이번 장에서는 MySQL의 동시성과 영향을 미치는 잠금(Lock)과 트랜잭션, 트랜잭션의 격리 수준(Isolation level)을 살펴보겠다.
잠금(Lock)과 트랜잭션은 서로 비슷한 개념같지만 궁극적 목표는 조금은 다르다.
- 잠금
- 동시성을 제어하기 위한 기능
- 하나의 데이터를 여러 커넥션에서 동시에 변경하여 해당 레코드를 예측할 수 없는 상태를 방지
- 여러 커넥션에서 동시에 동일한 자원(레코드나 테이블)을 요청한 경우 순서대로 한 시점에는 하나의 커넥션만 변경해주는 역할
- 트랜잭션
- 데이터의 정합성을 보장하기 위한 기능
- 작업의 완전성을 보장
- 논리적인 작업 셋을 모두 완벽하게 처리하거나 못한 경우에는 원 상태로 복구해서 작업의 일부만 적용되는 현상(Partial update)가 발생하지 않게 만들어주는 기능
참고
격리 수준(Isolation level) : 하나의 트랜잭션 내에서 또는 여러 트랜잭션 간의 작업 내용을 어떻게 공유하고 차단할 것인지를 결정하는 레벨
1. 트랜잭션
많은 사용자들이 데아터베이스 서버에서 트랜잭션이 개발자에게 얼마나 큰 혜택을 제공하는지를 자주 잊어버리는 것 같다. 최근 들어 InnoDB에 비해 덜 복잡한 MyISAM이나 MEMORY 스토리지 엔진을 사용하지 않는 가장 큰 이유들 중 하나는 이들이 트랜잭션을 지원하지 않는다는 것에 있다.
이번 절에서는 트랜잭션을 지원하지 않는 MyISAM과 트랜잭션을 지원하는 InnoDB의 처리 방식 차이와 트랜잭션을 사용할 경우 주의할 사항에 대해 잠깐 살펴보자.
1.1 MySQL에서의 트랜잭션
트랜잭션은 꼭 여러 개의 변경 작업을 수행하는 쿼리가 조합되었을 때만 의미 있는 개념은 아니다. 트랜잭션은 하나의 논리적인 작업 셋에 하나의 쿼리가 있든 두 개 이상의 쿼리가 있든 관계없이 논리적인 작업 셋 자체에 몇 개의 쿼리가 있든 상관없이 논리적인 작업 셋 자체가 100% 적용되거나(COMMIT을 실행했을 때) 아무것도 적용되지 않아야(ROLLBACK 또는 트랜잭션을 ROLLBACK 시키는 오류 발생했을 때) 함을 보장해주는 것이다.
간단한 예제로 트랜잭션 관점에서 InnoDB 테이블과 MyISAM 테이블의 차이를 살펴보자.
<MyISAM>
mysql> CREATE TABLE tab_myisam (
fdpk INT NOT NULL,
PRIMARY KEY (fdpk)
)
ENGINE=MyISAM;
mysql> INSERT INTO tab_myisam (fdpk)
VALUES (3);
<InnoDB>
mysql> CREATE TABLE tab_innodb (
fdpk INT NOT NULL,
PRIMARY KEY (fdpk)
)
ENGINE=InnoDB;
mysql> INSERT INTO tab_innodb (fdpk)
VALUES (3);위와 같이 테스트용 테이블에 각각 레코드를 1건씩 저장한 후 AUTO-COMMIT 모드에서 다음 쿼리 문장을 InnoDB 테이블과 MyISAM 테이블에서 각각 실행해 보자.
<AUTO-COMMIT 활성화>
mysql> SET autocommit=ON;
mysql> INSERT INTO tab_myisam (fdpk) VALUES (1), (2), (3);
mysql> INSERT INTO tab_innodb (fdpk) VALUES (1), (2), (3);두 개의 스토리지 엔진에서 결과가 어떻게 다를까? 위 쿼리 문장의 테스트 결과는 다음과 같다.
ERROR 1062 (23000): Duplicate entry '3' for key 'PRIMARY'두 INSERT 문장 모두 프라이머리 키 중복 오류로 쿼리가 실패했다. 그런데 다음처럼 두 테이블의 레코드를 조회해보면 MyISAM 테이블에는 오류가 발생했음에도 '1'과 '2'는 INSERT 된 상태로 남아있는 것을 확인할 수 있다.
mysql> SELECT * FROM tab_myisam;
mysql> SELECT * FROM tab_innodb;즉, MyISAM 테이블에 INSERT 문장이 실행되면서 차례대로 '1', '2'를 저장 후 '3'을 저장하려고 하는 순간 중복 키 오류(이미 '3'이 있기 때문에)가 발생한 것이다. MyISAM 테이블에서 실행되는 쿼리는 이미 INSERT 된 '1', '2'를 그대로 두고 쿼리 실행을 종료해버린다. 이렇게 쿼리 중 일부만 업데이트되는 현상을 부분 업데이트(Partial Update)라고 한다. MEMORY 스토리지 엔진을 사용하는 테이블 또한 이와 동일하다.
하지만, InnoDB는 쿼리 중 일부라도 오류가 발생하면 전체를 원 상태로 만든다는 트랜잭션의 원칙대로 INSERT 문장 실행 전 상태로 복구된다.
어떤 사용자는(특히 트랜잭션이 선택 사항인 MySQL의 경우) 트랜잭션을 상당히 골치 아픈 기능으로 생각하지만 그만큼 어플리케이션 개발에서 고민해야 할 문제를 줄여주는 아주 필수적인 DBMS의 기능이라는 점을 기억해야 한다.
위처럼 부분 업데이트 현상이 발생하면 다시 삭제를 재처리하는 작업이 필요할 수 있다. 이러한 쿼리가 하나 뿐이라면 상관없겠지만 여러 개의 쿼리가 실행되는 경우라면 이는 상당한 고민거리 될 것이다.
1.2 주의사항
트랜잭션 또한 DBMS의 커넥션과 동일하게 꼭 필요한 최소의 코드에만 적용하는 것이 좋다. 이는 프로그램 코드에서 트랜잭션의 범위를 최소화하라는 의미이다.
다음 내용은 사용자가 게시판에 게시물을 작성한 후 저장 버튼을 클릭했을 때 서버에서 처리하는 내용을 순서대로 정리한 것이다. 물론, 실제로는 이보다 내용이 훨씬 복잡하고 다양하겠지만 여기선 설명의 단순화를 위해 간단히 나열했다.
1) 처리 시작
=> 데이터베이스 커넥션 생성
=> 트랜잭션 시작
2) 사용자의 로그인 여부 확인
3) 사용자의 글쓰기 내용의 오류 여부 확인
4) 첨부로 업로드된 파일 확인 및 저장
5) 사용자의 입력 내용을 DBMS에 저장
6) 첨부 파일 정보를 DBMS에 저장
7) 저장된 내용 또는 기타 정보를 DBMS에서 조회
8) 게시물 등록에 대한 알림 메일 발송
9) 알림 메일 발송 이력을 DBMS에 저장
<= 트랜잭션 종료(COMMIT)
<= 데이터베이스 커넥션 반납
10) 처리 완료위 처리 절차들 중에서 DBMS의 트랜잭션 처리에 좋지 않은 영향을 미치는 부분을 나눠서 살펴보자.
- 실제로 많은 개발자가 데이터베이스의 커넥션을 생성(또는 커넥션 풀에서 가져오는 작업)하는 코드를 1번과 2번 사이에 구현하며 그와 동시에
START TRASACTION명령으로 트랜잭션을 시작한다. 그리고, 9번과 10번 사이에서 트랜잭션을COMMIT하고 커넥션을 종료(또는 커넥션 풀에 반납)한다.
그래서, 2, 3, 4번 절차가 아무리 빨리 처리되어도 DBMS의 트랜잭션에 포함시킬 필요는 없다.- 일반적으로 데이터베이스 커넥션은 개수가 한정적이기에 각 단위 프로그램이 커넥션을 소유하는 시간이 길어질 수록 사용 가능한 여유 커넥션의 개수는 줄어든다.
- 따라서, 어느 순간에는 각 단위 프로그램에서 커넥션을 가져가기 위해 기다려야 하는 상황이 발생할 수 있다.
- 더 큰 위험작업은 8번이다. 메일 전송이나 FTP 파일 전송 작업 또는 네트워크를 통해 원격 서버와 통신하는 등과 같은 작업은 어떻게 해서든 트랜 잭션 내에서 제거하는 것이 좋다. 프로그램시 실행되는 동안 메일 서버와 통신할 수 없는 상황이 발생한다면 웹 서버뿐 아니라 DBMS 서버까지 위험해지는 상황이 초래된다.
- 이 처리 절차에는 DBMS의 작업이 크게 4가지가 있다.
- 사용자가 입력한 정보를 저장하는 5번과 6번의 작업은 반드시 하나의 트랜잭션으로 묶여야 한다.
- 7번 작업은 저장된 데이터의 단순 확인 및 조회이므로 트랜잭션에 포함시킬 필요 없다. 이 작업이 단순 조회라 본다면 별도로 트랜잭션을 사용하지 않아도 된다.
- 9번 작업은 조금 성격이 다르기 때문에 이전 트랜잭션(5번과 6번 작업)에 함께 묶이지 않아도 무방해보인다. 이러한 작업은 별도의 트랜잭션으로 분리하는 것이 좋다.
문제가 될 만한 3가지를 보완해서 위의 처리 절차를 다시 한 번 설계해보자.
1) 처리 시작
2) 사용자의 로그인 여부 확인
3) 사용자의 글쓰기 내용의 오류 발생 여부 확인
4) 첨부로 업로드된 파일 확인 및 저장
=> 데이터베이스 커넥션 생성(또는 커넥션 풀에서 가져오기)
=> 트랜잭션 시작
5) 사용자의 입력 내용을 DBMS에 저장
6) 첨부 파일 정보를 DBMS에 저장
<= 트랜잭션 종료(COMMIT)
7) 저장된 내용 또는 기타 정보를 DBMS에서 조회
8) 게시물 등록에 대한 알림 메일 발송
=> 트랜잭션 시작
9) 알림 메일 발송 이력을 DBMS에 저장
<= 트랜잭션 종료(COMMIT)
<= 데이터베이스 커넥션 종료(또는 커넥션 풀에 반납)
10) 처리 완료앞에서 보여준 예제가 최적의 트랜잭션 설계는 아닐 수 있으며, 구현하고자 하는 업무의 특성에 따라 크게 달라질 수 있다. 여기서 설명하려는 바는 프로그램의 코드가 데이터베이스 커넥션을 가지고 있는 범위와 트랜잭션이 활성화 되어있는 프로그램의 범위를 최소화해야 한다는 것이다.
또한, 프로그램의 코드에서 라인 한 두줄이라고 하더라도 네트워크 작업이 있는 경우에는 반드시 트랜잭션에서 배제해야 한다. 이런 실수로 인해 DBMS 서버가 높은 부하 상태로 빠지거나 위험한 상태에 빠지는 경우가 빈번이 발생하기 때문이다.
2. MySQL 엔진의 잠금
MySQL에서 사용되는 잠금은 크게 다음 두 가지로 나눌 수 있다.
- 스토리지 엔진 레벨
- 스토리지 엔진 간 상호 영향을 미치지 않는다.
- MySQL 엔진 레벨
- MySQL 서버에서 스토리지 엔진을 제외한 나머지 부분
- 모든 스토리지 엔진에 영향을 미친다.
- 테이블 데이터 동기화를 위한 테이블 락(Table Lock) 제공
- 테이블의 구조를 잠그는 메타데이터 락(Metadata Lock) 제공
- 사용자의 필요에 맞게 사용할 수 있는 네임드 락(Named Lock) 제공
이러한 잠금들의 특징과 어떤 경우에 사용되는지에 대해 알아보자.
2.1 글로벌 락
'글로벌'이라는 단어에서 알 수 있듯 MySQL에서 제공하는 잠금 가운데 가장 범위가 크다. FLUSH TABLES WITH READ LOCK 명령어를 통해 획득할 수 있다.
일단 한 세션에서 글로벌 락을 획득하면 다른 세션에서 SELECT를 제외한 대부분의 DDL 또는 DML 문장을 실행하는 경우 글로벌 락이 해제될 때 까지 해당 문장은 대기 상태로 남는다.
글로벌 락이 영향을 미치는 범위는 MySQL 서버 전체이며, 작업 대상 테이블이나 데이터베이스가 다르더라도 동일하게 영향을 미친다.
여러 데이터베이스에 존재하는 MyISAM이나 MEMORY 테이블에 대해 mysqldump로 일관된 백업을 받아야 할 때는 글로벌 락을 사용해야 한다.
주의
글로벌 락을 거는FLUSH TABLES WITH READ LOCK명령어는 실행과 동시에 MySQL 서버에 존재하는 모든 테이블을 닫고 잠금을 건다.그러므로, 이 명령어가 실행되기 전에 테이블이나 레코드에 쓰기 잠금을 거는 SQL이 실행된 상태라면 이 명령은 해당 테이블의 읽기 잠금을 걸이 위해 먼저 실행된 SQL과 그 트랜잭션이 완료될 때 까지 기다려야 한다.
또한, 이 명령어는 테이블에 읽기 잠금을 걸기 전에 먼저 테이블을 플러시해야 하기 때문에 테이블에 실행 중인 모든 종류의 쿼리가 완료되어야 한다.
장시간 실행되는 쿼리와 이 명령어가 맞물리면 DDL에 대해 엄청난 대기가 발생할 수 있으므로 웹 서비스용으로 사용되는 MySQL 서버에서는 가급적을 사용하지 않는 것이 좋다.
이미 살펴본 바와 같이 FLUSH TABLES WITH READ LOCK 명령어를 이용한 글로벌 락은 MySQL 서버의 모든 변경작업을 멈춘다. 하지만, InnoDB 스토리지 엔진은 트랜잭션을 지원하기 때문에 일관된 데이터 상태를 위해 모든 데이터 변경 작업을 멈출 필요는 없다.
또한, 백업 툴들의 안정적인 실행을 위해 백업 락이 도입되었다. 특정 세션에서 백업 락을 획득하면 모든 세션에서 다음과 같이 테이블이 스키마나 사용자의 인증 정보를 변경할 수 없게 된다.
- 데이터베이스 및 테이블 등 모든 객체 생성, 변경 및 삭제
REPAIR TABLE과OPTIMIZE TABLE명령- 사용자 관리 및 비밀 번호 변경
하지만, 백업 락은 일반적인 테이블의 데이터 변경은 허용된다. 굳이 기존보다 더 가벼운 글로벌 락이 왜 도입되었을까? 그 이유를 살펴보자.
일반적으로 MySQL 서버는 크게 다음 두 가지로 구성된다.
- 소스 서버(Source server)
- 레플리카 서버(Replica server)
주로 백업은 레플리카 서버에서 실행된다. 여기서 백업이 FLUSH TABLES WITH READ LOCK 명령을 이용해 글로벌 락을 획득하면 복제는 백업 시간만큼 지연될 수 밖에 없다. 레플리카 서버에서 백업을 실행하는 도중에 소스 서버에 문제가 생기면 레플리카 서버의 데이터가 최신 상태가 될 때 까지 서비스를 멈춰야할 수도 있다.
물론, 백업 툴들은 모두 복제가 진행되는 상태에서도 일관된 백업을 만들 수 있지만, 복제가 진행되는 도중 스키마 변경이 실행되면 백업은 실패하게 된다. 몇 시간동안 백업이 실행되고 있는데, DDL 명렁 하나로 인해 백업이 실패하면 다시 그만큼 시간을 들여서 백업을 해야된다.
이러한 이유 때문에 백업 락이 도입되었으며, 정상적으로 복제는 되지만 백업의 실패를 막기 위해 DDL 명령이 실행되면 복제를 일시 중지하는 역할을 한다.
2.2 테이블 락
개별 '테이블' 단위로 설정되는 잠금이며, 명시적 또는 묵시적으로 특정 테이블의 락을 획득할 수 있다. 두 가지 상황으로 구분하여 알아보자.
명시적 테이블 락
명시적으로 특정 테이블의 락을 얻으려면 다음 명령어를 실행하면 된다.
LOCK TABLES (테이블 이름) READ;
LOCK TABLES (테이블 이름) WRITE;이러한 테이블 락은 MyISAM뿐만 아니라 InnoDB 스토리지 엔진을 사용하는 테이블도 동일하게 설정할 수 있다.
명시적으로 획득한 잠금은 다음 명령어를 통해 잠금을 반납할 수 있다.
UNLOCK TABLES (테이블 이름);명시적인 테이블 락도 특별한 상황이 아니면 어플리케이션에서 사용할 일이 거의 없다. 이 작업은 글로벌 락과 동일하게 온라인 작업에 상당한 영향을 미치기 때문이다.
묵시적 테이블 락
묵시적인 테이블 락은 MyISAM이나 MEMORY 테이블에 데이터를 변경하는 쿼리를 실행하면 발생한다. MySQL 서버가 데이터가 변경되는 테이블에 잠금을 설정하고 데이터를 변경한 후, 즉시 잠금을 해제하는 형태로 사용된다. 즉, 쿼리가 실행되는 동안 자동으로 획득되었다 쿼리가 완료된 후 자동으로 해제된다.
하지만, InnoDB 테이블의 경우 스토리지 엔진 차원에서 레코드 기반의 잠금을 제공하기 때문에 단순 데이터 변경 쿼리로 인해 묵시적인 테이블 락이 설정되진 않는다. 더 정확히는 InnoDB 테이블에도 테이블 락이 설정되지만 대부분의 데이터 변경(DML) 쿼리는 뭄시되고 스키마를 변경하는 쿼리(DDL) 의 경우에만 영향을 미친다.
2.3 네임드 락
네임드 락(Named Lock)은 GET_LOCK() 함수를 이용해 임의의 문자열에 대해 잠금을 설정할 수 있다. 단순히 사용자가 지정한 문자열(String)에 대해 일정 시간동안 잠금을 획득하고 시간이 지나면 반납하는 잠금이다.
이 잠금의 특징은 테이블이나 레코드 또는 AUTO_INCREMENT와 같은 데이터베이스 객체가 아니라는 것이다.
이 같은 네임드 락은 자주 사용되진 않으며 특정 상황에서 사용되는데 예시로 살펴보자.
데이터베이스 서버 1대에 5대의 웹 서버가 접속해서 서비스를 제공하는 상황이라면 5대의 웹 서버가 어떤 정보를 동기화해야 하는 요건처럼 여러 클라이언트가 상호 동기화를 처리해야 할 때 다음과 같이 네임드 락을 사용하면 쉽게 해결할 수 있다.
-- "mylock"이라는 문자열에 대해 잠금을 획득한다.
-- 이미 잠금을 사용 중이면 2초 동안 대기한다. (2초 이후에 잠금이 자동 해제됨)
mysql> SELECT GET_LCOK('mylock', 2);
-- "mylock"이라는 문자열에 대해 잠금이 설정되어 있는지 확인한다.
mysql> SELECT IS_FREE_LOCK('mylock');
-- "mylock"이라는 문자열에 대해 획득했던 잠금을 반납(해제)한다.
mysql> SELECT RELEASE_LOCK('mylock');
-- 모든 네임드 락을 해제
mysql> SELECT RELEASE_ALL_LOCKS();
-- 4개 함수 모두 정상적으로 락을 획득 또는 반납 한 경우에는 1
-- 아니면 NULL이나 0을 리턴또한, 많은 레코드에 대해서 복잡한 요건으로 레코드를 변경하는 트랜잭션에 유용하게 사용될 수 있다. 배치 프로그램처럼 한꺼번에 많은 레코드를 변경하는 쿼리는 자주 데드락의 원인이 된다. 각 프로그램의 실행시간을 분석 또는 프로그램 코드 수정을 통해 이를 최소화할 수 있지만, 이는 복잡하며 완전한 해결책이 될 수 없다.
이러한 경우에 동일 데이터를 변경하거나 참조하는 프로그램끼리 분류해서 네임드 락을 걸고 쿼리를 실행하면 아주 간단히 해결할 수 있다.
참고
배치 프로그램(Batch Program) : 사용자와의 상호 작용 없이 여러 작업들을 미리 정해진 일련의 순서에 따라 일괄적으로 처리하는 것을 의미
2.4 메타데이터 락
메타데이터 락은 데이터베이스 객체(대표적으로 테이블이나 뷰 등)의 이름이나 구조를 변경하는 경우에 획득하는 잠금이다. 명시적으로 획득하거나 해제할 수 있는 것이 아니고 RENAME TABLE (현재 이름) TO (바꿀 이름) 같이 테이블의 이름을 변경하는 경우 자동으로 획득하는 잠금이다.
RENAME TABLE 명령어의 경우 원본 이름과 변경될 이름 두 개 모두 한꺼번에 잠금을 설정한다. 또한, 시간으로 테이블을 바꿔야 하는 요건이 배치 프로그램에서 자주 발생하는데, 다음 예제를 잠깐 살펴보자.
-- 배치 프로그램에서 별도의 임시 테이블(rank_new)에 서비스용 랭킹 데이터를 생성
-- 랭킹 배치가 완료되면 현재 서비스용 랭킹 테이블(rank)을 rank_backup 으로 백업후
-- 새로 만들어진 랭킹 테이블(rank_new)을 서비스용으로 대체하는 경우
mysql> RENAME TABLE rank TO rank_backup, rank_new TO rank;위와 같이 RENAME TABLE 명령문에 두 개의 RENAME 작업을 한꺼번에 실행하면 실제 어플리케이션에서는 " Table not found 'rank' " 같은 상황을 발생시키지 않고 적용하는 것이 가능하다.
하지만, 이 문장을 다음과 같이 2개로 나누면 rank 테이블이 rank_backup으로 바뀐 그 짧은 순간에 rank 테이블이 존재하지 않기 때문에 " Table not found 'rank' " 오류가 발생한다.
mysql> RENAME TABLE rank TO rank_backup;
mysql> RENAME TABLE rank_new TO rank; => 이 부분에서 오류 발생때로는 메타데이터 잠금과 InnoDB의 트랜잭션을 동시에 사용해야 하는 경우도 있다. 예를 들어 다음과 같은 구조의 INSERT만 실행되는 로그 테이블을 가정해보자. 이 테이블은 웹 서버의 엑세스(접근) 로그를 저장하기 때문에 UPDATE, DELETE가 없다.
mysql> CREATE TABLE access_log (
id BIGINT NOT NULL AUTO_INCREMENT,
client_ip INT UNSIGNED,
access_dttm TIMESTAMP,
...
PRIMARY KEY(id)
);그런데 테이블의 구조를 변경해야 하는 상황이 발생했다. 물론 MySQL 서버의 Online DDL을 이용해서 변경할 수도 있지만 시간이 너무 오래 걸리는 경우라면 언두 로그의 증가와 Online DDL이 실행되는 동안 누적된 Online DDL 버퍼의 크기 등 고민해야 할 문제가 많다. 더 큰 문제는 MySQL 서버의 DDL은 단일 스레드로 작동하기 때문에 상당히 많은 시간이 소모될 것이라는 점이다.
이 때는, 새로운 구조의 테이블을 생성하고 먼저 최근(1시간 직전 또는 하루 전)의 데이터까지는 PK 값인 id 값을 범위별로 나눠서 여러 개의 스레드로 빠르게 복사한다.
-- 테이블의 압축을 적용하기 위해 KEY_BLOCK_SIZE=4 옵션을 추가해 신규 테이블을 생성
mysql> CREATE TABLE access_log_new (
id BIGINT NOT NULL AUTO INCREMENT,
client_ip INT UNSIGNED,
access_dttm TIMESTAMP,
...
PRIMARY KEY(id)
) KEY_BLOCK_SIZE=4;
-- 4개의 스레드를 이용해 id 범위별로 레코드를 신규 테이블로 복사
mysql_thread1> INSERT INTO access_log_new SELECT * FROM access_log WHERE id>=0 AND id<10000;
mysql_thread2> INSERT INTO access_log_new SELECT * FROM access_log WHERE id>=10000 AND id<20000;
mysql_thread3> INSERT INTO access_log_new SELECT * FROM access_log WHERE id>=20000 AND id<30000;
mysql_thread4> INSERT INTO access_log_new SELECT * FROM access_log WHERE id>=30000 AND id<40000;그리고 나머지 데이터는 다음과 같이 트랜잭션과 테이블 잠금, RENAME TABLE 명령으로 응용 프로그램 중단없이 실행할 수 있다. 이 때, "남은 데이터를 복사"하는 시간 동안은 테이블의 잠금으로 인해 INSERT를 할 수 없다. 그래서 가능하면 미리 아주 최근 데이터까지 복사해둬야 잠금 시간을 최소화하여 서비스에 미치는 영향을 줄일 수 있다.
-- 트랜잭션을 autocommit으로 실행(BEGIN, START TRACSCATION X)
mysql> SET autocommit=0;
-- 작업 대상 테이블 2개에 대해 테이블 쓰기 락 획득
mysql> LOCK TABLES access_log WRITE, access_log_new WRITE;
-- 남은 데이터를 복사
mysql> SELECT MAX(id) as @MAX_ID FROM access_log_new;
mysql> INSERT INTO access_log_new SELECT * FROM access_log WHERE pk>@MAX_ID;
-- 새로운 테이블로 데이터 복사가 완료되면 RENAME 명령으로 새로운 테이블을 서비스로 투입 후 잠금 해제
-- (이 때, RENAME 구문은 한 번에 실행해야 한다.)
mysql> RENAME TABLE access_log TO access_log_old,, access_log_new TO access_log;
mysql> UNLOCK TABLES;
-- 불필요한 테이블 삭제
mysql> DROP TABLE access_log_old;참고
위 코드 맨 윗줄의autocommit은 데이터 변경 작업에 대한 SQL 자체가 바로 반영되는 것을 의미하는데autocommit이 아닌 상태에서는 여러줄의 명령을 하나의 트랜잭션으로 묶을수가 있다.
3. InnoDB 스토리지 엔진 잠금
InnoDB 스토리지 엔진은 MySQL에서 제공하는 잠금과는 별개로 스토리지 엔진 내부에서 레코드 기반의 잠금 방식을 탑재하고 있다. 이 때문에 MyISAM보다 훨씬 뛰어난 동시성 처리를 제공한다.
그러나, 이원화된 잠금 처리 탓에 InnoDB 스토리지 엔진에서 사용되는 잠금에 대한 정보는 MySQL 명령을 이용해 접근하기가 상당히 까다롭다.
하지만, 최근 버전에서는 InnoDB의 트랜잭션과 잠금 그리고 잠금 대기중인 트랜잭션의 목록을 조회할 수 있다. MySQL 서버의 information_schema 데이터베이스에 존재하는 INNODB_TRX, INNODB_LOCKS, INNODB_LOCK_WAITS 라는 테이블을 조인해서 조회하면 다음 작업들을 수행할 수 있다.
- 현재 어떤 트랜잭션이 어떤 잠금을 대기하고 있는지 확인
- 해당 잠금이 어느 트랜잭션을 가지고 있는지 확인
- 장시간 잠금을 가지고 있는 클라이언트를 찾아서 종료시키기
시간이 지남에 따라 InnoDB의 잠금에 대한 모니터링도 강화되어서 Performance Schema를 이용해 InnoDB 스토리지 엔진의 내부 잠금(세마포어)에 대한 모니터링 방법도 추가되었다.
3.1 InnoDB 스토리지 엔진의 잠금
InnoDB 스토리지 엔진의 잠금 정보는 상당히 작은 공간으로 관리되기 때문에 레코드 락이 페이지 락으로 또는 테이블 락으로 레벨업되는 경우(락 에스컬레이션)은 거의 없다.
일반 상용 DBMS와는 조금 다르게 InnoDB 스토리지 엔진에서는 레코드 락뿐 아니라 레코드와 레코드 사이의 간격을 잠그는 갭(GAP) 락이라는 것이 존재하는데, 그림 5.1은 InnoDB 스토리지 엔진의 레코드 락과 레코드 간의 간격을 잠그는 갭 락을 보여준다.
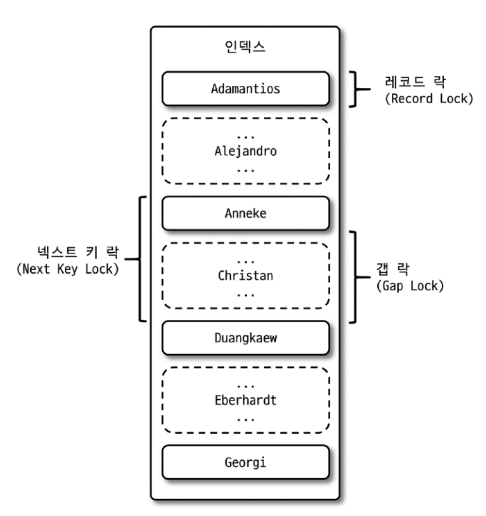
그림 5.1 InnoDB 잠금의 종류(점선의 레코드는 실제 존재하지 않는 레코드를 가정한 것)
3.1.1 레코드 락
레코드 자체만을 잠그는 것을 레코드 락(Record lock, Record only lock)이라고 하며, 다른 상용 DBMS의 레코드 락과 동일한 역할을 한다. 한 가지 중요한 차이는 InnoDB 스토리지 엔진은 레코드 자체가 아니라 인덱스의 레코드를 잠근다는 것이다. 인덱스가 하나도 없는 테이블이라 하더라도 내부적으로 자동으로 생성된 클러스터 인덱스를 사용하여 잠금을 설정한다.
InnoDB에서는 대부분 보조 인덱스를 이용한 변경 작업은 이어서 설명한 넥스트 키 락(Next key lock) 또는 갭 락(Gap lock)을 사용하지만 PK 또는 유니크 인덱스에 의한 변경 작업은 객(Gap, 간격)에 대해서는 잠그지 않고 레코드 자체에 대해서만 락을 건다.
3.1.2 갭 락
다른 DBMS와의 또 다른 차이점은 이 갭 락(Gap lock)이다. 이는 레코드 자체가 아닌 레코드와 바로 인접한 레코드 사이의 간격만을 잠그는 것을 의미한다.
사용 목적은 레코드와 레코드 사이의 새로운 레코드가 생성(INSERT)되는 것을 제어하기 위함이다.
이러한 갭 락은 그 자체보다는 이어서 설명할 넥스트 키 락의 일부로 사용된다.
3.1.3 넥스트 키 락
레코드 락과 갭 락을 합쳐 놓은 형태의 잠금이다.
STATEMENT 포맷의 바이너리 로그를 사용하는 MySQL 서버에서는 REPEATABLE READ 격리 수준을 사용해야 하며 innodb_locks_unsafe_for_binlog 시스템 변수가 비활성화(0으로 설정)되면 변경을 위해 검색하는 레코드에는 넥스트 키 락 방식으로 잠금이 걸린다.
InnoDB의 갭 락이나 넥스트 키 락은 로그에 기록되는 쿼리가 레플리카 서버에서 실행될 때 소스 서버에서 만들어 낸 결과와 동일한 결과를 만들어내도록 보장하는 것이 목적이다.
그런데, 이 둘로 인해 데드락이 발생하거나 다른 트랜잭션을 기다리게 하는 일이 자주 발생하므로 가능하면 바이너리 로그 포맷을 ROW 형태로 바꿔서 넥스트 키 락이나 갭 락을 줄이는 것이 좋다.
참고
MySQL 8.0 버전부터는 ROW 포맷의 바이너리 로그가 디폴트 설정이다.
3.1.4 자동 증가 락
AUTO_INCREMENT 컬럼이 사용된 테이블에 동시에 여러 레코드가 INSERT 되는 경우, 저장되는 각 레코드는 중복되지 않고 저장된 순서대로 증가하는 일련번호 값을 가져야 한다.
InnoDB 스토리지 엔진은 이를 위해 내부적으로 AUTO_INCREMENT 락(Auto increment lock)이라고 하는 테이블 수준의 잠금을 사용한다.
AUTO_INCREMENT 락은 INSERT와 REPLACE 쿼리 문장과 같이 새로운 레코드를 저장하는 쿼리에서만 필요하기에 UPDATE, DELETE 등의 다른 목적으로 사용되는 쿼리에는 잠금이 걸리지 않는다.
트랜잭션에 관계없이 INSERT 또는 REPLACE 쿼리 문장에서 AUTO_INCREMENT 값을 가져오는 순간만 락이 걸렸다가 해제된다.
AUTO_INCREMENT 락은 테이블에 단 하나만 존재하기 때문에 두 개의 INSERT 쿼리가 동시에 실행되는 경우 하나의 쿼리가 AUTO_INCREMENT 락을 걸면 나머지 쿼리는 AUTO_INCREMENT 락을 기다려야 한다. (AUTO_INCREMENT 컬럼에 명시적으로 값을 설정하더라도 자동 증가락을 걸게 된다.)
자동 증가 잠금을 명시적으로 획득 및 해제하는 방법은 없다. 아주 짧은 시간동안 걸렸다 해제되는 잠금이라 대부분의 경우 문제가 되지 않는다.
작동 방식은 innodb_autoinc_lock_mode 시스템 변수를 통해 변경할 수 있다. 자세한 내용은 MySQL 메뉴얼을 참조하자.
참고
자동증가 값이 한 번 증가하면 절대 줄어들지 않는데 이유는AUTO_INCREMENT잠금을 최소화기 위해서이다. 설령INSERT쿼리가 실패했더라도 한 번 증가된AUTO_INCREMENT값은 다시 줄어들지 않고 그대로 남는다.
참고
MySQL 바이너리 로그 포맷에 따라innodb_autoinc_lock_mode값은 다르게 설정해줘야 한다. 포맷에 따른 시스템 변수 값은 다음을 참고하자.
- ROW
innodb_autoinc_lock_mode= 2- STATEMENT
innodb_autoinc_lock_mode= 1MySQL 8.0버전 부터는 바이너리 포맷의 디폴트가 ROW이므로 이 시스템 변수 또한 디폴트 값이 2이다.
3.2 인덱스와 잠금
InnoDB의 잠금과 인덱스는 상당히 중요한 연관 관계가 있다는 것을 반드시 기억하자. 이전에 언급했듯 InnoDB의 잠금은 레코드가 아닌 인덱스를 잠그는 방식으로 처리된다. 즉, 변경해야 할 레코드를 찾기 위해 검색한 인덱스의 레코드를 모두 락을 걸어야 한다.
정확한 이해를 위해 다음 UPDATE 문장을 살펴보자.
-- 예제 데이터베이스의 employees 테이블에는 아래와 같이 first_name 컬럼만
-- 멤버로 담긴 ix_firstname이라는 인덱스가 준비되어 있다.
-- // Key ix_firstname (first_name)
-- employees 테이블에서 first_name='Georgi'인 사원은 전체 253명이 있으며,
-- first_name='Georgi' 이고 last_name='Klassen'인 사원은 딱 1명만 있는 것을
-- 아래 쿼리들로 확인할 수 있다.
mysql> SELECT COUNT(*) FROM employees WHERE first_name='Georgi';
=> 253이 출력된다.
mysql> SELECT COUNT(*) FROM employees WHERE first_name='Georgi' AND last_name='Klassen';
=> 1이 출력된다.
-- emloyees 테이블에 first_name='Georgi'이고 last_name='Klassen'인 사원의
-- 입사 일자를 오늘로 변경하는 쿼리를 실행해보자.
mysql> UPDATE employees SET hire_date=NOW() WHERE first_name='Georgi' AND last_name='Klassen';UPDATE 문장이 실행되면 1건의 레코드가 업데이트될 것이다. 하지만 이 1건의 업데이트를 위해 몇 개의 레코드에 락을 걸어야 할까?
이 UPDATE 문장에서 인덱스를 이용할 수 있는 조건은 first_name='Georgi' 이고, last_name 컬럼은 인덱스가 없기 때문에 총 253건의 레코드가 모두 잠긴다.
다음 그림 5.2는 UPDATE 문장이 어떻게 변경 대상 레코드를 검색하고, 실제 변경이 수행되는 지를 보여준다.
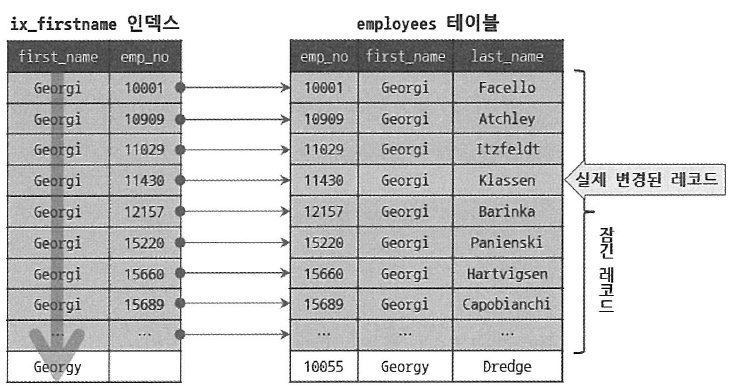
그림 5.2 업데이트를 위해 잠긴 레코드와 실제 업데이트된 레코드
이러한 부분을 잘 모르고 개발하면 MySQL 서버를 제대로 이용하지 못할 것이다. 이렇듯 적절히 인덱스가 준비되있지 않는 상태라면 각 클라이언트 간의 동시성이 상당히 떨어지는 문제가 발생한다.
3.3 레코드 수준의 잠금 확인 및 해제
InnoDB 스토리지 엔진을 사용하는 테이블의 레코드 수준 잠금은 테이블 수준의 잠금보다는 조금 더 복잡하다. 테이블 잠금에서는 잠금의 대상이 테이블 자체이므로 상대적으로 쉽게 문제의 원인이 발견되고 해결될 수 있다.
하지만, 레코드 수준의 잠금은 테이블의 레코드 각각에 잠금이 걸리므로 그 레코드가 자주 사용되지 않는다면 오랜 시간 동안 잠겨진 상태로 남아 있어도 잘 발견되지 않는다.
다행인건 MySQL 5.1버전 부터는 레코드 잠금과 잠금 대기에 대한 조회가 가능하므로 쿼리 하나만 실행해보면 잠금과 잠금 대기를 바로 확인할 수 있다.
4. MySQL의 격리 수준
트랜잭션의 격리 수준이란 여러 트랜잭션이 동시에 처리될 때 특정 트랜잭션이 다른 트랜잭션을 변경하거나 조회하는 데이터를 볼 수 있게 허용할지 말지를 결정하는 것이다.
격리 수준은 다음 4가지로 나뉜다.
- READ UNCOMMITTED(DIRTY READ)
- 일반적인 데이터베이스에서는 거의 사용되지 않는다.
- READ COMMITTED
- REPEATABLE READ
- SERIALIZABLE
- 동시성이 중요한 데이터베이스에서 거의 사용되지 않는다.
밑으로 갈수록 각 트랜잭션 간의 격리(고립)의 정도가 높아지며, 동시 처리 성능 또한 떨어진다. 그러나, 격리 수준이 높아진다고 MySQL 서버의 처리 성능이 많이 떨어지진 않는다. 사실 SERIALIZABLE 격리 수준이 아닌 이상 크게 성능의 개선이나 저하가 발생하진 않는다.
데이터베이스의 격리 수준을 이야기하면 항상 언급되는 다음 세 가지 부정합의 문제점이 있다. 이들은 격리 수준에 따라 발생할 수도 있고 않을 수도 있다.
- DIRTY READ
- NON-REPEATABLE READ
- PHANTOM READ
부정합에 대한 내용과 각 격리 수준에 대한 위 부정합의 문제점의 발생 유무는 각 격리 수준을 자세히 살펴볼 때 함께 보자.
참고
데이터 부정합 : 데이터가 연결되어있는 메모리 상에서 변경이 되는 경우 관련된 데이터들이 일괄적으로 값이 일치화 시키는 과정에서 데이터의 값이 다른 경우예) 잔액이 10,000원인 계좌에서 10,000원씩 3번 출금하는 경우
만약, 데이터 부정합이 발생하면 첫 번째 출금의 결과가 두 번째 출금에 반영이 되지 않아 잔액이 부족한 상태임에도 출금이 될 수 있다.
일반적인 온라인 서비스 용도의 데이터베이스는 READ COMMITTED와 REPEATABLE READ 중 하나를 사용한다. 오라클 같은 DBMS에서는 주로 READ COMMITTED 수준을 많이 사용하며, MySQL에서는 REPEATABLE READ를 주로 사용한다.
4.1 READ UNCOMMITTED
READ UNCOMMITTED 격리 수준에서는 아래 그림 5.3과 같이 각 트랜잭션의 변경 내용이 COMMIT 또는 ROLLBACK 여부에 상관없이 다른 트랜잭션에서 보인다. 아래 그림은 다른 트랜잭션이 사용자 B가 실행하는데 SELECT 쿼리의 결과에 어떤 영향을 미치는지 보여준다.
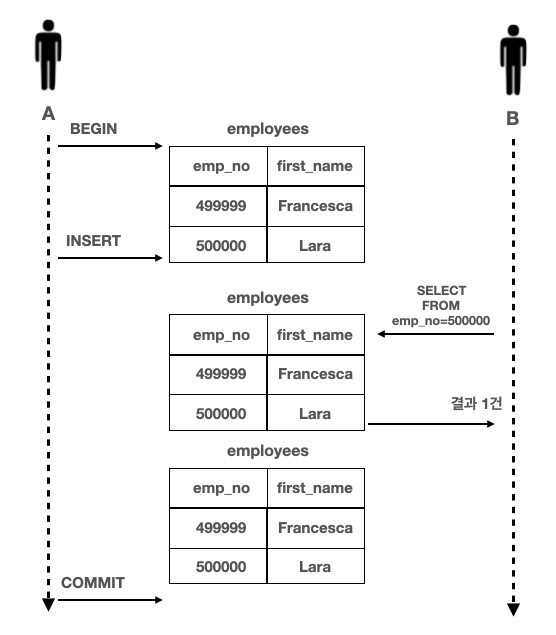
그림 5.3 READ UNCOMMITED
사용자 A는 emp_no가 500000이고 first_name이 "Lara"인 새로운 사원을 INSERT 한다.
사용자 B는 사용자 A가 변경된 내용을 커밋하기도 전에 emp_no=500000인 사원을 검색하고 있다.
이 때, 문제는 사용자 A가 처리 도중 알 수 없는 문제가 발생해 INSERT 된 내용을 ROLLBACK하려고 해도 여전히 사용자 B는 "Lara"가 정상적인 사원이라고 생각하고 계속 처리한다는 점이다.
이처럼 트랜잭션이 처리한 작업이 완료되지 않았는데도 다른 트랜잭션에서 볼 수 있는 현상을 더티 리드(Dirty read)라 하고, 이것이 허용되는 격리 수준이 바로 READ UNCOMMITTED 이다. 이러한 더티 리드 현상은 데이터가 나타났다가 사라졌다하는 현상을 초래하므로 어플리케이션 개발자와 사용자는 매우 혼란스러울 것이다.
또한, 더티 리드를 유발하는 READ UNCOMMITTED는 RDBMS 표준에서는 트랜잭션의 격리 수준으로 인정하지 않을 정도로 정합성에 문제가 많은 격리 수준이다.
따라서, MySQL을 사용한다면 최소한 READ COMMITTED 이상의 격리수준을 사용하자.
4.2 READ COMMITTED
READ COMMITED는 오라클 DBMS에서 기본적으로 사용되는 격리 수준일 만큼 온라인 서비스에서 가장 많이 선택되는 격리 수준이다.
여기서는 위에서 언급한 더티 리드(Dirty read)가 발생하지 않는데 어떤 트랜잭션에서 데이터를 변경했더라도 COMMIT이 완료된 데이터만 다른 트랜잭션에서 조회할 수 있기 때문이다.
아래 그림 5.4는 READ COMMITTED 격리 수준에서 사용자 A가 변경한 내용이 사용자 B에게 어떻게 조회되는지를 보여준다.
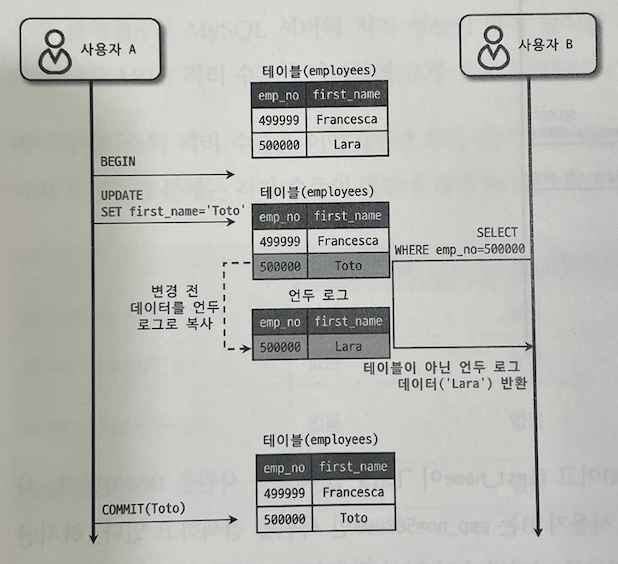
그림 5.4 READ COMMITTED
사용자 A는 emp_no=500000인 사원의 first_name을 "Lara"에서 "Toto"로 변경했는데, 이 때 새로운 값인 "Toto"는 employees 테이블에 즉시 기록되고 이전 값인 "Lara"는 언두 영역으로 백업 된다.
사용자 A가 커밋을 수행하기 전에 사용자 B가 emp_no=500000인 사원을 SELECT하면 조회된 결과의 first_name 컬럼 값은 "Toto"가 아닌 "Lara"로 조회된다. 여기서 "Lara"는 테이블이 아닌 언두 영역에 백업된 레코드에서 가져온 것이다.
READ COMITTED 격리 수준에서는 어떤 트랜잭션이 변경한 내용이 커밋되기 전까지는 다른 트랜잭션에서 그러한 변경내역을 조회할 수 없다. 최종적으로 사용자 A가 커밋을 하면 그 때부터 다른 트랜잭션에서 변경 사항을 사용할 수 있다.
이 격리 수준에서도 "NON-REPEATABLE"라는 부정합의 문제가 존재한다.(즉, "REPEATABLE READ"가 불가능) 다음 그림 5.5는 이 부정합의 문제가 왜 발생하고 어떤 문제를 야기하는지를 보여준다.
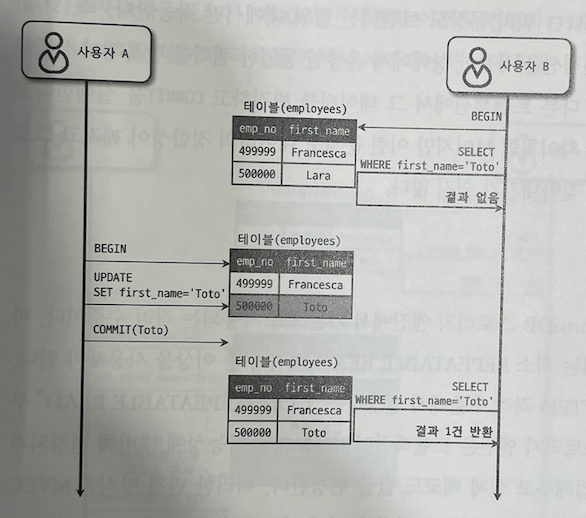
그림 5.4 NON-REPEATABLE READ
처음 사용자 B가 BEGIN 명령으로 트랜잭션을 시작하고 first_name이 "Toto"인 사용자를 검색했는데 일치하는 결과가 없었다.
하짐나, 사용자 A가 emp_no=500000인 사원의 이름을 "Toto"로 변경하고 커밋을 실행한 후, 사용자 B가 이전과 똑같은 SELECT 쿼리로 다시 조회하면 1건이 조회된다.
이는 별다른 문제가 없어보이지만, 사용자 B가 하나의 트랜잭션 내에서 똑같은 SELECT 쿼리를 실행했을 때 항상 동일한 결과를 가져와야 한다는 "REPEATABLE READ" 정합성에 어긋난다.
이러한 부정합 현상은 일반적인 웹 프로그램에서는 크게 문제되지 않을 수 있지만 하나의 트랜잭션에서 동일 데이터를 여러 번 읽고 변경하는 작업이 금전적인 처리와 연결된다면 큰 문제가 된다.
중요한 것은 사용 중인 트랜잭션의 격리 수준에 의해 실행하는 SQL 문장이 어떤 결과를 가져오는지를 정확히 예측할 수 있어야 한다. 이를 위해서는 당연히 각 트랜잭션의 격리 수준이 어떻게 작동하는지를 알아야 한다.
주의
가끔 사용자 중에서 트랜잭션 내에서 실행되는SELECT문장과 트랜잭션 없이 실행되는SELECT문장의 차이를 혼동하는 경우가 많다.
READ COMMITTED 격리 수준에서는 트랜잭션 내에서 실행되는SELECT문장과 트랜잭션 외부에서는 차이가 별로 없다.하지만, 바로 다음에 알아볼 REPEATABLE READ 격리 수준에서는 기본적으로
SELECT문장이 트랜잭션 범위 내에서만 작동하기 때문에 이를 혼동하여 데이터의 정합성이 깨지고 어플리케이션 버그가 발생하면 찾기 힘드므로 주의하자.
4.3 REPEATABLE READ
REPEATABLE READ는 MySQL의 InnoDB 스토리지 엔진에서 기본으로 사용되는 격리 수준이다. 바이너리 로그를 가진 MySQL 서버는 최초 REPEATABLE READ 격리 수준 이상을 사용해야 한다는 것을 기억하자.
이 격리 수준에서는 READ COMMITTED 격리 수준에서 발생하는 "NON-REPEATABLE" 부정합이 발생하지 않는다. InnoDB 스토리지 엔진은 트랜잭션이 ROLLBACK 될 가능성에 대비해 변경 전 레코드를 언두(Undo) 공간에 백업해두고 실제 레코드 값을 변경하는데 이를 MVCC라 한다. (이는 4.2.3절 MVCC를 참고하자)
또한, MVCC를 위해 언두 영역에 백업된 이전 데이터를 이용해 동일 트랜잭션 내에서 동일한 결과를 보여주는 것을 보장한다.
사실 READ COMMITTED도 MVCC를 이용해 COMMIT 되기 전의 데이터를 보여주는데, REPEATABLE READ와 차이는 백업된 레코드의 여러 버전들 가운데 몇 번째 전 버전까지 찾아 들어가느냐에 차이가 있다.
모든 InnoDB의 트랜잭션은 고유한 트랜잭션 번호(AUTO-INCREMENT)를 가지며, 언두 영역에 백업된 모든 레코드에는 변경을 발생시킨 트랜잭션의 번호가 포함되있다. 그리고, 언두 영역의 백업된 데이터는 InnoDB 스토리지 엔진이 불필요하다고 판단되는 시점에 주기적으로 삭제된다.
REPEATABLE READ 격리 수준에서는 MVCC를 보장하기 위해 실행중인 트랜잭션 가운데 가장 오래된 트랜잭션 번호보다 앞선 언두 영역의 데이터는 삭제할 수 없다. 그렇다고 가장 오래된 트랜잭션 번호 이전의 트랜잭션에 의해 변경된 모든 언두 데이터가 필요한 것은 아니다. 더 정확하게는 특정 트랜잭션 번호의 구간 내에서 백업된 언두 데이터가 보존되어야 한다.
다음 그림 5.6은 REPEATABLE READ 격리 수준이 작동하는 방식을 보여주는데 이 시나리오가 실행되기 전 employees 테이블은 번호가 6인 트랜잭션에 의해 INSERT 되었다고 가정하자. 시나리오는 사용자 A가 emp_no=500000인 사원의 이름을 변경하는 과정에서 사용자 B가 emp_no=500000인 사원을 SELECT할 때 어떤 과정을 거쳐 처리가 되는지를 보여준다.
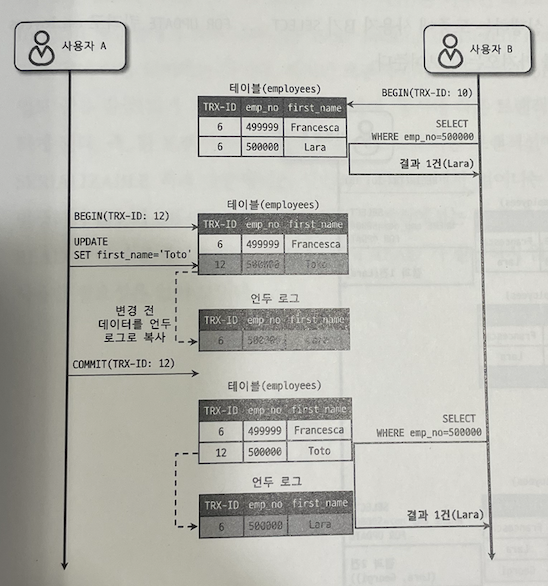
그림 5.6 REPEATABLE READ
사용자 A의 트랜잭션 번호는 12이고, B의 트랜잭션 번호는 10이다. 이 때, 사용자 A는 사원의 이름을 "Toto"로 변경 후 커밋을 수행했다.
그럼에도 불구하고 사용자 B가 emp_no=500000인 사원을 A 트랜잭션의 변경 전 후 각각 한 번씩 SELECT 했는데 결과는 항상 "Lara"라는 값을 가져온다.
사용자 B가 BEGIN 명령으로 트랜잭션을 시작하면서 10번이라는 트랜잭션 번호를 부여 받았는데, 그 때부터 사용자 B의 10번 트랜잭션 안에서 실행되는 모든 SELECT 쿼리는 트랜잭션 번호가 10(자신의 트랜잭션 번호)보다 작은 트랜잭션 번호에서 변경한 것만 보게 된다.
그림 5.6에서는 언두 영역에 백업된 데이터가 하나만 있는 것으로 표현했지만 사실 하나의 레코드에 대해 백업이 여러 개 존재할 수 있다. 한 사용자가 BEGIN으로 트랜잭션을 시작하고 장시간 트랜잭션을 종료하지 않으면 언두 영역이 백업된 데이터로 인해 매우 커질 수 있다. 이렇게 되면 MySQL 서버의 처리 성능은 떨어진다.
REPEATABLE 격리 수준에서도 다음과 같은 부정합이 발생할 수 있다. 다음 그림 5.7에서는 사용자 A가 employees 테이블에 INSERT 를 실행하는 도중에 사용자 A가 SELECT ... FROM FOR UPDATE 쿼리로 employee 테이블을 조회했을 때 어떤 결과를 가져오는지 보여준다.
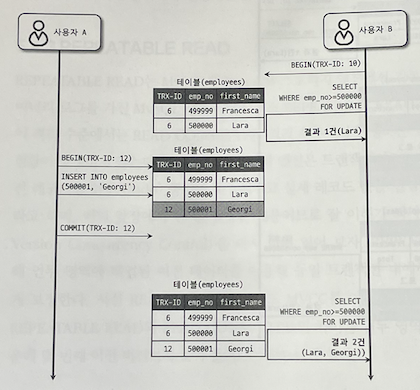
그림 5.7 PHANTOM READ(PHANTOM ROWS)
사용자 B는 BEGIN 명령으로 트랜잭션을 시작한 후 SELECT를 수행한다. 그러므로 그림 5.6의 REPEATABLE READ 처럼 두 번의 SELECT 쿼리 결과는 같아야 한다. 하지만 그림 5.7에서는 사용자 B가 실행하는 두 번의 SELECT ... FROM FOR UPDATE 의 결과는 서로 다르다.
이렇게 다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다가 안보였다 하는 현상을 PHANTOM READ(또는 PHANTOM ROW)라 한다.
SELECT ... FROM FOR UPDATE 쿼리는 SELECT 하는 레코드에 쓰기 잠금을 걸어야 하는데, 언두 레코드에는 잠금을 걸 수 없다. 그래서 SELECT ... FROM FOR UPDATE 또는 SELECT ... LOCK IN SHARE MODE로 조회되는 레코드는 언두 영역의 변경 전 데이터를 가져오는 것이 아닌 현재 레코드의 데이터를 가져오게 되는 것이다.
4.4 SERIALIZABLE
단순한 격리 수준임과 동시에 가장 엄격한 격리 수준이다. 그만큼 동시 처리 성능도 다른 트랜잭션 격리 수준에 비해 현저히 떨어진다.
InnoDB 테이블에서 기본적으로 순수한 SELECT 작업(INSERT ... SELECT ... 또는 CREATE TABLE ... AS SELECT ... 가 아닌)은 아무런 레코드 잠금도 설정하지 않고 실행된다.
하지만, 트랜잭션의 격리 수준이 SERIALIZABLE로 설정되면 이러한 간단한 작업 또한 공유 잠금(읽기 잠금)을 획득해야 하며, 동시에 다른 트랜잭션은 그러한 레코드를 변경하지 못하게 된다. 즉, 한 트랜잭션에서 읽고 쓰는 레코드를 다른 트랜잭션에서는 절대 접근할 수 없는 것이다.
덕분에 일반적인 DBMS에서 일어나는 "PHANTOM READ"라는 문제가 발생하진 않지만 InnoDB 스토리지 엔진은 갭 락과 넥스트 키 락 덕분에 REPEATABLE READ 격리 수준에서도 이미 "PHANTOM READ"가 발생하지 않기 때문에 굳이 이 격리 수준을 사용할 필요는 없어보인다.
