Abstract
LMM(Large multimodal model)은 최근 시각 지시 튜닝으로 인해 굉장한 발전이 있었다. 이번 논문에서는 LLaVA구조에서의 LLM 디자인을 선택하기 위한 시스템적인 연구를 보인다. fc layers가 강력하고 효율적임을 보인다. LLaVA의 간단한 수정과 CLIP-ViT-L-336px에 대한 그리고 학문 데이터를 프롬프트 포맷 세팅은 11개의 벤치마크에서 소타를 달성하게 한다. 최종적인 13B 학습 포인트는 1.2M 수량의 공공 데이터를 사용한다. 그리고 8개의 A100에서 하룻동안 전체 학습이 종료된다. 게다가 LMMs에서의 공공연한 문제를 고해상화, compositional 능력, 거짓말 등을 다룬다.
Instroduction
시각 기반 대화형 AI 개발을 위한 LMM 연구가 활발하며, LLaVA와 MiniGPT-4등이 인상적인 결과를 보였다. 그러나 기존 방법은 접근 방식이나 학습 데이터에 따라 장단점이 명확했다. 예를 들어, LLaVA는 실제 대화형 시각 추론(task)에 강점을 보이며 후속 연구를 능가했지만, 짧은 답변(single-word)을 요구하는 학문적 VQA 벤치마크에서는 열세였다. 반면 InstructBLIP은 전통적인 VQA 데이터에 더 높은 성능을 보인다. 이러한 성능 격차의 원인은 모델 구조나 학습 데이터 규모의 차이로 추정되었다. 본 연구에서는 LLaVA의 간단한 구조를 기반으로 input, model, data 3가지 관점으로 접근한다. (1) MLP 커넥터로 확장한다. InstructBLIP이나 Qwen-VL 의 경우 그들의 특별한 시각적 리셈플러가 있고 학습하지만 LLaVA는 하나의 fc layer만을 학습시켰었다. 이에 MLP cross modal connector를 추가한다. (2) 과제 특화 VQA 데이터를 추가하는 두 가지 핵심 개선을 제안한다. 그리고 Qwen-VL과 달리 내부 데이터 없이 공공 데이터만을 사용한다. 이를 통해 막대한 양의 데이터나 복잡한 리샘플러 없이도 기존 방법들을 능가하는 결과를 얻었음을 보인다.
다음으로 LMM의 공공연한 문제를 탐구한다. 높은 해상도의 이미지를 조정하여 인풋으로 받아들인다. 이미지를 단순하게 쪼개고 효울적으로 보관한다. 높은 해상도에서는 성능 개선과 더불어 할루시네이션도 줄일 수 있다. 두 번째로 LLM의 합성 능력을 일반화할 수 있다. 예를 들어, 길고 짧은 형식의 추론을 같이 학습시키면 모델의 글 작성 능력을 키울 수 있다. Data efficiency) LLaVA의 학습 데이터 양을 75%까지 낮춰도 모델의 성능의 타격이 없는 것을 확인함과 동시에 정교한 데이터셋 압축 방식이 더욱 효과적임을 보인다. Data Scaling) 모델의 성능을 향상시키기 위해서는 데이터의 세분화 수준(즉, 얼마나 정밀하거나 상세한 데이터를 사용하는지)을 모델의 능력과 잘 맞춰서 조정하는 것이 중요하며, 그렇게 하면 hallucination 같은 부작용 없이 성능을 개선할 수 있다는 실증적인 증거를 제시한다.
전체적으로 LLM의 시스템적인 학습 방식에 대해 연구를 진행한다. 그리고 멀티테스크에 대한 균형적이고 효율적인 방식을 제시한다. 베이스라인에서 발전시킨 LLaVA 1.5를 제시하며 공공 데이터만을 사용하고도 11개에서 SOTA를 기록한다.
Related Work
시각 인스트럭션 튜닝(Visual Instruction Tuning) 분야에서 LLaVA는 최초로 COCO 캡션 및 바운딩 박스 데이터를 GPT-4 기반의 텍스트 생성기로 확장하여, 대화형 질의응답(conversational QA), 상세 묘사(detailed description), 복잡한 추론(complex reasoning) 등 다양한 유형의 멀티모달 인스트럭션 데이터를 구축한 바 있다. LLaVA는 복잡한 구조 없이 단순한 비전-언어 연결기(vision-language connector)만을 사용한 대표적인 아키텍처이며, Qformer와 같은 비주얼 리샘플러 없이도 기본 성능을 달성했다는 점에서 구조적 간결성과 효율성 측면에서 주목을 받았다.
이후 InstructBLIP은 OK-VQA, TextVQA, OCR-VQA 등 학문 중심의 VQA 데이터셋을 통합하여 모델의 시각적 이해 능력을 강화했으며, Qwen-VL과 같은 최신 연구들은 수억~수십억 규모의 대규모 이미지-텍스트 페어를 활용한 사전 학습 전략을 도입하여 성능을 극대화하고 있다. 그러나 이처럼 다양한 VQA 데이터를 무분별하게 통합할 경우, 모델이 자연스러운 대화보다는 정형화된 질문-응답 패턴에 과적합(overfitting) 되어 일상적인 멀티모달 상호작용 능력이 저하될 수 있음을 지적한다. 이에 따라, 기존 VQA 데이터를 LLaVA 파이프라인을 활용하여 대화형 스타일로 재가공(conversational-style reformatting)하는 접근이 제안되었고, 이는 성능 향상에 효과적이지만 데이터 스케일링 측면에서는 추가적인 복잡성을 초래하게 된다.
한편, 자연어 처리(NLP) 분야에서는 FLAN 시리즈가 보여주듯, 대규모의 학문적 인스트럭션 데이터 추가가 모델의 일반화 성능 향상에 기여함이 입증되었다. 이를 고려하여 본 논문에서는, 복잡한 아키텍처 설계나 대규모 사전 학습에 의존하지 않고도, 단순한 모델 구조와 정교한 프롬프트 설계만으로도 시각 인스트럭션 튜닝 성능을 효과적으로 향상시킬 수 있음을 실증적으로 제시한다.
Approach
Preliminaries

LLaVA-1.5의 기본 설계는 시각 백본(encoder) + LLM + 크로스모달 커넥터로 이루어져 있다. 시각 백본으로는 CLIP-ViT-L-336px를 사용하여 224px 대비 더 높은 해상도의 입력을 처리한다. 기존 LLaVA에서는 커넥터를 단순 선형층으로 사용했으나, 본 연구에서는 이를 두 개의 레이어를 갖는 MLP로 변경하여 표현력을 높였다. 또한, LLaVA의 두 단계 학습 방식을 따른다: 첫 단계에서 image-text 데이터(약 60만 쌍)를 활용해 시각 피처와 언어 임베딩을 정렬하고, 두 번째 단계에서 시각 인스트럭션 튜닝을 수행한다.
Response Format Prompting
기존 LMM들은 VQA에서 짧은 답변과 긴 답변을 모두 다루기 어려운 문제가 있었다. 예를 들어 InstructBLIP은 “Q: {질문} A: {답변}” 형태의 애매한 포맷을 사용했는데, 이는 모델이 항상 짧은 답변에 치우치게 하는 경향이 있었다. 또 InstructBLIP은 LLM 대신 Qformer만 미세조정하여, 출력 길이 제어가 어려웠다. 이를 해결하기 위해 LLaVA-1.5에서는 명시적 응답 포맷 지시어를 도입한다. 예를 들어 단답형 답변을 유도할 때는 “한 단어나 구로 대답하시오.” 같은 프롬프트를 질문 끝에 추가한다. 이러한 방식으로 LLM을 학습하면, 모델이 지시어에 따라 답변 형식을 올바르게 조절할 수 있다. 실제 실험에서도 추가적인 포맷 프롬프트만으로 VQAv2를 학습할 경우 MME 벤치마크 성능이 502.8에서 1323.8으로 급상승했으며, 이는 InstructBLIP보다 111점 높은 수치였다.
Scaling the Data and Model
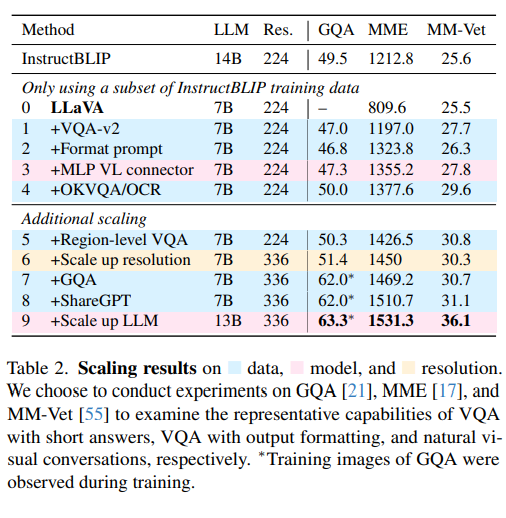
논문에서는 데이터 크기와 모델 규모를 단계적으로 늘려 성능을 분석했다. 먼저 학습 데이터에 OK-VQA, A-OKVQA, OCRVQA, TextVQA 같은 학문적 VQA 데이터를 추가했다. 이러한 데이터는 VQA뿐 아니라 OCR과 지역 인식(region-level perception) 능력을 향상시켰다. 추가로, GQA와 같은 추가 데이터셋과 ShareGPT 대화 로그를 포함시켰다. 모델 측면에서는 기본적으로 7B 버전의 Vicuna(LLM)를 사용하되, 이를 13B 버전으로 확장하였다. Table 2 실험 결과에 따르면, 데이터 확장 및 LLM 확장을 거칠수록 대부분의 벤치마크에서 성능이 꾸준히 증가하였다. 예를 들어 MM-Vet에서는 Vicuna-7B에서 31.1점을 기록했지만, Vicuna-13B에서는 36.1점으로 크게 향상되었다.
Scaling to Higher Resolutions
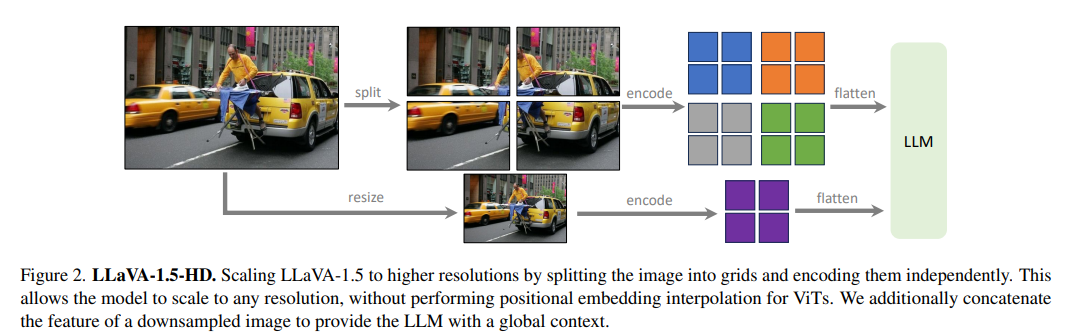
LLaVA-1.5는 입력 이미지를 더 높은 해상도로 처리하여 세부 정보를 살린다. 구체적으로 CLIP-ViT-L-336px 인코더를 사용하고, 후속 실험에서는 448×448 해상도를 도입하였다. 또한 224² 크기로 이미지를 패딩한 뒤 이를 global context로 연결하여, 모델이 전체 영상의 전역 정보를 활용하도록 하였다. 이런 고해상도 처리 기법을 적용한 결과, GQA·MME·MM-Vet 등 모든 검증 벤치마크에서 성능이 모두 향상되었다. 예를 들어 GQA에서는 62.9→63.8(+0.9), MME에서는 1425.8→1497.5(+71.7)으로 올랐다. 전반적으로, 입력 해상도를 높여 더 많은 시각 세부를 모델이 명확히 인식하게 한 것이 성능 향상의 주요 요인이다.
Empirical Evaluation
Benchmarks
LLaVA-1.5는 총 12개 벤치마크에서 평가되었다. 학문적 과제 지향 벤치마크로는 VQA-v2, GQA(보편적 짧은 답변 평가), VizWiz(시각 장애인용 질문), ScienceQA(과학 질문), TextVQA(이미지 속 문자 인식) 등이 사용되었다. 그 외, 시각 인스트럭션 튜닝을 위해 고안된 벤치마크로는 POPE(환각률 평가), MME-Perception(예/아니오 문제), MMBench(다지선다형 평가 강건성), MMBench-CN(중국어 번역), SEED-Bench(이미지/비디오 종합 QA), LLaVA-야외(LLaVA-Bench-in-the-Wild), MM-Vet(대화 정확도) 등이 포함되었다. 이들 벤치마크는 다양한 영역과 응답 형식을 망라하여 모델의 종합적 성능을 시험한다.
Results
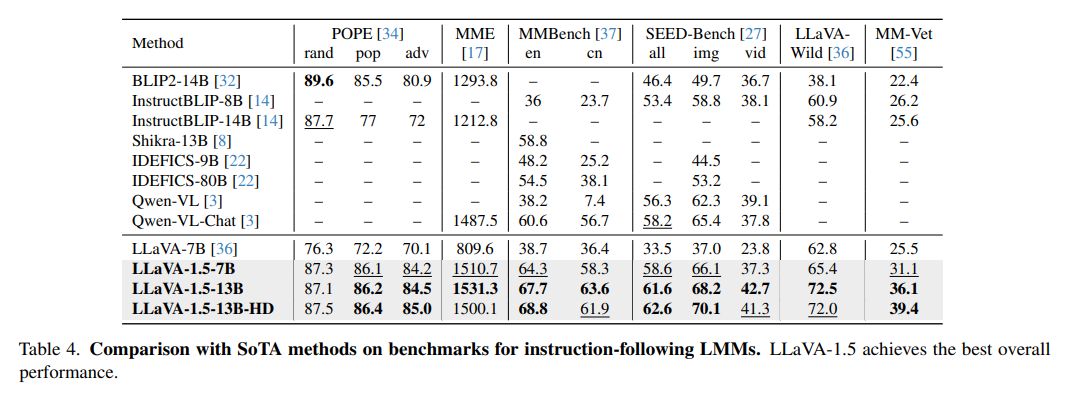
실험 결과, LLaVA-1.5는 12개 중 11개 벤치마크에서 최고 성능을 달성했다. 전반적으로 학습과 추론에 훨씬 적은 자원만 투입했음에도 종전 방법들보다 우수한 결과를 보였다. 예를 들어 MME 벤치마크에서 LLaVA-7B(원래 버전)는 809.6점을 기록했으나, 개선된 LLaVA-1.5(7B)는 1510.7점으로 두 배 가까운 성장을 보였다. Vicuna-13B 모델로 확장했을 때에는 MME 1531.3점, 기타 대화형 태스크에서도 두드러진 상승(예: MM-Vet 36.1점) 등을 기록하여 전반적인 성능 향상을 입증했다. 이처럼 간단한 구조 변화와 적은 학습 데이터로도 최첨단 LMM과 견줄 만한 성과를 얻었으며, 연구자들에게 재현 가능하고 현실성 높은 강력한 기준선을 제공한다.
Emerging Properties
훈련 과정에서 관찰된 특이 현상도 보고된다. 형식 명령어 일반화 측면에서, LLaVA-1.5는 제한된 형식 지시어만 학습했음에도 보편적인 지시어에 잘 대응했다. 예를 들어 VizWiz 벤치마크에서 “답할 수 없으면 ‘Unanswerable’로 출력”이라는 요구사항이 주어졌을 때, 본 연구의 응답 포맷 프롬프트는 올바르게 작동하여 정답률이 11.1%에서 67.8%로 급증하였다. 또한 JSON 형식과 같이 엄격한 출력 제약도 성공적으로 수행했다. 다국어 능력 면에서도 LLaVA-1.5는 흥미로운 결과를 보였다. 한국어나 중국어 데이터를 추가로 학습하지 않았음에도, ShareGPT 대화 데이터의 영향으로 중국어 질문에 대해 LLaVA-1.5-13B가 Qwen-VL-Chat(중국어 튜닝된 모델)을 7.3% 앞서 나갔다. 이는 LLaVA-1.5가 제한적 학습만으로도 새로운 언어 환경에 일반화될 수 있음을 시사한다.
Ablation on LLM Choices
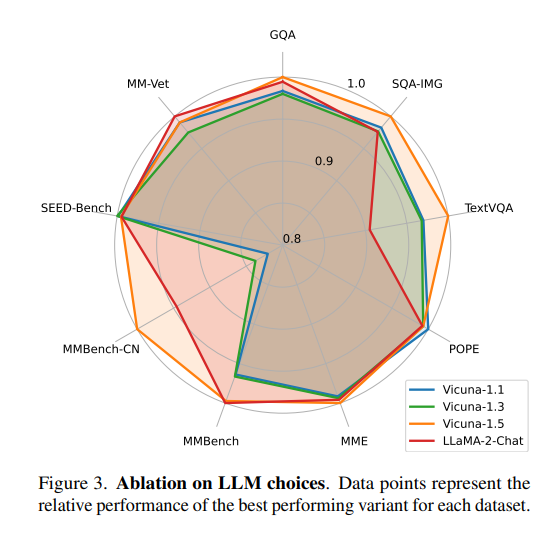
LLM의 크기와 종류에 따른 영향도 검토되었다. LLaVA-1.5는 Vicuna-7B와 Vicuna-13B 두 모델 모두 평가했는데, LLM 크기를 늘릴수록 대부분의 벤치마크 성능이 향상되었다. 예를 들어 MME에서 7B 모델의 정답률이 58.3%인 반면, 13B 모델은 63.6%를 기록했다. Vicuna-13B는 고해상도 처리가 결합된 변형(HD)에서도 뛰어난 성능을 보여, 모델 용량의 확장이 성능 향상에 유의미함을 확인했다. 이 결과는 LMM에서도 언어 모델 크기가 중요한 성능 요소임을 다시 한번 보여준다.
Open Problems in LMMs
Data Efficiency
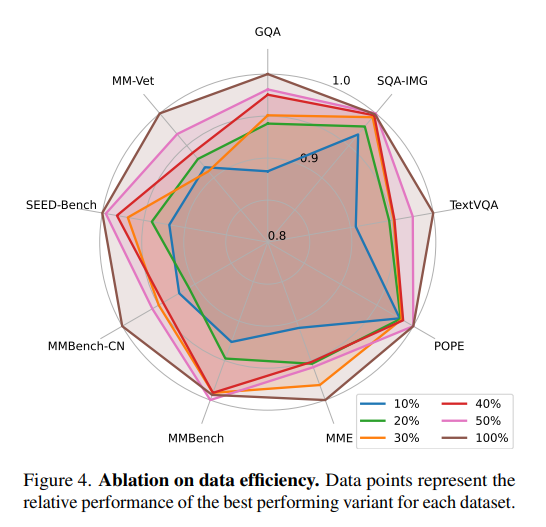
LLaVA-1.5는 기존 방법에 비해 매우 효율적으로 학습되었지만, 데이터 효율성 문제는 여전히 중요하다. 저자들은 훈련 데이터의 샘플 비율을 10%에서 50%까지 감소시키며 실험했다. 그 결과, 전체 데이터의 50%만 사용해도 모델은 98% 이상의 성능을 유지했다. 심지어 일부 과제(MMBench, ScienceQA, POPE)에서는 성능이 거의 감소하지 않았으며, 특정 경우에는 오히려 소폭 상승했다. 이 ‘Less-is-more’ 현상은 멀티모달 모델에도 적용됨을 보여주며, 소량의 데이터로도 최적 성능 근처에 도달할 수 있음을 시사한다. 즉, 데이터 규모를 줄이더라도 적절한 샘플링 전략을 통해 학습 효율을 크게 높일 여지가 있다.
Rethinking Hallucination in LMMs
LMM의 환각(hallucination) 문제는 통상적으로 학습 데이터의 오류 탓으로 돌려왔다. 그러나 LLaVA-1.5 실험에서는 입력 해상도와 환각 발생률 간의 흥미로운 관계가 관찰되었다. 예를 들어 LLaVA-Instruct의 이미지 설명 데이터에 약간의 오류가 있었음에도, 입력 해상도를 448²로 증가시킬 경우 환각 빈도가 현저히 감소했다. 이는 고해상도 입력이 모델의 사실 검증 능력을 높여, 훈련 데이터의 일부 오류를 보정할 수 있음을 의미한다. 반대로 입력 해상도가 낮아 중요한 세부를 인식하지 못하면, 모델은 부족한 정보를 추측하여 환각이 늘어날 수 있다. 따라서, 더 세밀한 주석(annotation)과 모델 처리 능력 간의 균형을 맞추는 것이 환각 문제 해결의 핵심임을 시사한다.
Compositional Capabilities
LLaVA-1.5는 합성(compositional) 능력에서도 유망한 결과를 보였다. 이는 독립적으로 학습한 여러 기능들이 결합된 새로운 과제에도 일정 수준 대응할 수 있음을 뜻한다. 예를 들어 ShareGPT 대화 데이터를 추가한 모델은 이전보다 더 길고 상세한 답변을 생성하며, 다국어 능력도 함께 향상되었다. 또한 학문적 VQA 데이터 추가는 모델의 시각적 그라운딩 능력을 높여, MM-Vet나 LLaVA-야외와 같은 대화형 평가에서 정답률 향상으로 이어졌다. 물론 여전히 특정 복합 태스크(예: 객체 속성 설명)에서는 한계를 보였고, 추가적인 연구가 필요하다. 그럼에도 불구하고 이러한 결과는 LMM이 서로 다른 능력을 조합하여 다중 과제를 해결할 수 있음을 암시하며, 모든 조합을 학습 데이터에 포함하지 않고도 활용 가능한 가능성을 보여준다.
Conclusion
본 논문은 LLaVA-1.5라는 간결하고 데이터 효율적인 LMM 베이스라인을 제안하였다. 간단한 구조 변경(MLP 연결기)과 추가 데이터(학문적 VQA, 대화 데이터, 고해상도 입력)만으로도, 방대한 사전학습 없이 최첨단 수준의 성능을 달성했다. 또한 고해상도 처리, 환각 저감, 합성 능력 등 LMM의 미해결 문제에 대해 실험적 고찰을 제공하여, 향후 연구 방향에 참고가 될 통찰을 제시했다. 다만, 고해상도 훈련에 따른 연산 비용 증가, 다중 이미지 이해 부재, 특정 분야에 제한적인 문제 해결 능력 등은 여전히 과제로 남아 있다. 이 연구에서 제시한 개선된 기준선과 관찰 결과는 오픈소스 LMM 연구의 기반이 되어, 향후 모델 개발 및 평가에 유용한 참고점이 될 것으로 기대된다.
