https://arxiv.org/pdf/1505.04597
Author: Olaf Ronneberger, Philipp Fischer, and Thomas Brox
Abstract
-
Data Augmentation을 활용하여 적은 갯수의 데이터로도 학습 가능한 네트워크 제안.
-
Contracting path(축소 경로) 와 Expanding path(확장 경로)로 구성된 U자형 구조.
-
512x512이미지를 1초 이내에 segmentation 가능.
Introduction
-
CNN을 활용한 모델들은 오랫동안 Visual recognition부문에서 SOTA를 차지하지만, training_set과 Network_size에 제한이 있다.
-
이후로 8개의 레이어와 수백만 개의 파라미터를 가진 큰 network가 생기고 ImageNet 데이터셋으로 학습되어 왔다.
-
CNN은 분류작업에 사용되며, 입력 이미지에 대한 출력은 단일 클래스 레이블이다. 그러나 의료 영상 처리 분야네는 많은 시각 작업에서 localization을 포함한 출력이 필요하다. 각 pixel 마다의 클래스 레이블이 요구되어야 한다.
-
이러 이유로 sliding-window 기법을 활용한 network가 patch(local region)을 활용하여 image segmentation을 예측하였다.
Sliding-window & Patch 기법의 단점
-
1. Quite Slow: 각 패치마다 네트워크를 개별적으로 실행해야 하므로 속도가 매우 느리다. 또한 패치가 겹치는 부분이 많아 중복이 발생한다.
-
Trade-off between localization accuracy and the use of context: 큰 패치는 Max-Pooling 레이어를 필요로 하여 localization accuracy(위치 정보의 정확도)가 떨어진다. 반면에 작은 패치는 localization accuracy가 높은 대신 네트워크 주변 context를 좁게 볼수 밖에 없다.
Network Architecture
-
본 논문에서는 FCN 논문의 기반으로 U자형 아키텍처를 설계했다.
-
이 아키텍처는 적은 학습이미지에도 작동하며, 정밀한 segmentation이 가능하게 하도록 구성되었다.

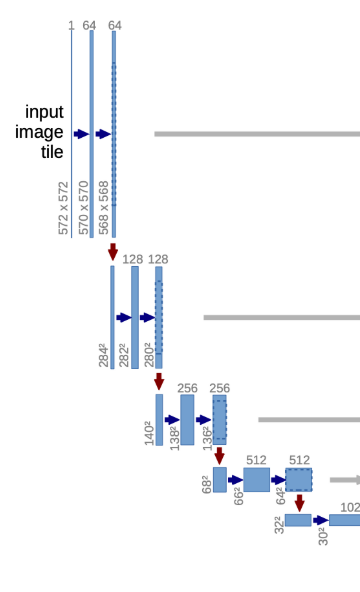
- U-net은 contracting path와 expanding path로 구성되어 있다. 이 2개의 과정을 통해 총 23개의 convolutional layer가 사용되고, 패딩을 사용하지 않기 때문에 output image는 input image보다 작아진다
Contracting path
-
점진적으로 넓은 범위의 이미지 픽셀을 보며 의미정보(Context Information)을 추출하는 수축 경로(Contracting Path).
-
전형적인 CNN구조이지만, fully connected layer를 사용하지 않고 위치 정보만 유지.
-
두 번의 3x3 convolution(unpadded) 수행 후 ReLU 활성화 함수 적용.
-
한 번의 2x2 max-pooling(stirde 2) downsampling을 할 때 마다 채널의 수가 2배로 늘어남(정보 손실 최소화, 복잡한 특징 학습 강화)
특징
-
해상도 감소 및 특징 채널 증가: 입력 이미지의 해상도는 절반으로 줄어지지만 학습된 특징 채널 수는 매 단계 2배로 증가 -> 네트워크가 더 많은 고차원 정보를 학습 가능.
-
context 정보 학습: DownSampling을 통해 더 큰 receptive field를 확보하여 더 넓은 context 정보를 인식 하지만 해상도가 줄어들면서 위치 정보는 점점 손실.
-
계층 구조: low-level특징부터 -> high-level특징까지 학습.
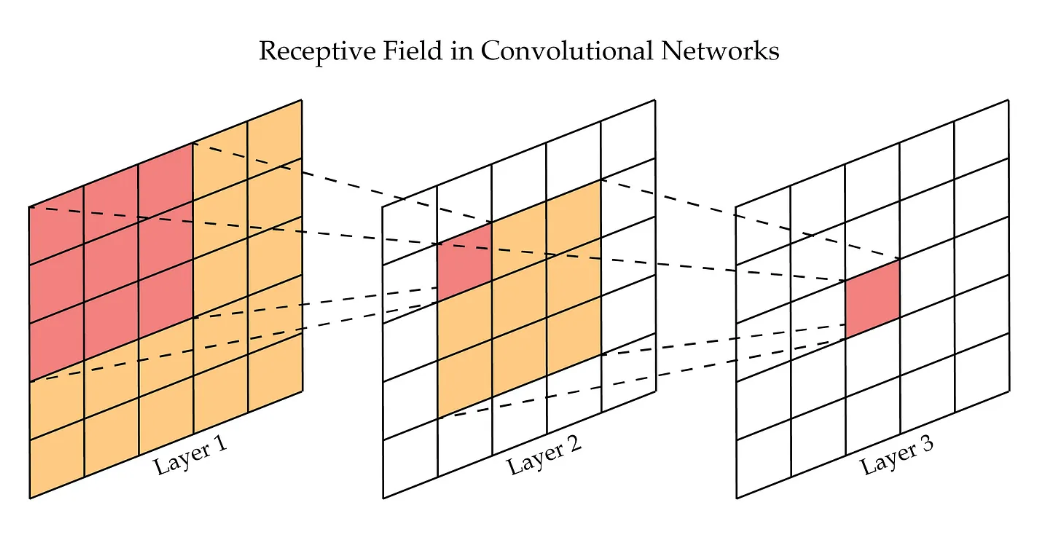
Receptive Field란: 신경망의 특정 뉴런이 입력 이미지에서 참조하는 영역의 크기를 의미
즉. CNN에서 합성곱 연산을 진행할 때, 특정 뉴런이 출력 값을 계산하기 위해 입력 이미지의 일부 영역을 봅니다. 이 "일부 영역"이 바로 Receptive Field
Expanding path
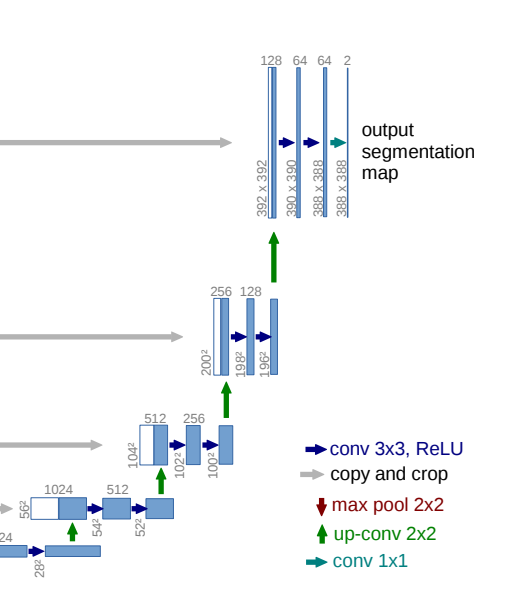
-
업샘플링을 통해 해상도를 복원하고, 세밀한 위치 정보를 결합하여 최종적으로 픽셀 단위 분류를 수행하는 부분
-
Contracting path에서 학습한 고수준 특징 맵을 업샘플링해 복구합니다.
-
업샘플링된 출력과 Contracting path에서 대응되는 고해상도 특징맵을 연결
-
연결을 통해 정확한 위치 정보를 복구하고, 세부적인 정보를 보존.
-
단순 업샘플링만 하면 해상도는 복원되지만, 세밀한 경계정보가 손실되기 때문에, Skip Connection이 중요.
-
연결된 특징맵에 대해 두 번의 3x3합성곱을 적용하고 각각 ReLU활성화 함수를 적용.
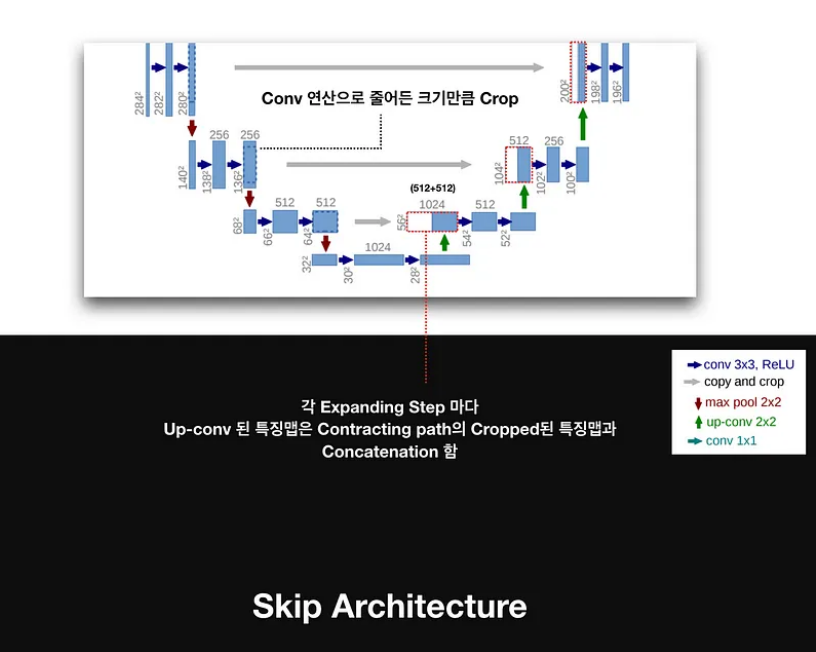
Skip Connection란: 신경망의 특정 레이어의 출력을 이후 레이어에 직접 연결하는 구조.
U-Net에서의 Skip 연결 구조는 Contracting path의 각 단계는 업샘플링된 출력과 대응되는 해상도로 잘려져서 연결하므로 업샘플링 시 발생하는 해상도 손실을 보완하고, 정확한 경계선 복원.
Skip Connection 과 Crop 기법의 관계:
Contracting path에서 padding이 없어 연산마다 출력 크기가 줄어들기 때문에 Skip Connection을 적용할 때 발생하는 문제를 해결하기 위해 사용.
출처: https://medium.com/@msmapark2/u-net-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-u-net-convolutional-networks-for-biomedical-image-segmentation-456d6901b28a
추가 언급된 기법(전략)
Data Augmentation
-
U-Net에서는 주석된 의료 데이터의 양이 매우 적은 문제를 해결
-
데이터 증강은 학습 데이터셋에 변형을 적용하여 새로운 데이터를 생성
-
탄성 변형: 조직이나 세포는 모양이 자유롭게 변형될 수 있기 때문에, 이미지를 랜덤하게 비틀거나 휘어지게 변형.
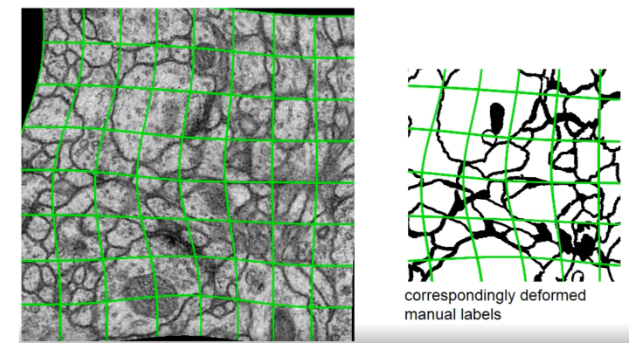
출처: https://wikidocs.net/148870
- Overfitting 방지 및 다양한 상황에 대한 학습 가능
Overlap-Tile-Strategy
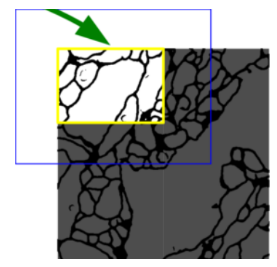
출처: https://wikidocs.net/148870
-
U-Net의 구조를 보면 388×388 크기의 Segmentation map을 얻기 위해 572×572 크기의 Input image가 필요합니다.
-
위 그림에서 파란색 patch를 Input image로 제시하면 노란색 영역의 Segmentation map이 출력되는 것입니다.
-
이미지 크기가 줄어들어 나오는 이유는 U-Net에서 padding 없이 Convolution 연산을 반복적으로 수행했기 때문입니다.
-
이 같은 missing data 문제를 해결하기 위해 사용한 것이 mirroring extrapolation 입니다.
-
파란색 박스의 빈 공간을 노란색 영역이 거울에 반사된 형태로 채우는 방식.

출처: https://wikidocs.net/148870
-
해당 영역을 zero pixel로 채울 수도 있었겠지만 mirroring extrapolation을 하면서 data augmentation의 효과를 줄 수 있다
-
좌우대칭을해도 큰 영향이 없는 세포등의 의학 데이터에서는 zero padding 보다 나은 방법.
Weighted Loss Function
-
의료 영상 segmentaion에서는 같은 클래스에 속하는 객체들이 서로 밀착되거나 접촉하는 경우가 많다.
-
접촉된 객체들의 경계를 구분하는 데 어려움을 겪는다.
-
이를 해결하기 위해, 경계 부분의 손실에 더 큰 가중치를 부여하는 가중 손실 함수를 사용한다.
-
접촉하는 세포나 조직 사이의 경계선 픽셀에 높은 가중치를 부여하여, 경계선이 잘 학습되도록 유도한다.
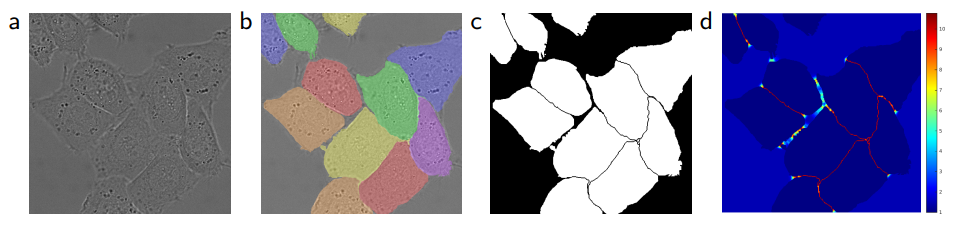
Training
-
네트워크의 출력 값은 픽셀 단위의 Softmax로 예측된다.
-
SGD(Stochastic Gradient Descent, 확률적 경사 하강법) 사용하여 모델 최적화
-
GPU Memory 사용 극대화를 위해 이미지를 타일로 분할(Tiling)하여 mini-batch로 구성한 뒤 모델에 입력
-
Momentum 0.99 설정하여 이전 Training Sample에서 본 것들이 현재 Optimization Step에 영항을 많이 주도록 한다.
Pytorch 구현: https://github.com/namduhus/U-Net
Pytorch: 2.5.0
IDE: Pycharm
