 처리하는 순간이 올 때도 있다.
코드가 생각보다 복잡해져서 이를 간단하게, 간편히 사용하기 위해서 cross_val_score 사용한다
cross_val_score
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X,y, scoring=None, cv=skfold)array([0.55230769, 0.68846154, 0.71439569, 0.73210162, 0.75673595])
depth가 높다고 무조건 acc가 좋아지는 것은 아니다.
max_depth = 5 로 변경
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=5, random_state=13)
cross_val_score(wine_tree_cv, X,y, scoring=None, cv=skfold)array([0.50076923, 0.62615385, 0.69745958, 0.7582756 , 0.74903772])
train score와 같이 보고 싶다면
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, scoring=None, cv=skfold, return_train_score=True)
하이퍼파라미터 튜닝
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
params = {'max_depth' : [2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
gridsearch.fit(X, y)
import pprint
pp = pprint.PrettyPrinter(indent=4)
pp.pprint(gridsearch.cv_results_)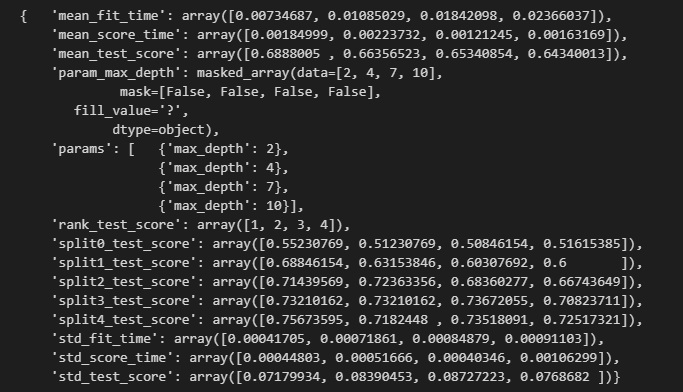
pipeline을 적용한 모델에 gridsearch를 적용하고 싶으면
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [
('scaler', StandardScaler()),
('clf', DecisionTreeClassifier())]
pipe = Pipeline(estimators)
param_grid = [{'clf__max_depth' : [2,4,7,10]}]
GridSearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
GridSearch.fit(X,y)