Abstract
연구 목적
TTA는 주로 메모리가 제한된 엣지 디바이스에서 수행되므로 메모리 사용량을 줄이는 것이 중요하다. 기존의 연구들은 이러한 부분을 간과하였다.
기존의 문제점
Long term adaption으로 인한 문제점 2가지
1. Catastrophic Forgetting(망각) : Long term adaption 중 모델이 소스도메인지식을 잊고 새 도메인의 데이터에 overfittiong 될 위험이 있다.
- Error Accumulation(오류 누적) : 누적된 작은 오류들이 점점 커지면서 전체 성능 저하를 유발할 수 있다.
+Long term adaption : 딥러닝 모델이 시간이 지남에 따라 지속적으로 변화하는 데이터 분포에 적응하는 과정
해결 방법
1. Lightweight meta networks : 동결된 기존 네트워크를 대상 도메인에 적응시킬 수 있는 네트워크
- Self-distilled regularization : meta network의 출력이 동결된 기존 네트워크의 출력과 크게 벗어나지 않도록 제어
Introduction
2가지 목표
1. 메모리 효율성 향상
2. 망각 및 오류 누적 방지
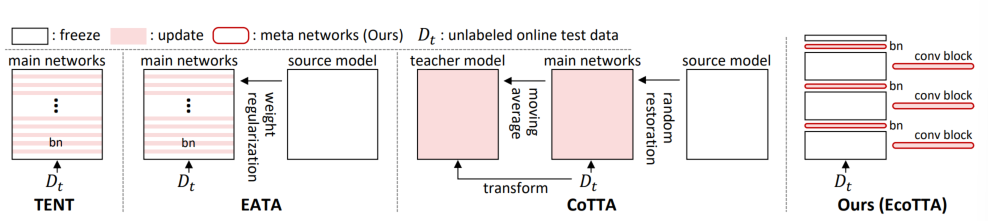
기존의 TTA 방식과 EcoTTA의 방식
- TENT
메인 네트워크(main networks)에서 배치 정규화(BN) 레이어만 업데이트되고 다수의 활성화 값이 저장되어 메모리 부담이 크다.- EATA
TENT와 유사하지만, 가중치 정규화(weight regularization)가 추가된 구조
- CoTTA
소스 모델(source model)과 교사 모델(teacher model)이 포함되며 모델 전체를 훈련하며, 무작위 복원(random restoration) 및 변환(transform) 과정이 추가된다.이로 인해 메모리와 시간이 많이 소요
- EcoTTA (제안된 방법)
메인 네트워크는 동결(freeze)되고, 새로운 메타 네트워크(meta networks)(배치 정규화 및 컨볼루션 블록)만 업데이트되며 메모리 절감과 동시에 안정적인 장기 적응이 가능하다.
목표 달성방법
1. 새로운 메타 네트워크 도입 : 동결된 기존 네트워크가 타겟 도메인에 적응하도록 지원하는 새로운 메타 네트워크 , 이는 기존 네트워크의 activation size를 줄여 메모리 효율성을 향상시킴
- self-distilled regularization 제안 : 동결된 기존 네트워크의 출력을 활용하여 메타네트워크의 출력을 제어하는 자기 증류 정규화, 이는 소스 도메인에서의 지식을 보존하고 error accumulation을 방지한다.
Related Work
1. Mitigating Domain Shift(도메인 시프트 완화)
- Unsupervised domain Adaption(비지도 도메인 적응)
: 소스 데이터를 사용해 모델을 훈련한 후 타겟 도메인 데이터에서 성능을 향상시키는 방법으로 타겟 도메인 데이터가 훈련에 사용된다.- Domain Generlization(도메인 일반화)
: 다양한 소스 도메인을 학습하여 모델이 학습하지 않은 타겟 도메인에서도 성능이 유지되도록 하는 기술로 타겟 도메인이 훈련에 사용되지 않는다.기존에는 Domian Shift문제를 해결하기 위해 2가지 기술을 사용해왔다. 하지만 주어진 소스 데이터만으로 모든 잠재적 테스트 데이터 변화에 대응하는 것은 어렵다 . 이러한 문제점을 해결하기 위해 TTA가 등장한다.
2. TTA(Test-Time Adaption)
- Unsupervised loss(비지도 학습의 정교한 손실함수)의 설계를 통한 TTA성능 향상
- Streaming test data에서 작은 배치 크기로 사용가능
기존에는 이러한 두가지 방식을 이용해 TTA의 성능을 높여왔지만 이러한 설정은 고정된 타겟 도메인에서의 적응성능을 높이는데 초점을 맞춘것으로 훈련되지 않은
경우에는 모델의 성능이 떨어진다.
CoTTA
CoTTA란 타겟 도메인이 지속적으로 변화하는 환경에서 모델이 장기간에 걸쳐 적응하는 TTA 방식
Error Accumulation : CoTTA는 비지도 학습 기반으로 Adaption이 이루어져 잘못된 예측이 반복될 수 있다.
Catastrophic Forgetting : 모델이 새로운 타겟 도메인에 적응하는 동안 , 이전에 학습한 소스 도메인의 지식을 잊어버리는 문제가 있다.
이를 해결하기 위해 CoTTA는 Random Restoration(무작위 복원)과 EMA(분산 평균) , 엔트로피 최소화를 사용한다.
Efficient On-Device Learning
- TinyTL : 학습 가능한 파라미터가 아닌 , Activation Size가 훈련 메모리의 주요 병목이라는 사실을 밝혀냈다.
이러한 사실을 바탕으로 최근 학습 연구에서는 Intermediate activations를 줄이는 방식으로 Fine-tuning이 이루어지구 있다.
Approach
3.1 Memory - efficient Architecture
기존에 Frozen Layer가 아닌 경우에는 가중치 W 를 업데이트 하기 위해서 중간 활성화 값(𝑓𝑖)를 저장해야한다.
Frozen Layer의 경우에는 가중치 업데이트 없이 Gradient만 전파되기 때문에 중간 활성화 값(𝑓𝑖)가 필요하지 않고 가중치 W 의 전치만 사용한다.
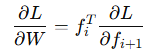
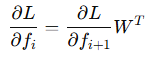
EcoTTA의 구조
순서
(배포 전)
1. EcoTTA는 가장 먼저 ImageNet과 같이 대규모 데이터셋에서 미리 훈련된 모델을 동결하여 가중치 W를 변경하지 않는다.
-> 이러한 점을 통해 중간 Activation 값을 저장하지 않아 메모리 사용이 적다.
- 사전 학습된 모델의 Encoder 부분을 K개의 부분으로 나누어 Meta Network를 부착한다.Meta Network는 배치 정규화 레이어와 컨볼루션 블록1개로 구성된 가벼운 구조이다.
이때 얕은 Layer 위주로 Meta Network를 부착한다.
얕은 Layer가 다양한 도메인에서 공통된 저수준을 추출한다. 깊은 Layer의 경우 특정 도메인에 특화될 수 있다.
- 기존 네트워크는 freeze하고 Meta Network만 소스데이터셋 Ds에서 일정 epoch동안 pre-train한다.(처음에 랜덤하게 초기화된 Meta Network는 적응력이 낮기때문)
(배포후)
4. 배포후에는 Entropy Minimization을 통해 엔트로피가 낮은 샘플만 업데이트를 합니다.(엔트로피가 높은 샘플을 업데이트 하면 오류가 누적될 위험이 커지고, 망각이 발생할 가능성이 커진다.)5.정규화를 적용하여 메타 네트워크가 원래 네트워크에서 크게 벗어나지 않도록 제한한다.
- 전체 손실함수를 통해 Meta Network를 수정하여 최적화를 진행한다.
- 전체 손실함수
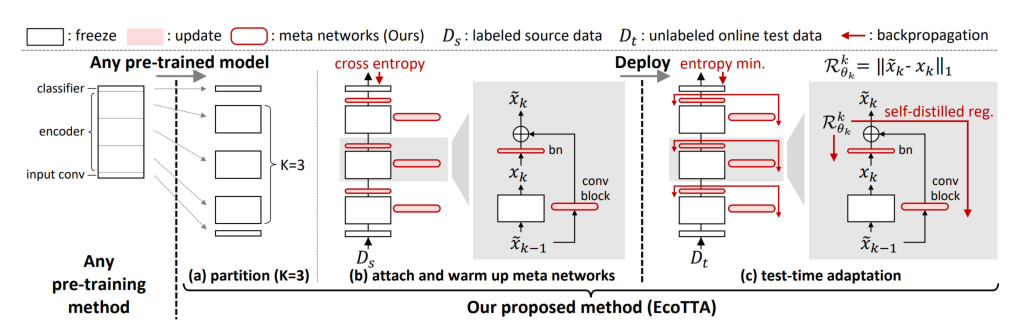
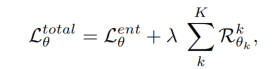
3.2 Self-distilled Regularization
메타 네트워크가 기존의 동결된 네트워크와 너무 다른 값을 출력하면 Error Accumulation문제와 Catastropfic Forgetting문제가 발생할 수 있다.
위 정규화식을 통해 adapted model이 원래 모델에서 크게 벗어나지 않도록 방지함으로써 2가지를 방지할 수 있다.1. 소스 도메인의 지식을 유지하여 망각(catastrophic forgetting)을 방지
2. 원래 모델의 클래스 판별력(class discriminability)을 이용해 오류 누적(error accumulation)을 방지
+추가적으로 위 정규화식은 엔트로피 최소화 손실과 병렬로 수행되므로 추가적인 계산비용이 거의 발생하지 않는다.
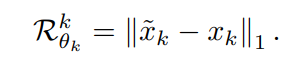
Experiment Result
Table 1 – CIFAR-C에서 지속적 TTA 성능 비교
- 데이터셋 : CIFAR10-C, CIFAR100-C (Severity level 5)
- 목적 : 다양한 지속적 TTA 기법의 성능을 오류율(%)과 메모리 사용량으로 비교
- 결론 : 논문에서 사용한 EcoTTA의 경우가 k=5일 때 낮은 오류율을 보이면서도 메모리 사용량이 현저히 적었다.
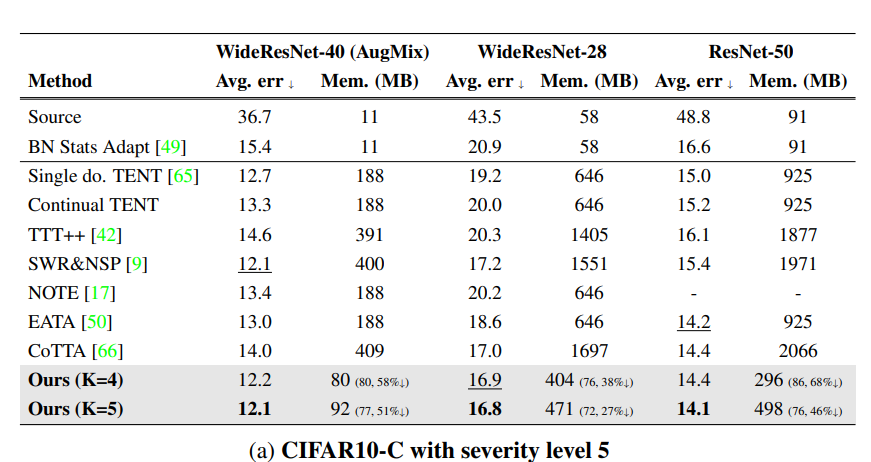
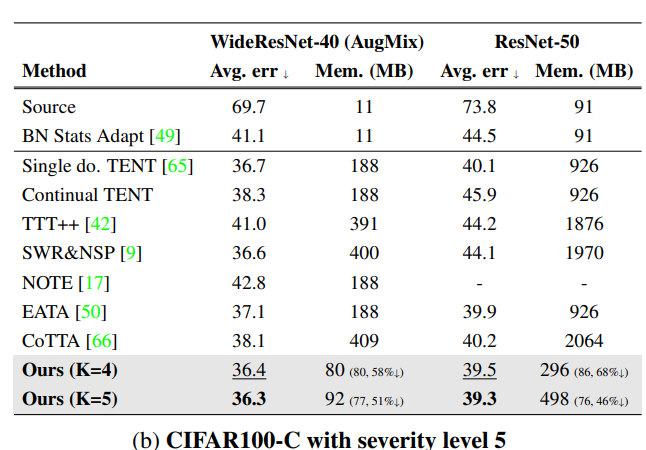
Table 2 – ImageNet-C에서 TTA 성능 비교
- 데이터셋 : ImageNet-C (Severity level 5)
- 목적: 다양한 모델이 ImageNet-C에서 Long-term-adaptiton시 보이는 성능 평가
- 결론 : ImageNet-c에서 EcoTT의 경우 k=5일때 두 번째로 낮은 오류율을 기록했다.
메모리 사용량은 CoTTA대비 k=4일때 72% , k=5일때 51% 감소하였다.
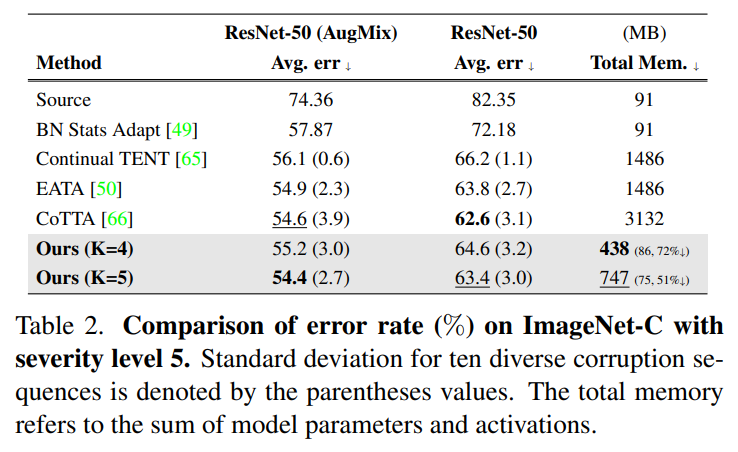
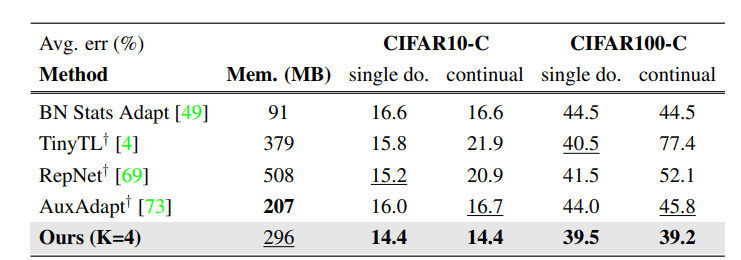
Table 3 – On-Device Learning에서의 성능 비교
- 데이터셋 : CIFAR10-C, CIFAR100-C
- 목적 : on-device learning)에서의 성능을 평가
- 결론 : CIFAR10-C에서 EcoTTA (K=4)는 14.4%로 모든 기법과 유사한 성능을 보였다. 메모리 측면에서는 EcoTTA는 TinyTL (379MB), RepNet (508MB)에 비해
상당히 적은 296MB만 사용