앙상블 개요
-
앙상블 학습을 통한 분류 : 여러 개의 분류기를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법
-
다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측 값을 얻는 것
-
현재 정형데이터를 대상으로 하는 분류기에서는 앙상블 기법이 뛰어난 성과를 보여주고 있음.
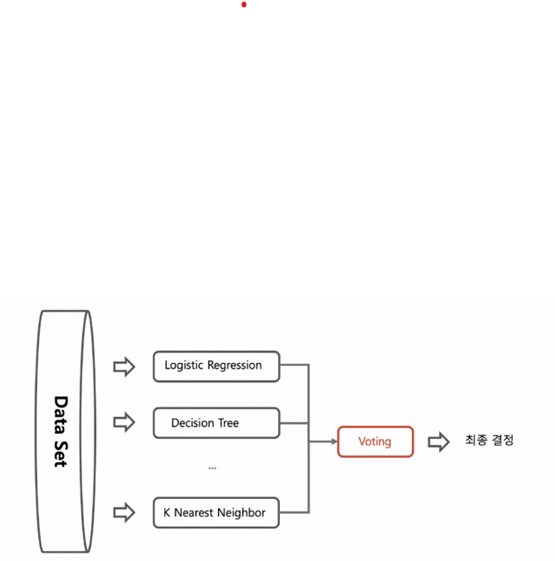
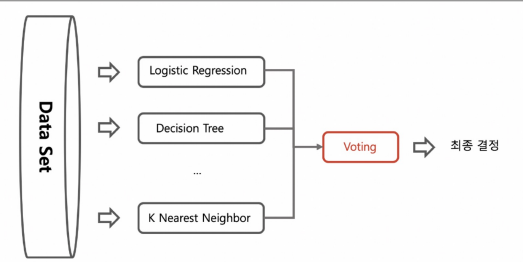
Voting 기법
- 전체 data set 중에서 여러 알고리즘을 돌려서 최종 결정하는 방법
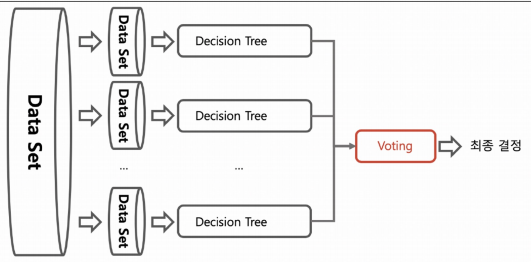
Bagging
-
동일한 알고리즘(주로 decision tree)에서 data set을 랜덤하게 샘플링한다.
-
bagging의 경우 데이터 중복을 허용해서 샘플링하고 그 각각의 데이터에 같은 알고리즘을 적용해서 결과를 투표로 결정
-
각각의 분류기에 데이터를 각각 샘플링해서 추출하는 방식을 부트스트래핑(bootstrapping) 분할 방식이라고 한다.
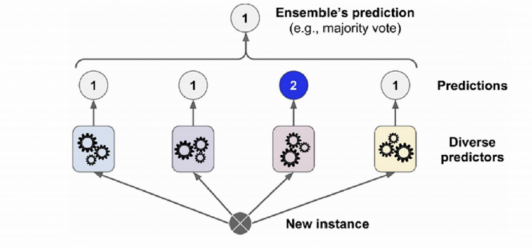
- 최종 결정에서 하드보팅 -> 다수결의 원칙과 비슷한 방법
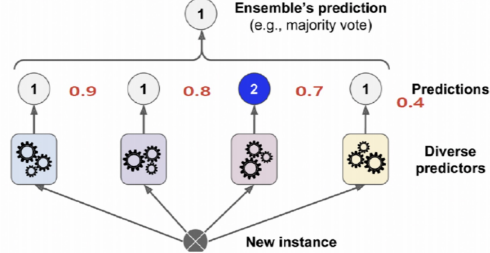
- 최종 결정에서 소프트보팅
-> 1: 0.9, 0.8, 0.4 확률의 평균 0.7
-> 2: 0.7
1과 2의 확률이 동일하면 다수결 원칙으로 따라간다.
만약 2의 확률이 더 높다면 2를 결정한다.
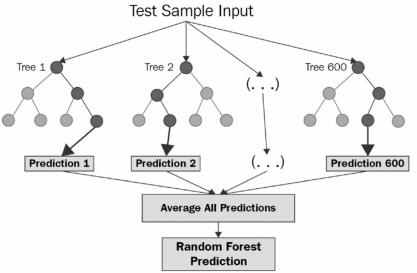
랜덤포레스트 Random Forest
-
Decision tree 여러 개를 사용해서 투표를 하는 방식이다.
-
앙상블 방법 중에서 비교적으로 속도가 빠르며 다양한 영역에서 높은 성능을 보여주고 있다.
이미지, 영상, 소리는 deep learning 이 훨씬 성능이 좋다.
정형데이터(table data, excel data, record data) machine learning 이 훨씬 성능이 좋다.
- 랜덤포레스트는 결정 나무를 기본으로 한다.