디스크에 저장된 데이터 파일의 크기가 클수록 쿼리 처리 성능은 안좋아지고 백업과 복구가 오래걸린다.
많은 DBMS는 이러한 문제를 해결하기 위해 데이터 압축 기능을 제공하며, MySQL은 크게 테이블 압축과 페이지 압축 두가지의 데이터 압축 기능이 존재한다.
1. 페이지 압축
Transparent Page Compression 이라고 불리는데 이유는 다음과 같다.
- MySQL 서버가 디스크에 저장하는 시점에 데이터 페이지가 압축되어 저장
- MySQL 서버가 데이터를 읽어올 때 압축이 해제된다.
즉, 디스크에서 꺼내올 때 압축이 해제되므로 InnoDB 스토리지 엔진은 압축이 해제된 상태로만 데이터 페이지를 관리한다.
이렇듯 MySQL 서버의 내부 코드에서는 압축 여부와 상관없이 투명(Tranparent)하게 작동하기에 두 가지 단점이 존재한다.
- 데이터 페이지 압축 용량 예측 불가능
- 적어도 하나의 테이블은 동일한 크기의 페이지(블록)으로 통일되어야 한다.
이를 해결하기 위해 펀치 홀(Punch Hole) 기능을 사용한다. 이를 활용하여 페이지 압축이 작동하는 방식은 아래와 같다.
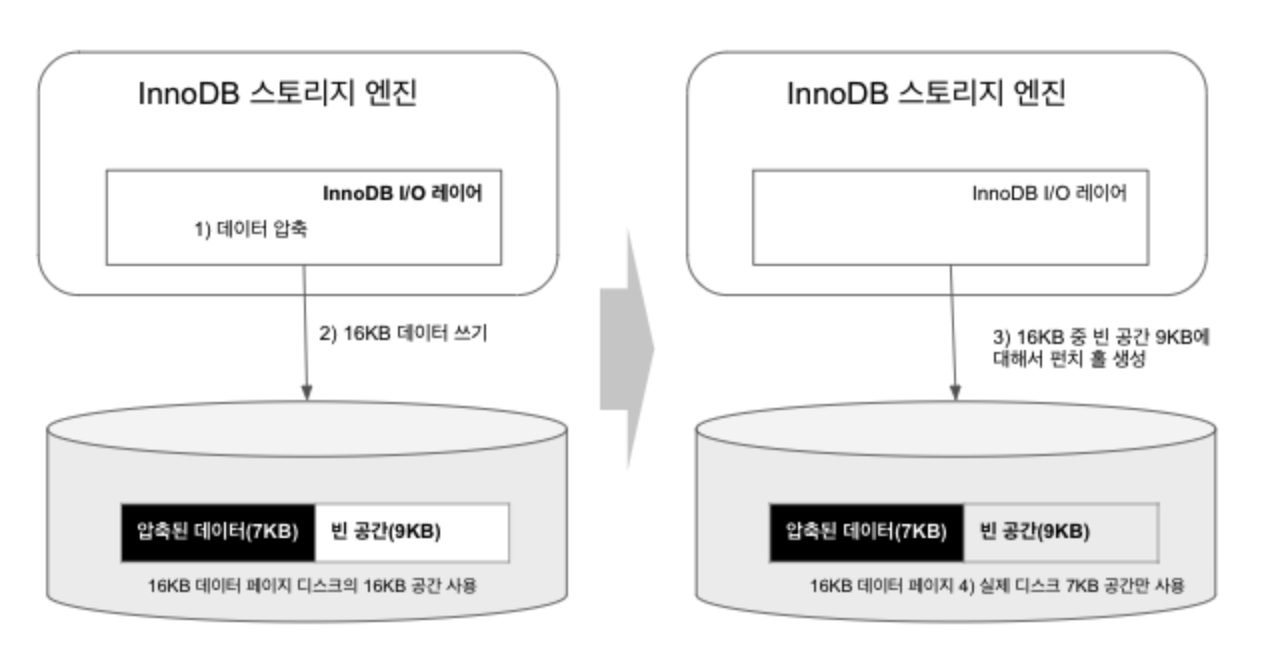
그림 6.1 페이지 압축의 작동 방식
- 16KB 페이지를 압축(압축 결과를 7KB로 가정)
- MySQL 서버는 디스크에 압축된 결과 7KB를 기록
(이 때, MySQL 서버는 압축 데이터 7KB에 9KB의 빈 데이터를 기록) - 디스크에 데이터를 기록 후, 9KB 공간에 대해 펀치 홀 생성
- 파일 시스템은 7KB만 남기고 나머지 9KB는 운영체제에 반납
그러나 펀치홀은 OS 뿐만 아니라 하드웨어 자체에서나 파일 시스템 관련 명령어(유틸리티)에서도 지원을 해야한다. 예를 들어 MySQL 서버의 데이터 파일을 백업했다 복구하는 과정에서 많은 파일관련 유틸리티를 사용하는데 이것이 펀치 홀을 지원하지 않으면 실제 데이터 파일의 크기는 원본 크기가 될 수 있다.
이런 이유로 페이지 압축은 많이 사용되지 않는다.
2. 테이블 압축
페이지 압축과 달리 OS나 하드웨어에 대한 제약이 없기에 활용도가 높지만 다음과 같은 단점이 존재한다.
- 버퍼 풀 공간 활용률이 낮음
- 쿼리 처리 성능 낮음
- 빈번한 데이터 변경 시 압축률 감소
이러한 단점이 발생하는 이해하려면 테이블 압축의 작동원리를 단계별로 먼저 이해해야 한다.
2.1 압축 테이블 생성
테이블 생성 시 전제 조건
- 압축을 사용하려는 테이블이 별도의 테이블 스페이스를 사용해야 한다.
innodb_file_per_table시스템 변수를ON으로 설정
ROW_FORMAT=COMPRESSED옵션 명시- 이는 생략 가능
KEY_BLOCK_SIZE옵션을 통해 압축된 페이지의 타겟 크기를 명시
mysql> SET GLOBAL innodb_file_per_table=ON;
-- // ROW_FORMAT 옵션과 KEY_BLOCK_SIZE 옵션을 모두 명시
mysql> CREATE TABLE compressed_table (
c1 INT PRIMARY KEY,
)
ROW_FORMAT=COMPRESSED
KEY_BLOCK_SIZE=8;
-- // KEY_BLOCK_SIZE 옵션만 명시
mysql> mysql> CREATE TABLE compressed_table (
c1 INT PRIMARY KEY,
)
KEY_BLOCK_SIZE=8;InnoDB 스토리지 엔진의 데이터 페이지(블록)의 크기가 16KB, 그리고 KEY_BLOCK_SIZE=8인 경우에 압축을 적용하는 방법은 다음과 같다.
- 16KB의 데이터 페이지 압축
1-1. 압축된 결과가 8KB 이하이면 그대로 디스크에 저장 (압축 완료)
1-2. 압축된 결과가 8KB 보다 크면 원본 페이지를 분리(split)해서 2개의 페이지에 8KB씩 저장 (압축 실패) - 1-2에서 나뉜 페이지에 대해 각각 (1) 과정 반복 시행
재귀함수 형태로 압축을 적용하는 것과 KEY_BLOCK_SIZE 값이 압축 성공률을 결정하는 가장 큰 요인이라는 것을 알 수 있다.
따라서, KEY_BLOCK_SIZE 값을 잘 설정해야 하는데 어떻게 최적값을 찾을 수 있을까?
2.2 KEY_BLOCK_SIZE 결정
KEY_BLOCK_SIZE 값을 잘 설정하기 위해선 이 값을 4KB, 8KB로 테이블을 생성해서 샘플 데이터를 저장해보고 적절한지 판단하는 것이 좋다.
이 때, 샘플 데이터는 많으면 많을수록 더 좋은데 최소한 데이터 페이지가 10개 정도는 되도록 데이터를 INSERT 하는 것이 좋다.
일반적으로 압축 실패율이 작을 수록 좋다고 생각을 할 것이다. 하지만 꼭 그렇지만은 않다. 압축 실패율은 3% ~ 5% 미만 수준으로 유지하는 것이 좋다.
만약, 압축 실패율이 높지만 압축으로 인해 데이터 파일의 크기가 큰 폭으로 줄어드는 경우(이 경우를 압축 기대이익이 높다고도 표현한다.) 압축을 고려해볼 필요가 있다.
또한, 압축 알고리즘은 생각보다 많은 CPU 자원을 소모하는데 압축하려는 테이블이 자주 조회나 변경이 되는 경우엔 압축을 고려하지 않는 것이 좋다.
2.3 압축된 페이지의 버퍼 풀 적재 및 사용
InnoDB 스토리지 엔진은 압축된 테이블의 데이터 페이지를 버퍼 풀에 적재하면 압축된 상태와 압축이 해제된 상태 2개의 버전을 관리한다.
결국 InnoDB 스토리지 엔진은 압축된 테이블에 대해 버퍼 풀의 공간을 이중으로 사용하기에 메모리를 낭비하게 된다. 또한, 압축된 페이지의 데이터를 읽거나 변경하기 위해서는 압축을 해제해야 하는데 이는 많은 CPU 자원을 소모한다.
이러한 두 가지 단점을 보완하기 위해 Unzip_LRU 리스트를 별도로 관리하고 있다가 MySQL 서버로 유입되는 유청 패턴에 따라 적절히 처리한다.
