Attention이란?
Attention : 딥러닝에서 입력 데이터의 특정 부분에 focus하여 해당 부분이 출력 생성에 얼마나 중요한지를 계산하는 메커니즘이다.
Attention이 필요성
순환신경만 RNN과 LSTM과 같은 모델은 긴 시퀀스 데이터를 처리할 때 모든 정보를 고정된 크기의 벡터로 압축해 표현하였는데 1. 긴 시퀀스에서는 주요한 정보의 손실이 쉽고 2.특정단어나 위치에 집중하는 능력이 부족하다
Attention은 중요한 정보를 동적으로 선택하고, 모델이 특정 부분에 더 집중할 수 있도록 도와주는 역할을 한다.
Attention의 작동방식
입력 데이터를 Query , Key , Value로 변환한 뒤, 이들 간의 관계를 계산해 가중치를 부여하는 방식으로 작동한다.
Query(Q) : 무엇에 집중해야할지를 나타내는 벡터로 입력 단어를 기준으로 중요한 단어를 찾기 위한 기준 역할
Key(K) : 입력 데이터의 특징을 나타내는 벡터로 Query 가 "무엇에 짐중해야 할지" 판단할 때 비교대상으로 사용
Value(V) : 최종적으로 모델이 가져갈 정보
Attention 작동방식 예시 : 기계 번역
예를 들어, 영어 문장을 프랑스어로 번역할 때:
Query는 현재 번역 중인 프랑스어 단어.
Key와 Value는 영어 단어들.Query와 Key의 유사도를 계산해, 영어 단어들 중 어떤 단어에 더 집중할지 가중치를 부여하고 해당 가중치를 Value에 곱해 번역 결과를 생성.
추가 정보 : tensor의 기본 성질
1. 어떤 정보를 기억하는 tensor는 weight를 통과하여도 이전의 정보를 가지고 있다.
2. Weighted Sum이 사용된다. Weighted Sum이란 각 항목에 특정 가중치(Weight)를 곱한 후 그 결과값들을 모두 더하는 연산으로 데이터의 각 요소가 가진 중요도를 반영해 합산하는 방식이다.
3. Inner product : 내적방식은 같은 차원 숫자끼리 곱하여 더하는 방식으로 서로 연관성이 큰 정보일수록 내적 값이 크고 서로 연관성이 적은 정보일수록 내적값이 작다. 이처럼 내적은 연관성을 나타낸다.
Attention의 동작과정
1. Query와 Key의 유사도 계산(Scoring)
Query와 Key를 비교해 각 Key가 Query와 얼마나 연관 있는지 유사도(Score)를 계산.
- 일반적으로 내적(Dot Product)을 사용:
- 유사도가 높을수록 두 단어가 더 연관 있다고 판단.
2. 가중치 계산 (Softmax)
계산된 유사도 점수를 Softmax 함수를 사용해 확률 분포로 변환.
- Softmax는 모든 점수를 0~1 사이 값으로 정규화하고, 합이 1이 되도록 만듦. -> 이는 위에서 말한 weighted sum을 사용하기 위한 과정
- 이 확률값은 특정 Key(Value) 요소가 Query와 얼마나 관련 있는지 나타냄.
3. Value에 가중치 곱하기
각 Value 벡터에 Softmax로 계산된 가중치를 곱함.
- 가중치가 높을수록 해당 Value가 최종 출력에 더 많이 기여.
4. 가중 합 계산 (Weighted Sum)
모든 Value 벡터를 가중치와 함께 더해 최종 Attention 출력을 생성:
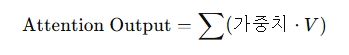
Taxonomy of Attention Mechanisms
Cross-Attention vs. Self-Attention
Cross-Attention:
Query는 출력 시퀀스, Key와 Value는 입력 시퀀스에서 생성.예: 번역 모델에서 영어(입력)와 프랑스어(출력) 간 관계.
Self-Attention:
Query, Key, Value 모두 같은 시퀀스에서 생성.
입력 시퀀스 내에서 단어 간 관계를 파악:예: "The cat sat on the mat"에서 "cat"과 "sat"의 연관성.
Soft Attention vs. Hard Attention
Soft Attention:
모든 Key에 대해 연속적인 가중치 부여.
확률적이고 미분 가능 → 학습 가능.Hard Attention:
특정 Key 하나만 선택(비연속적, 가중치가 0 또는 1).
계산은 직관적이지만, 미분 불가능하여 학습이 어렵고 복잡.
