Abstract
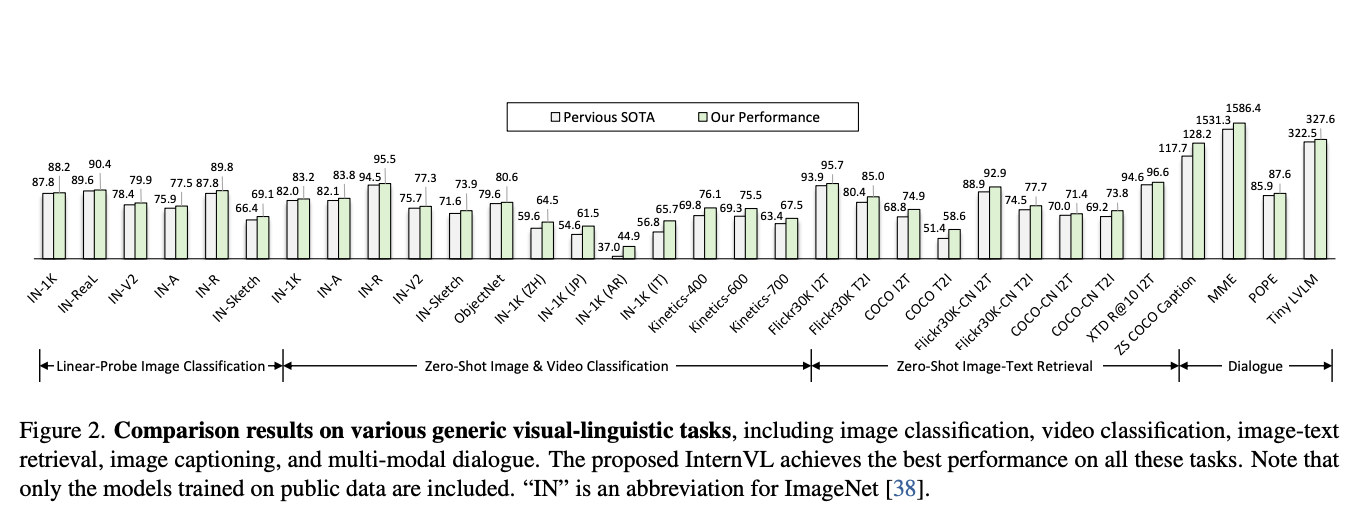
LLMs의 발전으로 인해 AGI에 다가서고 있다. 우리는 vision foundation model을 6B까지 키움과 LLM에 얼라인 시킨 InternVL을 제시한다. 해당 모델은 32개의 일반적인 비젼-언어 벤치마크에서 소타를 달성한다. 이는 강력한 시각 능력과 ViT-22B를 대체할 수 있다.
Introduction
LLM은 AGI 시대를 촉진시키고 있다. LLM을 이용하는 VLLM은 발전에 따라 시각과 언어의 정교한 상호작용이 가능해졌다. 그러나 LLM에 빠른 발전에 비해 비젼 및 비젼 언어 모델의 발전은 늦춰지고 있다. 비젼 모델을 언어 모델에 연결하기 위해 흔히 QFormer or linear와 같은 가벼운 "glue" 레이어를 사용한다. 이러한 연결은 제약이 생긴다. (1)파라미터의 스케일의 격차 : 1000B까지 모델은 커지나 비젼 모델은 여전히 1B에 그친다. (2)일관성 없는 표현 : 비젼 모델은 순수한 비젼 데이터로 학습되거나 BERT 모델과 얼라인되며 LLM에서의 랜덤성을 보인다. (3)불충분한 연결성 : 가벼운 연결과 랜덤 초기화로 인해 대게 크로스모달간 풍부한 정보를 놓치게 되며 이는 생성과 이해에 문제를 일으킨다.
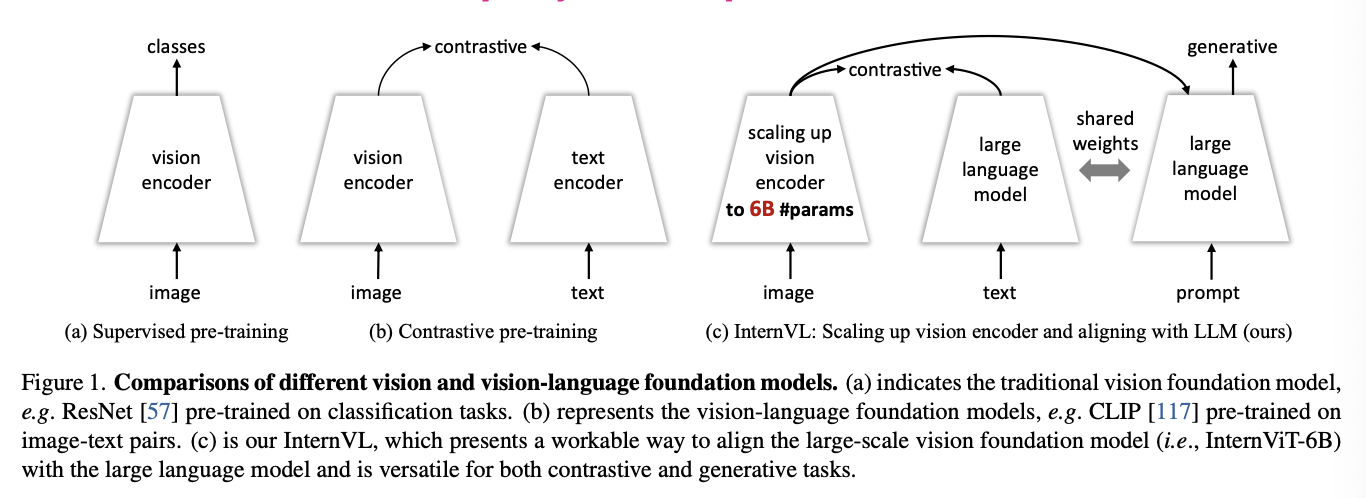
이러한 제약들은 비젼 모델과 언어 모델간 파라미터 크기와 표현에서 갭을 드러낸다. 갭을 매우기 위해 비젼 인코더를 키우도록 한다. 그러나 거대 모델 학습의 경우 인터넷에서 방대한 데이터를 필요로 한다. 중요한 이질성과 퀄리티 변동성은 학습과정에서 생각해야할 문제이다. 학습과정의 효율성을 키우기 위해 Contrastive learning의 생성 지도 학습을 고려한다. 해당 방식은 학습간 모델에게 추가적인 가이드를 주는 것을 목적으로 한다. 생성형 학습관 낮은 품질의 데이터 문제도 있다. 또한, 사용자의 지시를 효과적으로 표현하는 것과 비젼 인코더와 LLM에 대한 연결도 문제이다.
InernVL은 비젼 인코더의 크기를 키워 다양한 테스크에서 소타를 달성한다.
(1) 비젼과 언어 모델의 스케일 밸런스 : 비젼 모델을 6B까지 키우고 LLM의 연결하는 미들웨어를 8B까지 키운다. 이전 vision-only or dual tower와는 달리 contrastive&generative 테스크에서 유연한 결합을 보인다.
(2) 일관성있는 표현 : 비젼 인코더와 LLM의 연결에 대한 일관성을 지키기 위해 사전학습된 multilingual LLaMA를 이용하여 초기화를 진행한다.
(3) 점진적인 image-text 연결 : 다양한 소스에서 데이터를 이용해 점진적 연결 방식을 이용한다. 이 방식은 contrastive learning으로 시작하며 점진적으로 더 좋은 데이터로 생성 문제를 다룬다.
이러한 디자인은 몇가지 이점을 가져다 준다.
(1) 다용도 방식으로 비젼 모델 단독으로 사용할 수도 있고 미들웨어와 함께 비젼 언어로 모델로 사용할 수 있다.
(2) 큰 파라미터 거대 규모 데이터 그리고 학습 전략은 강력한 능력을 얻고 소타를 달성한다.
(3) LLM 친화적, LLM에 대한 적절한 얼라인을 통해 매끄럽게 통합되어진다.
Related Work - [ChatGPT 활용 요약]
해당 논문에서는 InternVL1 모델을 소개하기에 앞서, 관련된 선행연구들을 세 가지 큰 축으로 나누어 설명하고 있다. 각각은 Vision Foundation Models, Large Language Models, Vision Large Language Models(VLLMs)이다.
먼저 Vision Foundation Models에 대한 설명에서는 지난 10년간 컴퓨터 비전 분야에서 기초 모델들의 발전이 급속히 이루어졌음을 강조하고 있다. 대표적으로 AlexNet을 시작으로 다양한 CNN 기반 모델들이 등장하며 ImageNet 성능을 지속적으로 갱신해왔다. 특히 ResNet에서 도입된 residual connection은 깊은 신경망 학습 시 발생하는 vanishing gradient 문제를 효과적으로 해결하며, 이후 '크고 깊은 모델이 성능이 좋다'는 패러다임을 정립했다. 이 흐름은 최근 ViT(Vision Transformer)의 등장으로 확장되었는데, ViT는 기존 CNN 기반 구조와는 다른 transformer 기반 구조로 높은 표현력을 확보하였으며, 다양한 변형 모델들이 시각 작업에서 탁월한 성과를 보이고 있다. 그러나 이러한 모델들은 대부분 ImageNet이나 JFT처럼 시각 정보에만 기반한 데이터셋을 활용하거나, 이미지-텍스트 페어를 통해 BERT 계열 모델과 약한 정렬을 시도한 수준에 그치고 있다. 또한 현재 LLM과 연결되는 비전 모델들은 여전히 파라미터 수가 10억 정도로 제한되어 있어, VLLM 성능 향상에 한계를 보이고 있다는 점을 지적하고 있다.
다음으로 Large Language Models(LLMs)에 대한 설명에서는 GPT-3의 등장 이후 LLM이 자연어 처리에서 인간 수준의 능력을 보이기 시작했음을 강조한다. 특히 few-shot 및 zero-shot 학습 능력을 통해 다양한 작업에 일반화 가능성을 보여주었고, 이어서 등장한 ChatGPT와 GPT-4는 이러한 흐름을 더욱 가속화했다. 최근에는 LLaMA 시리즈, Vicuna, InternLM, MOSS, Qwen, Baichuan, Falcon 등 다양한 오픈소스 LLM들이 등장하여 연구 커뮤니티의 발전을 이끌고 있다. 그러나 실제 상호작용 환경에서는 자연어뿐만 아니라 시각 정보 역시 중요하기 때문에, 강력한 LLM을 시각 정보 처리까지 확장하는 것이 차세대 연구 방향이 될 것으로 전망하고 있다.
마지막으로 Vision Large Language Models(VLLMs)는 위 두 분야의 융합으로 등장한 최신 연구 트렌드다. Flamingo는 시각과 언어 정보를 동시에 프롬프트로 사용하여 few-shot 설정에서 뛰어난 성능을 보였으며, 이후 GPT-4, LLaVA, MiniGPT-4 등에서는 시각 지시어 튜닝을 통해 모델의 지시어 이해 능력을 향상시켰다. 또한 VisionLLM, KOSMOS-2, Qwen-VL 등은 시각적 정렬(visual grounding) 기능을 도입하여 영역 설명 및 위치 지정 등의 세부 작업에서도 성능을 높였다. 일부 연구들은 vision API를 LLM과 통합하여 비전 중심의 과제를 해결하려는 시도를 보이고 있고, PaLM-E나 EmbodiedGPT는 실세계 환경(embodied AI)에서의 활용 가능성도 모색하고 있다. 하지만 이처럼 VLLM이 빠르게 발전하고 있음에도 불구하고, 이들을 뒷받침해야 할 시각 또는 비전-언어 기초 모델들의 발전 속도는 그에 미치지 못하고 있다는 한계를 지적한다.
요약하자면, InternVL1 모델은 이러한 배경 위에서 VLLM의 발전을 저해하는 병목 현상을 해결하고자 등장한 모델로, 특히 시각-언어 정렬과 모델 규모 측면에서 기존 한계를 뛰어넘으려는 시도를 바탕으로 하고 있음을 이 장에서는 간접적으로 보여준다.
Proposed Method
Overall Architecture
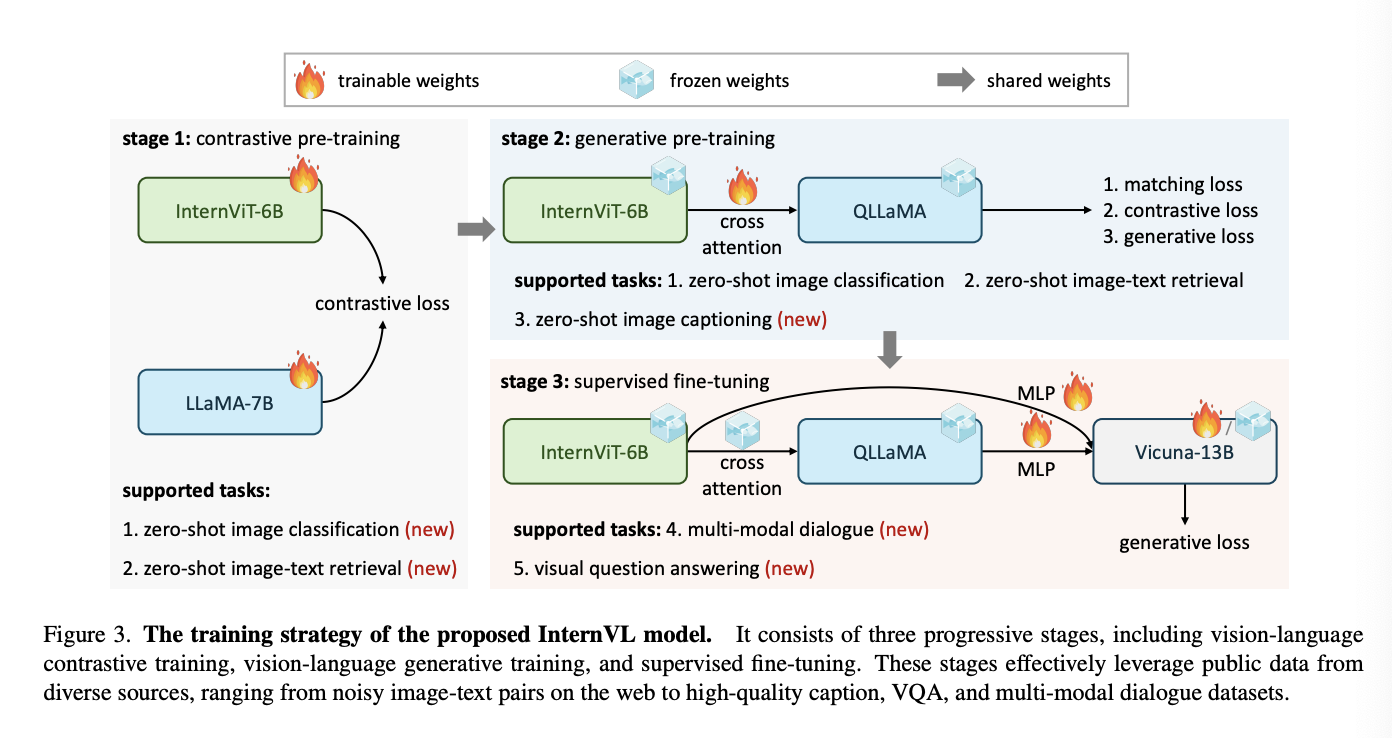
그림3과 같이, 기존 비젼-only 백본과 달리 InternVL은 InternViT-6B와 Language 미들웨어 QLLaMA로 구성된다. 특히 InternViT는 6B 규모의 비젼 트랜스포머로 성능과 효율성 트레이드오프를 조절하며 고안되었다. QLLAMA는 8B미들웨어로 다국어 LLAMA의 초깃값을 이용한다. 이는 강건한 다국적 표현을 image-text 대조학습에서 사용되며 비젼과 언어모델의 연결고리가 되어준다. 두개의 거대한 컴포넌트를 연결하기 위해 점진적 학습 기법을 사용한다. 초기에는 거대 규모의 노이즈가 많은 데이터로 대조학습을 진행하고 점차 높은 품질의 데이터로 생성 학습을 진행한다. 이 방식대로 하면 효율적인 구성과 거대 데이터의 다양한 변동성을 전부 학습하며 활용할 수 있다. 그리고 비젼 인코더와 미들웨어를 이용해 스위스 군용 나이프처럼 작동한다.

이는 일반 시각 작업에 적용할 수 있는 유연한 구성을 보이며, 이미지/비디오 텍스트 검색부터 이미지 캡션 질문 및 답변 등 여러가지를 가능케 한다.
Model Design
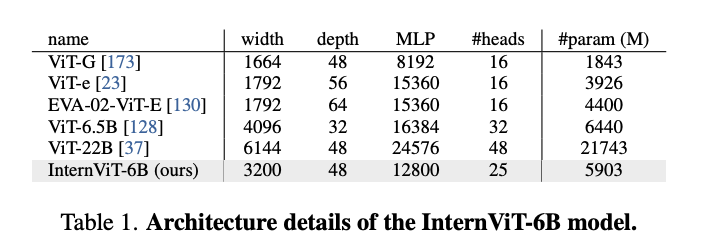
이 모델은 ViT 구조를 기반으로 하며, 언어 모델의 규모에 맞추어 비전 인코더 역시 6B 규모로 확장되었다. 이는 기존의 VLM들이 비전 인코더의 규모가 작아 성능에 제한이 있다는 한계를 극복하기 위한 시도이다. InternViT-6B를 구현하는 과정에서, 저자들은 성능(정확도), 속도, 안정성 간의 균형을 맞추기 위해 다양한 하이퍼파라미터 조합에 대해 실험을 진행했다. 구체적으로 모델 깊이(depth)는 {32, 48, 64, 80}, 헤드 차원(head dimension)은 {64, 128}, MLP 비율(MLP ratio)은 {4, 8}의 범위에서 탐색하였으며, 전체 파라미터 수를 기준으로 모델의 너비(width)와 헤드 수(head number)를 조정하여 구성했다. 성능 측정은 LAION-en 데이터셋의 1억 개 샘플을 활용한 대조 학습(contrastive learning) 기반으로 수행되었다. 실험 결과는 크게 세 가지 관찰 결과로 요약된다.
속도(Speed): GPU 자원이 완전히 활용되지 않는 상황에서는 모델 깊이가 얕을수록 이미지당 처리 속도가 빠르다. 그러나 GPU 계산이 포화되면, 깊이에 따른 속도 차이는 거의 없어진다. 이는 실전 배포 환경에서 고려할 수 있는 중요한 지표다.
정확도(Accuracy): 동일한 파라미터 수를 유지하면서 모델 깊이, 헤드 차원, MLP 비율을 바꾸어도 정확도에는 큰 영향이 없었다. 즉, 일정 규모 이상에서는 구조적 차이보다 파라미터 수 자체가 더 큰 영향을 준다는 점을 시사한다.
안정성(Stability): 실험을 통해 모델 구성 중 가장 안정적인 조합을 도출해냈으며, 최종적으로 InternViT-6B는 이 조합을 기반으로 구성되었다. 세부 조합은 논문 내 Table 1에 명시되어 있다.
이러한 과정을 통해 InternViT-6B는 기존 VLM에서의 비전 인코더 한계를 극복하고, 대규모 LLM과 균형을 맞추는 고성능 비전 백본으로 자리매김할 수 있도록 설계되었다. 이로써 InternVL1의 시각 정보 처리 능력을 크게 향상시키는 기반을 마련했다고 볼 수 있다.
언어 미들웨어 QLLaMA는 시각과 언어에 대해 얼라인을 맞추기 위해 고안되었다. 다국적 LLaMA를 기반이며 새롭게 96개의 학습 가능한 쿼리와 1B규모의 크로스 어텐션 레이어가 랜덤 초기화로 구성된다. 이러한 구조는 시각 정보를 언어 모델에 매끄럽게 통합시킨다. QLLaMA는 8B 규모인데 이는 QFormer보다 42배가 큰 규모이다. 이는 LLM decoder가 고정되어 있음에도 멀티모달 테스크를 효과적으로 수행하게 해준다. 또한 대조 학습에 이용되며 강력한 이미지 텍스트 테스크, 제로 샷 이미지 분류 또는 이미지 텍스트 검색에서 능력을 보인다.

“Swiss Army Knife” Model: InternVL.
비젼 인코더와 언어 미들웨어. InternViT-6B는 비젼 테스크에서 백본으로 사용 또한 가능하다. 이미지 분류도 가능함. 대조 테스크에서 InternVL-C와 InternVL-G를 InternViT와 QLLaMA를 시각 정보 인코딩 용으로 사용하여 보인다. 특히, 어텐션 풀링을 적용한다. 텍스트를 QLLaMA에서 인코딩하여 유사도를 계산하기도 한다. 생성 테스크에서는 QFormer와 달리 QLLaMA는 파라미터의 업으로 인한 이미지 캡셔닝 능력도 지닌다. QLLaMA의 쿼리는 비젼 정보를 재구성하여 QLLaMA의 텍스트의 prefix로 작동한다.
우린 InternVL-Chat도 소개한다. 시각 정보를 LLM에 연결함으로써. 두 개의 구조를 보이는데 이는 Figure 4의 c, d에 해당한다.
Alignment Strategy
Figure3에서 처럼, InternVL의 학습은 3번의 과정을 거친다. 대조 학습, 생성학습 그리고 지도 파인튜닝이 있다. 각각의 스테이지는 다양한 소스로 부터의 대규모 노이지 학습부터 하이 퀄리티 캡션 데이터 그리고 대화 데이터 셋까지로 이루어진다.
첫 스테이지에서는 InternVit-6B를 다국적 LLaMA-7B와 함께 대조 학습을 진행한다. 다양한 데이터의 콤비네이션을 이용하고 너무 질이 낮은 데이터는 필터링 처리한다. 총 6.03B 규모의 데이터에서 4.98B 규모 데이터만을 사용한다.
Experiments
Conclusion
🔗 관련 글
