러프하게 흐름을 기록하였다.
결과는 새로운 포스팅으로 정리할 예정이다.
EDA 결과
앞서 살펴본 데이터셋의 주요한 특징은 아래와 같다.
- 클래스별 데이터의 갯수가 적고 불균형하다.
- 이미지별 size의 편차가 있다.
해당 특징을 고려하여 baseline model을 작성하였다.
실험 설정
우선 클래스별 데이터의 갯수가 많지 않기 때문에 성능평가를 train-validation-test로 나누는 것이 아닌, k-fold cross validation기법을 사용하기로 한댜.
또한, 클래스별 데이터수의 편차가 크기 때문에 stratified K-fold 방법을 사용하여 클래스별 데이터비율을 유지하면서 train set과 validation set을 나누었다.
이미지는 학습 속도를 고려하여 그레이스케일 변환 후 300x300으로 리스케일 하였다.
baseline model
ResNet-101을 baseline model로 사용하였다.
lr : 0.00005
batch size : 16
Adam optimizer
ReLu actvation fn
Weights initialization : Kaiming
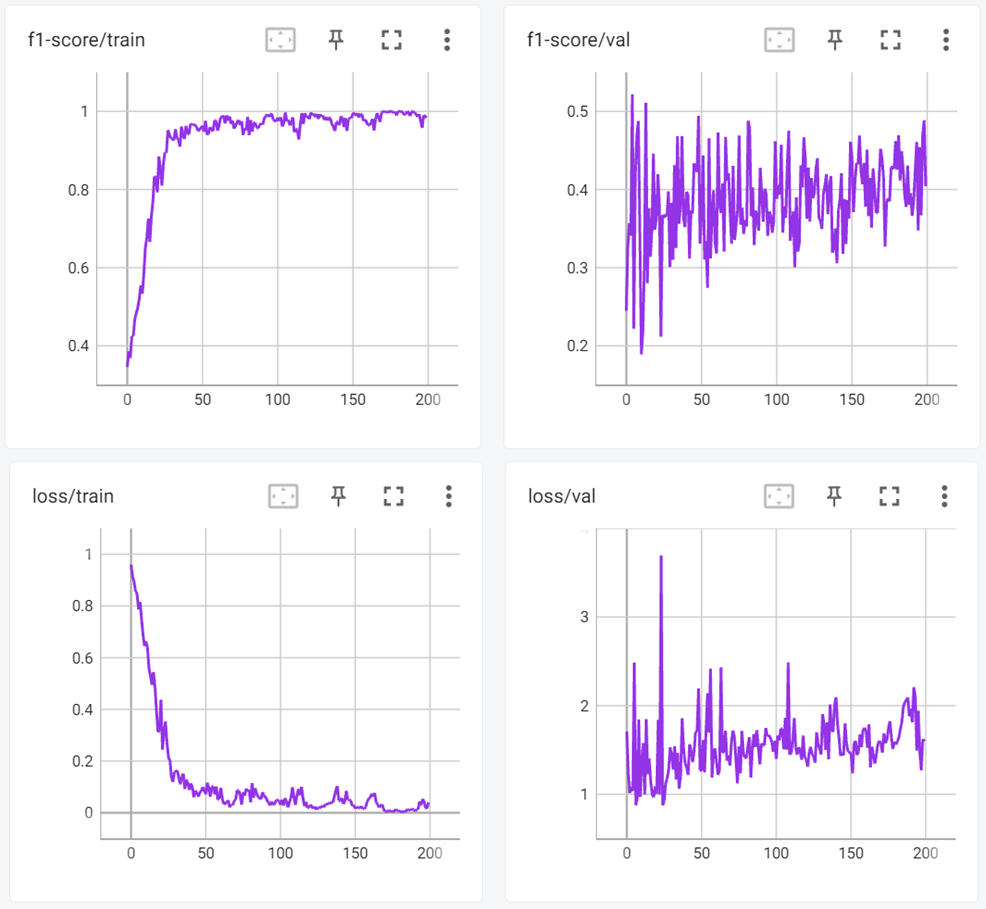
f1-score와 loss를 성능지표로 확인하였고, validation loss가 발산함을 통해 overfitting 되고 있음을 추론하였다.
data augmentaion
데이터의 과적합을 막기 위해 data augmentation을 적용하였다.
RandomHorizontalFlip 50%, RandomRotation(30), 데이터 정규화를 진행하였다.
그 후 learning rate를 1e-4~5e-5까지 변화시키고, batchsize를 2~32사이의 값으로 학습시켜 보았다.
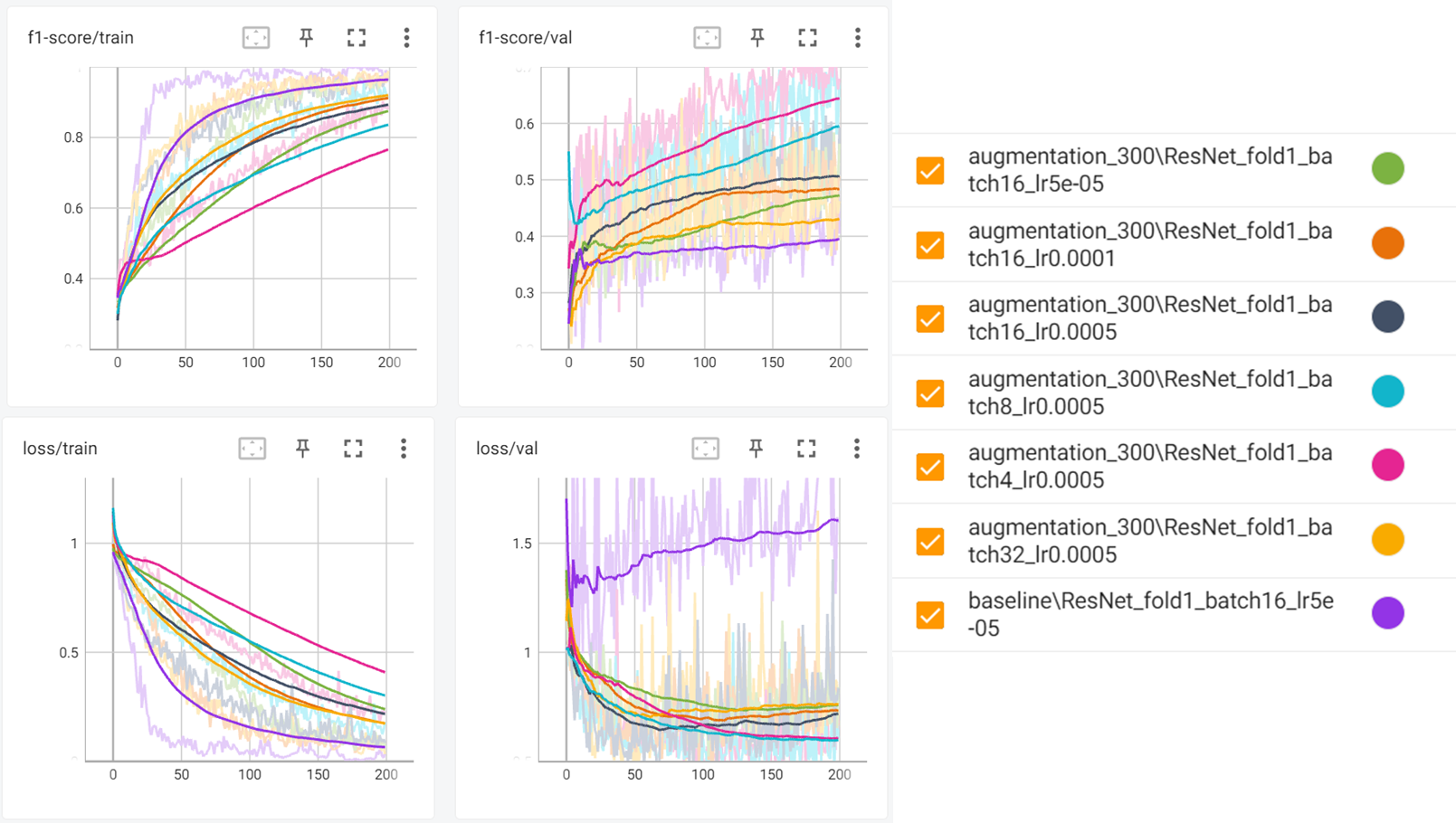
data augmentation을 통해 overfitting이 개선되는 모습을 보였다. 또 batch size가 작아질 수록 일반화 성능이 좋아짐을 확인하였다.
Compare Weights initialization
Xavier vs Kaiming
같은 learning rate 5e-4, batch size 4의 세팅으로 했을 때 가중치 초기화 방식에 따른 성능변화를 보기 위해 실험을 진행하였다.
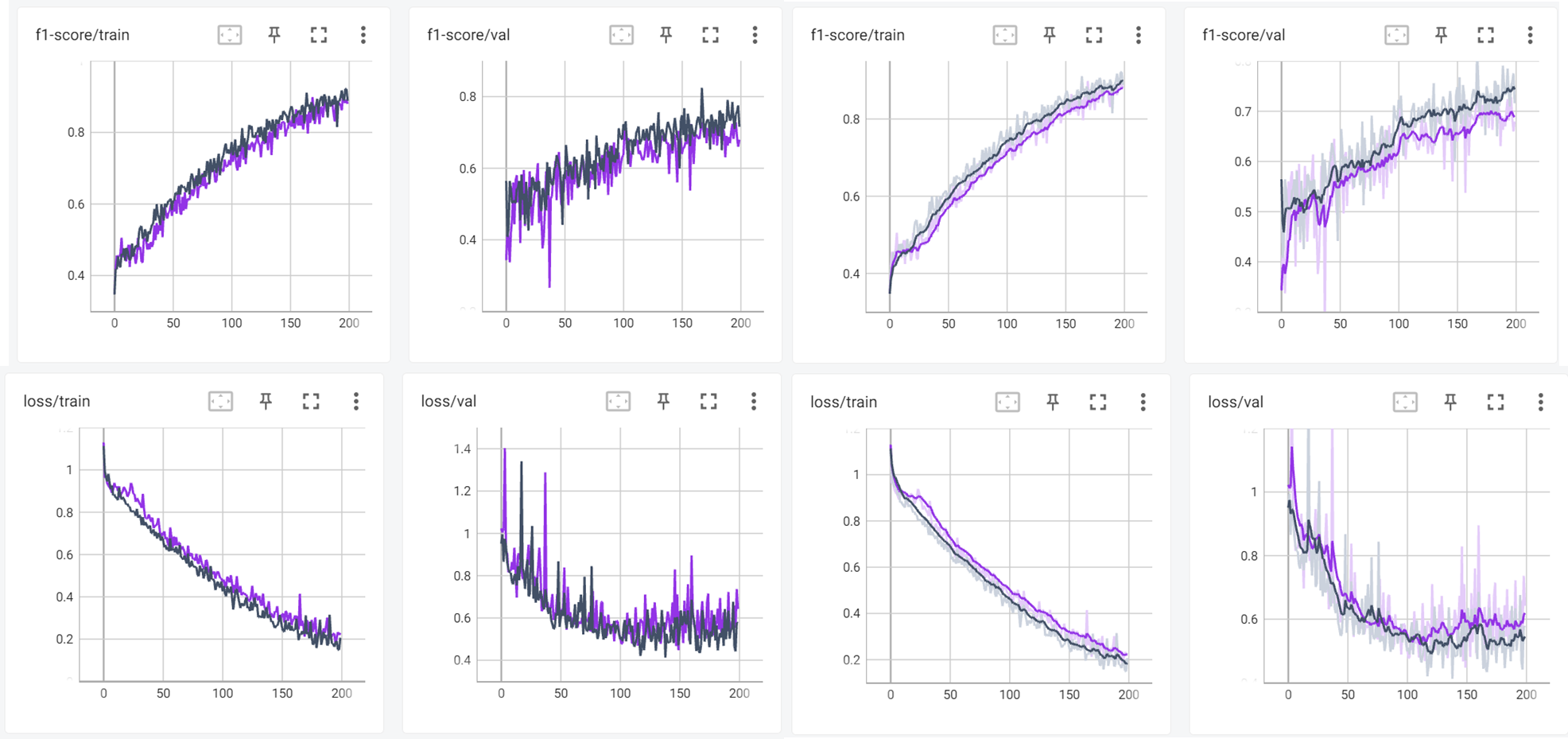
Xavier 초기화(남색)이 좀 더 성능상 우세한 것으로 확인되었다.
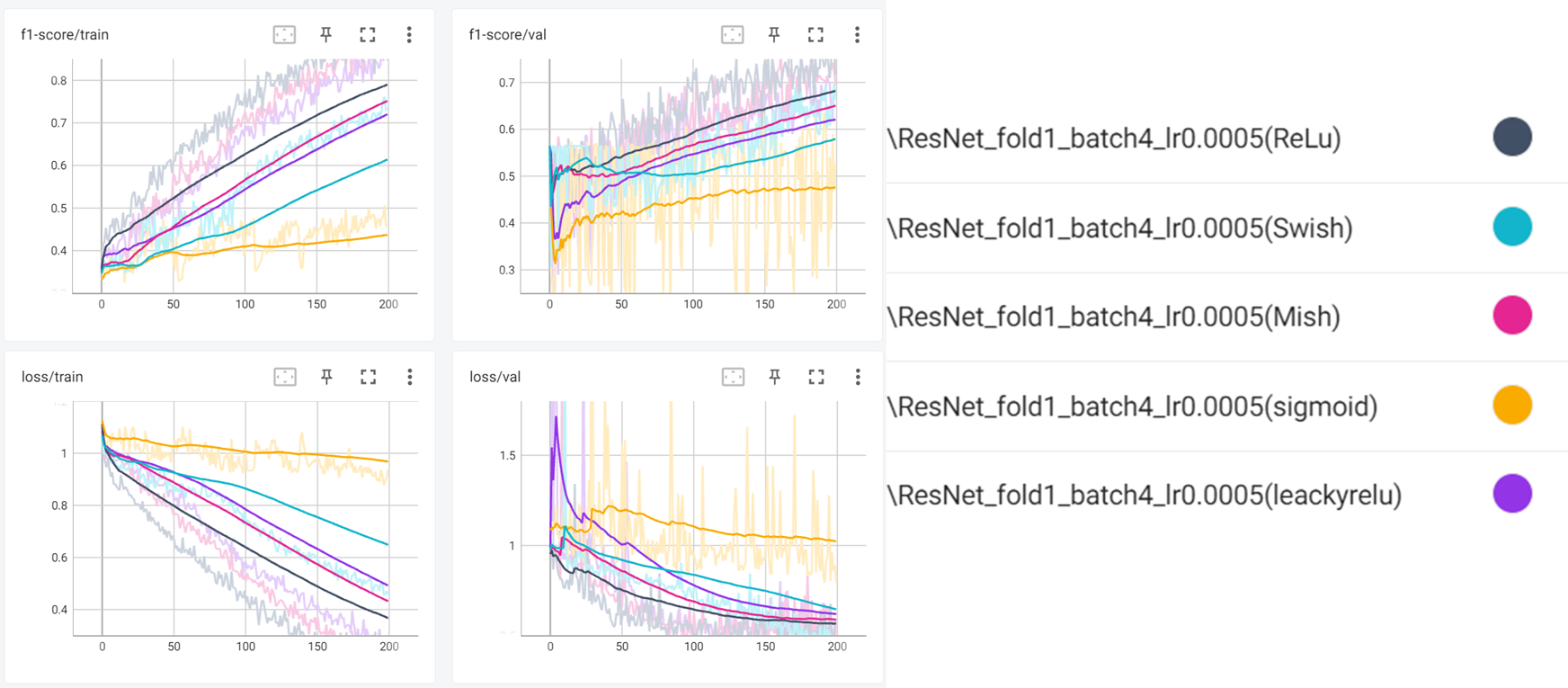
Compare activation function
sigmoid vs relu vs Leaky relu vs swish vs Mish
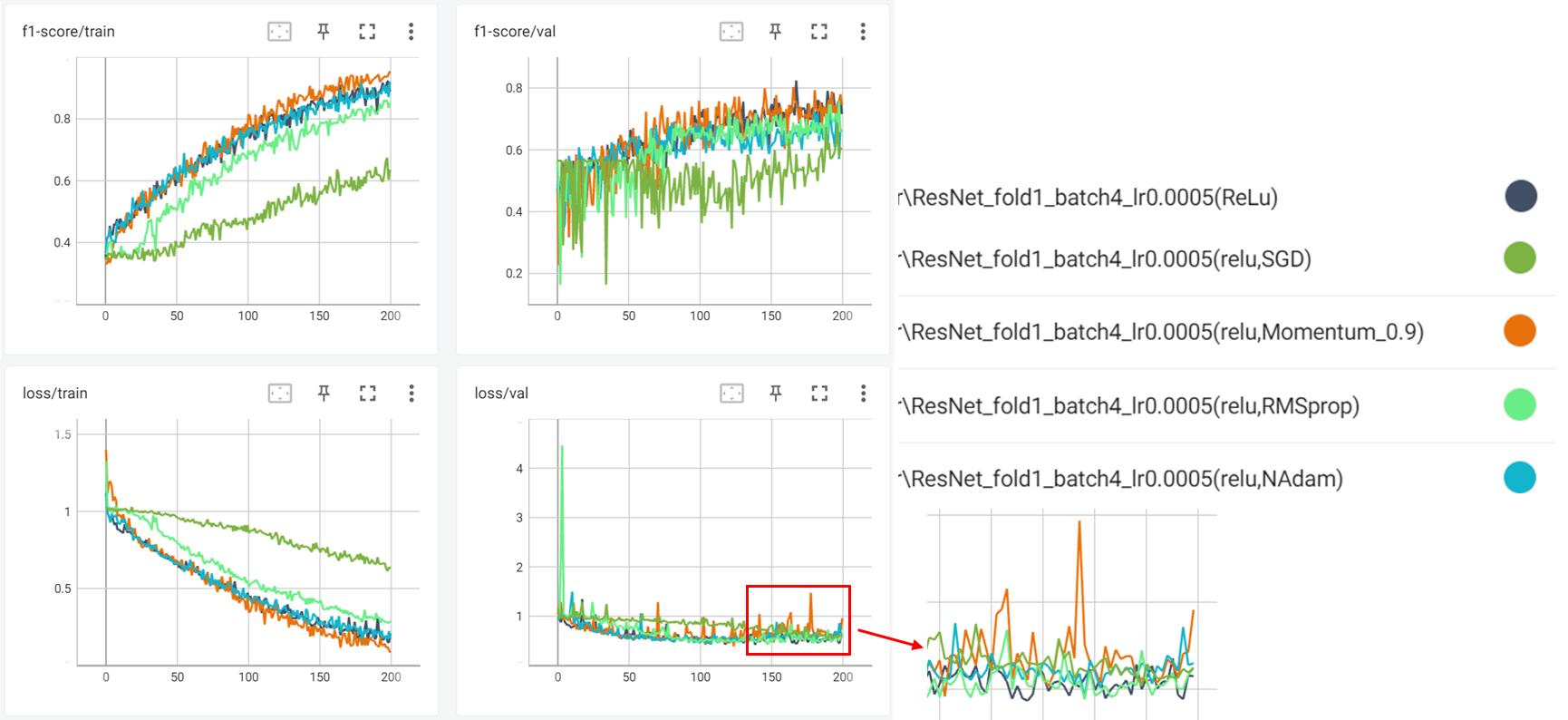
Optimizer
SGD vs Momentum vs RMSprop vs Adam vs Nadam
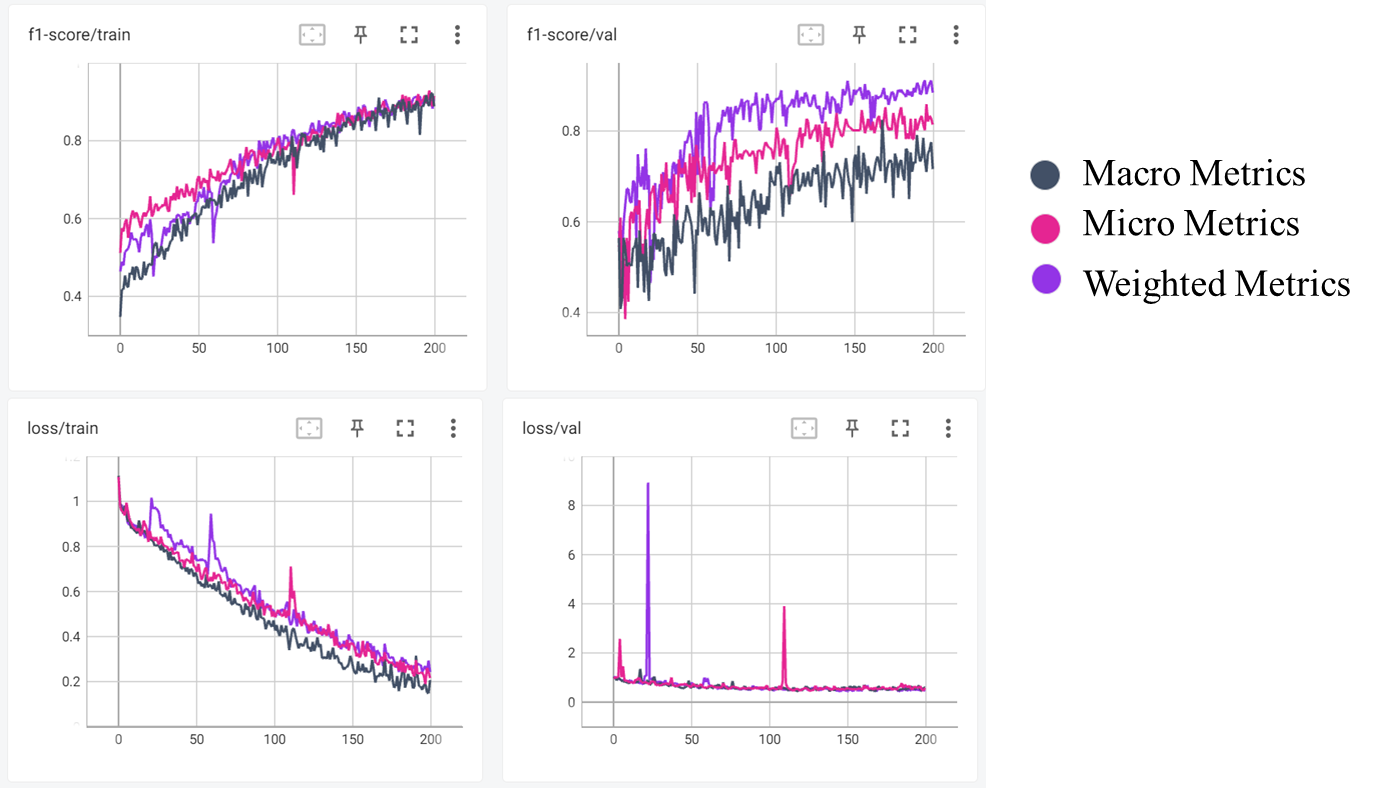
Metrics - Micro vs Macro vs Weighted
Micro
모든 클래스의 예측을 하나의 클래스처럼 다루어 전체 TP(True Positive), FP(False Positive), FN(False Negative)를 합산하여 계산하는 방법
- 특징: 모든 클래스의 예측 결과를 합산하여 계산한다.
- 장점: 클래스 불균형이 있어도 각 샘플이 동일하게 다뤄진다.
- 단점: 샘플 수가 많은 클래스의 성능이 지배적일 수 있다.
Macro
각 클래스의 성능을 계산한 후, 단순 평균을 내는 방법
- 특징: 각 클래스의 성능을 동일하게 고려한다.
- 장점: 각 클래스의 성능을 동일하게 중요시한다.
- 단점: 클래스 불균형이 있을 때, 샘플 수가 적은 클래스의 성능이 과대평가될 수 있다.
Weighted
각 클래스의 성능을 해당 클래스의 샘플 수로 가중평균하는 방법
- 특징: 클래스 불균형이 있는 경우, 샘플 수가 많은 클래스의 성능에 더 많은 비중을 둔다.
- 장점: 클래스 불균형이 있는 데이터셋에서 실제 성능을 더 잘 반영한다.
- 단점: 샘플 수가 적은 클래스의 성능이 상대적으로 덜 중요하게 다뤄질 수 있다.
Summary
- Micro: 전체 데이터를 하나의 클래스처럼 다루어 계산
- Macro: 각 클래스의 성능을 동일하게 고려하여 단순 평균
- Weighted: 각 클래스의 성능을 샘플 수로 가중평균
Apply
Why?
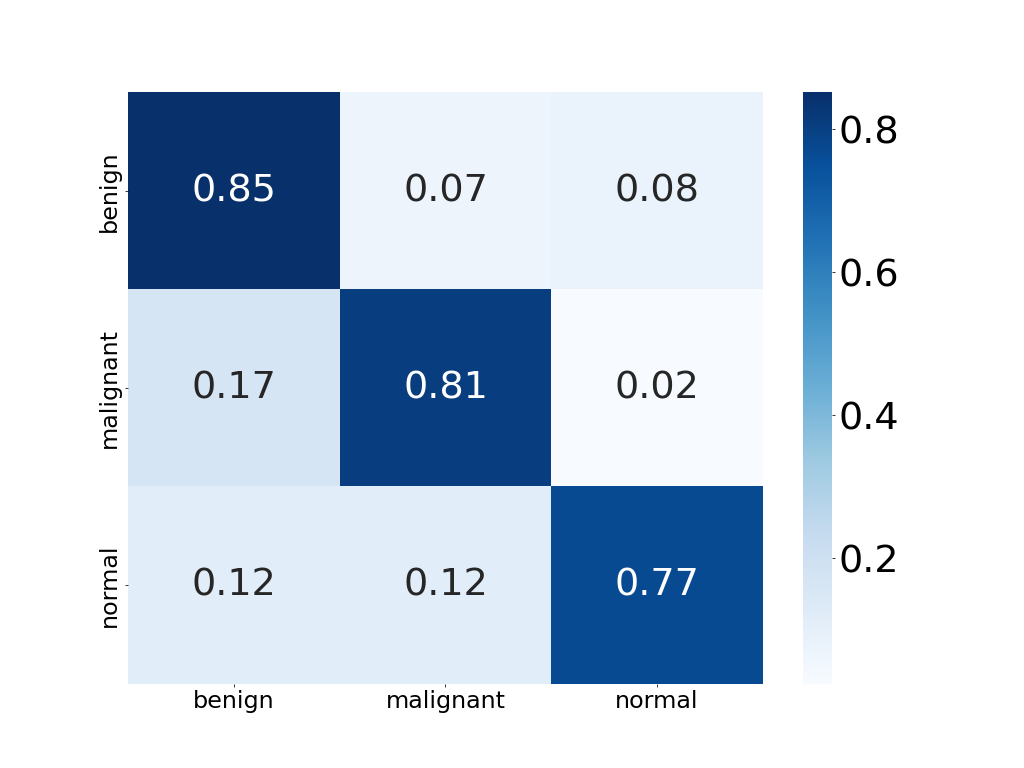
클래스의 갯수가 많은 benign클래스에 대한 성능이 상대적으로 높음. 데이터가 불균형하기 때문에 클래스의 샘플 수로 가중평균을 구하는 Weighted방법이 제일 높은 성능을 보여준다. 또한, Weighted 방법이 클래스 불균형이 있는 데이터셋에서 성능을 잘 반영하기 때문에 앞으로 성능 매트릭의 표현은 Weighted 방식으로 진행하였다.
Apply learning rate scheduler
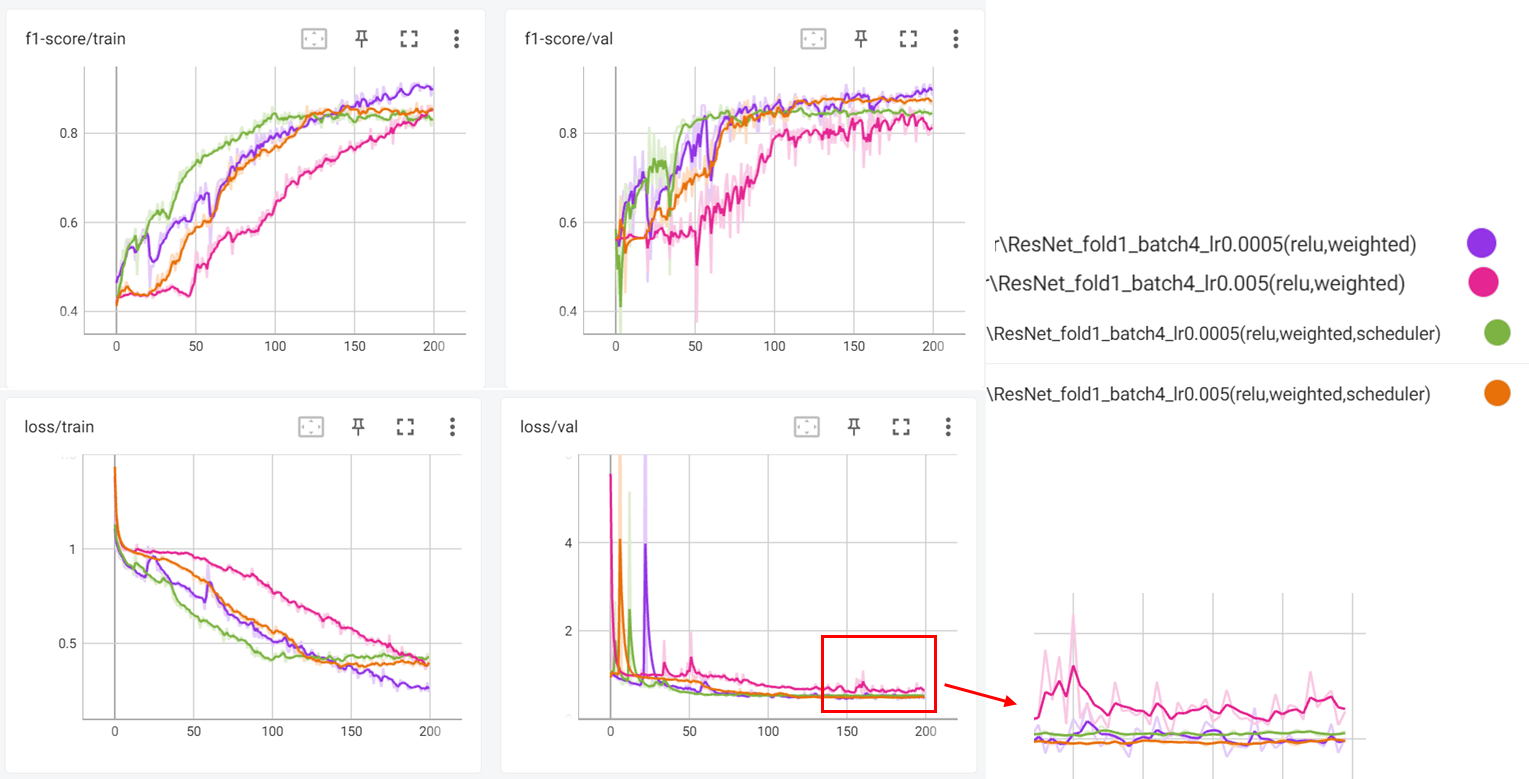
Compare Loss
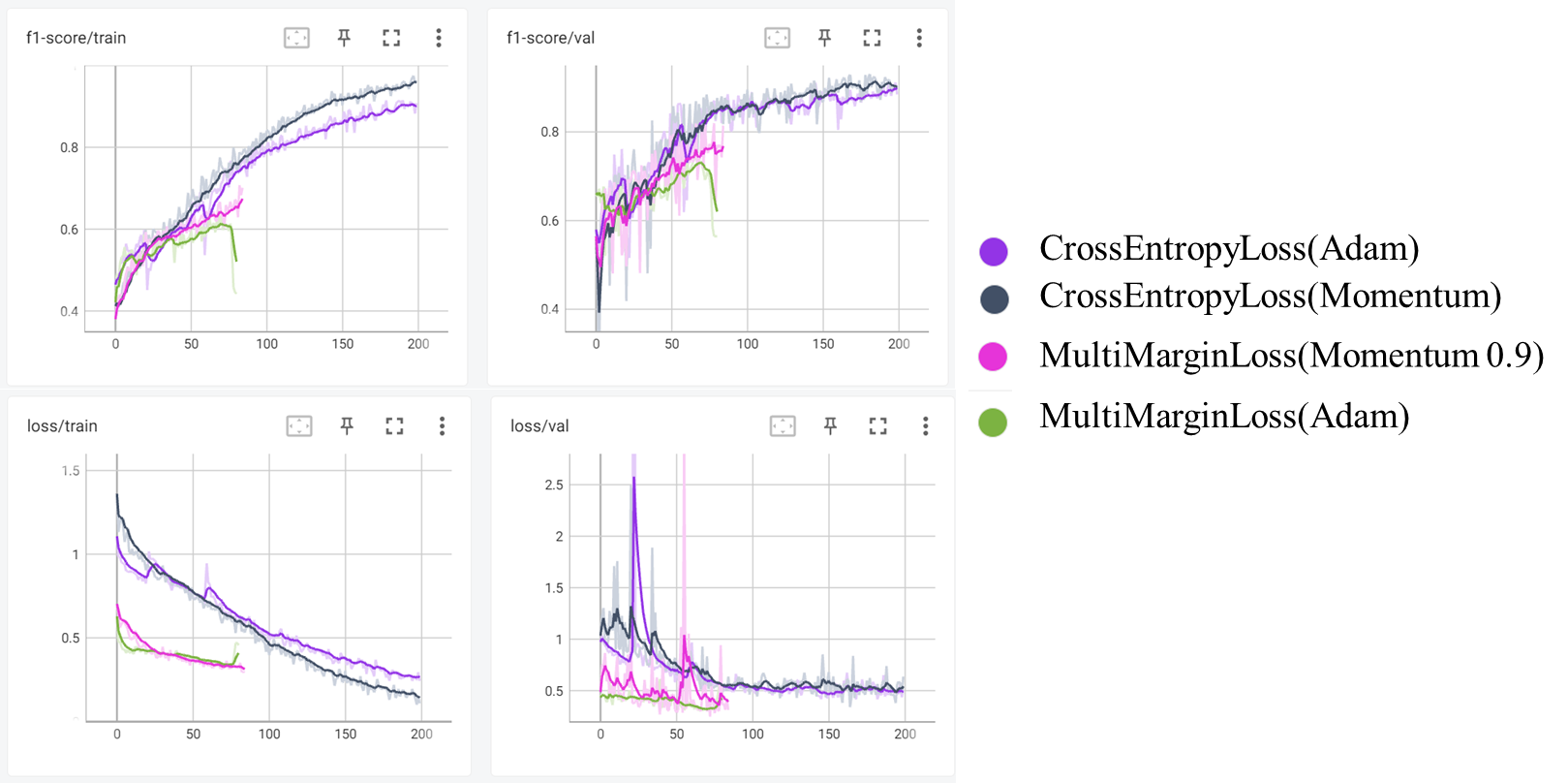
CrossEntropyLoss vs MultiMarginLoss