1. 머신러닝이란?
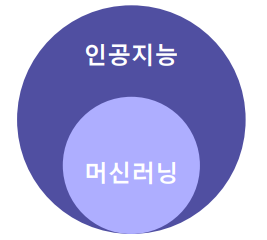
1. 인공지능 (Artificial Intelligence; AI)
- 지능을 갖고 있는 기능을 갖춘 컴퓨터 시스템
- 인간의 지능을 기계 등에 인공적으로 구현한 것. 예) 컴퓨터

2. 머신러닝(Machine Learning; ML)
- 경험을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구
- 자동으로 개선하는 컴퓨터 알고리즘의 연구임
- 훈련 데이터를 통해 학습해 경험을 쌓아 예측하는 방법
3. ML Pipeline
- 데이터 - 알고리즘(모델) - 학습/예측
- 전문가의 개입 없이 기계가 자동으로 학습함.
- 응용 : 의료 , 법률, 주식 ...
2. 머신러닝을 위한 수학
머신러닝을 data속의 representation을 기계가 학습을 하는 것
data는 대부분 고차원(high dimensio)이다. 즉, vector와 matrix로 구성되어 있다.\

의료 데이터를 예시로 들어보면,
병원은 환자 A에 대한 정보를 “성별, 나이, 몸무게, 키, 심장질환 유무”로 저장한다고
하자. 그렇다면?
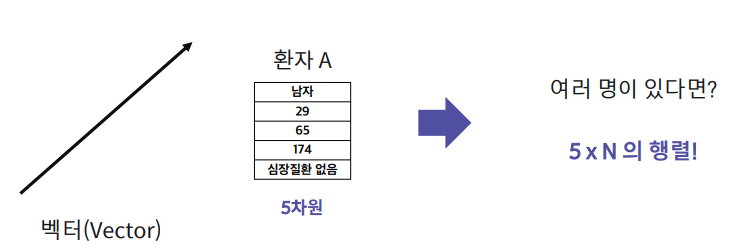
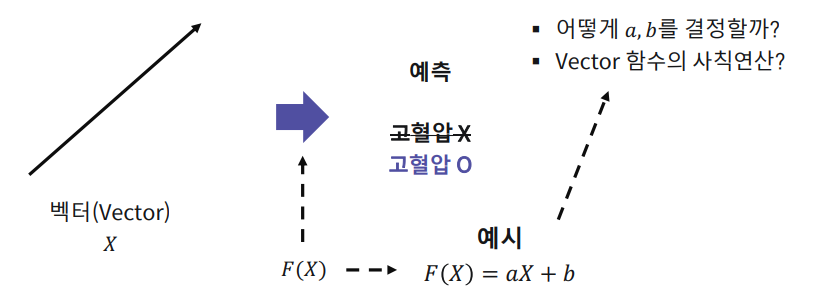
ML 알고리즘은 고차원 데이터의 표현을 학습 목적에 맞게 뽑아내는 함수를 학습한다.
3. 벡터의 정의와 의미
3-1. 벡터(Vector)
- 정의 : 크기(Scale)과 방향(Direction)을 가진 물리량
- 일련의 숫자 리스트(list)
- 예시 : 고차원에서의 좌표
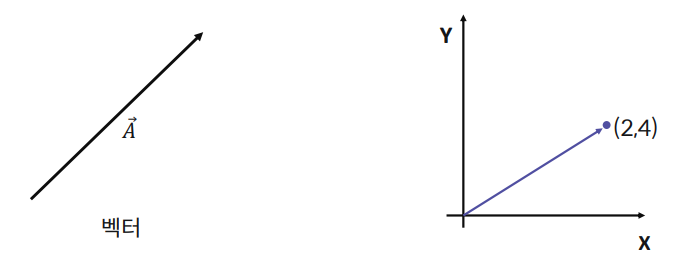


4. 벡터 연산, 단위 벡터, 직교성


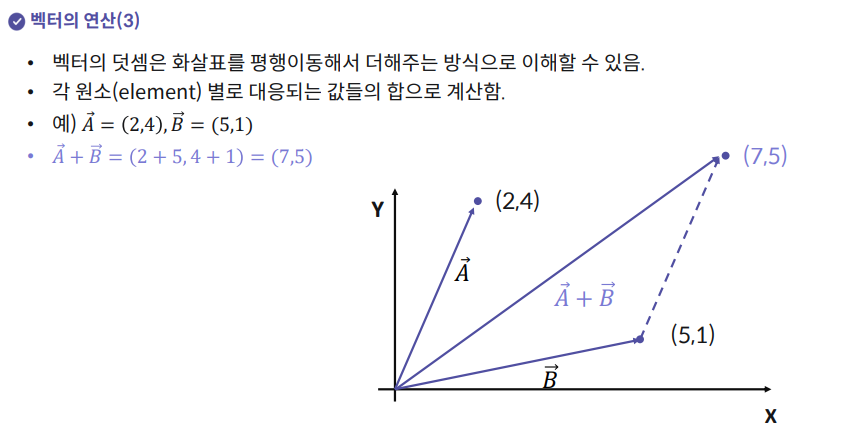
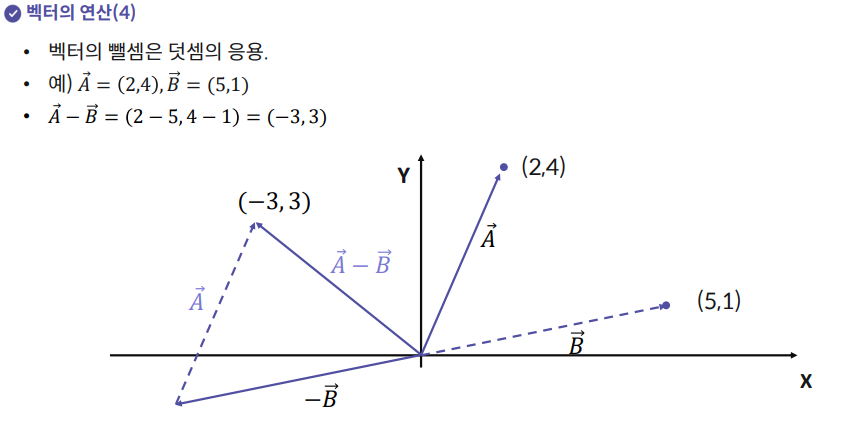

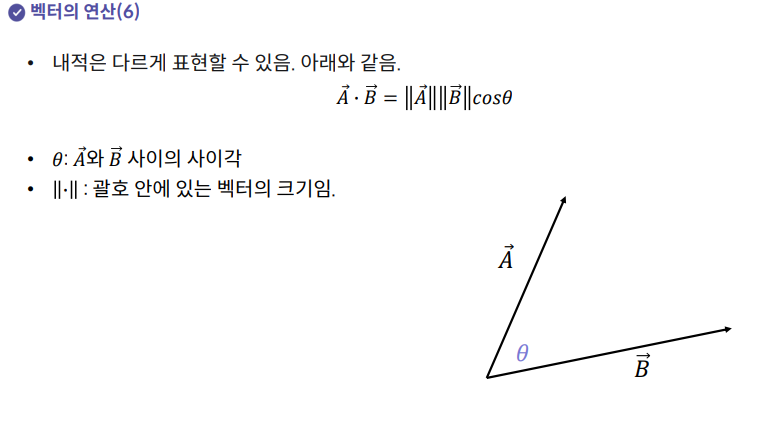


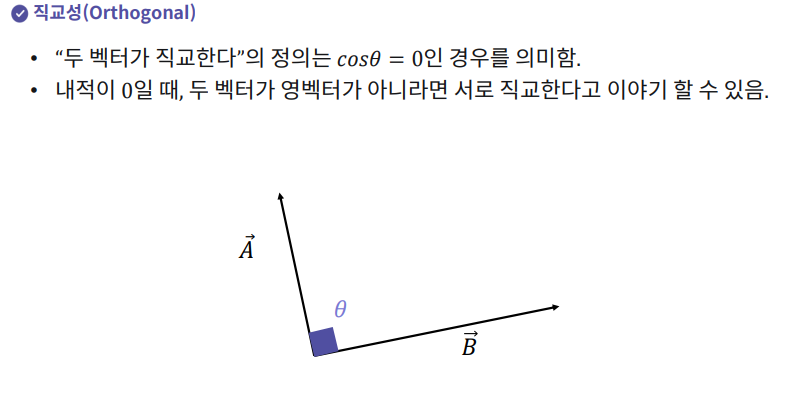

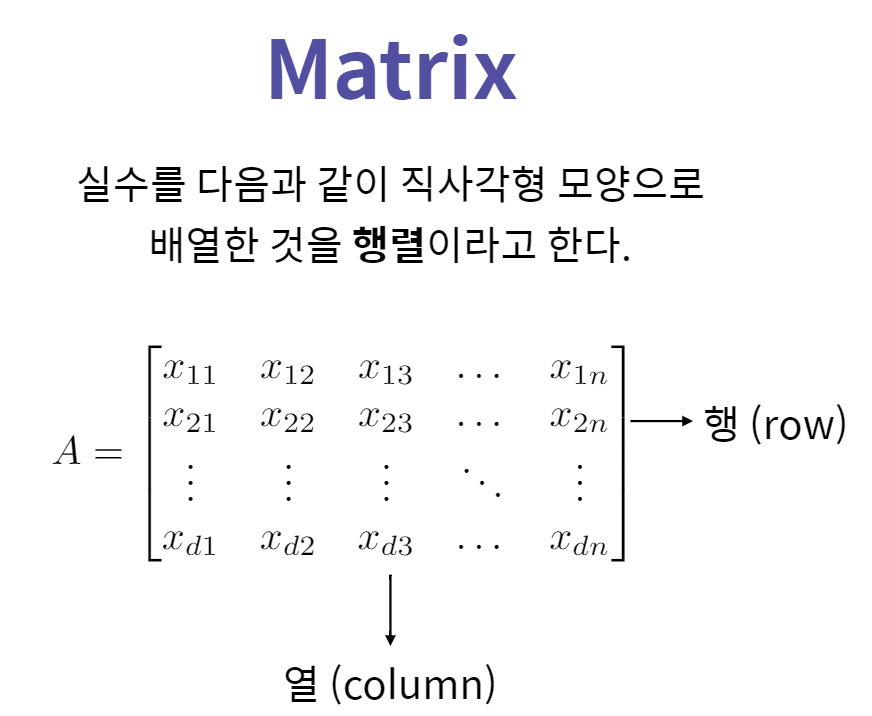
5. 행렬의 정의와 의미

6. 행렬 연산과 역행렬






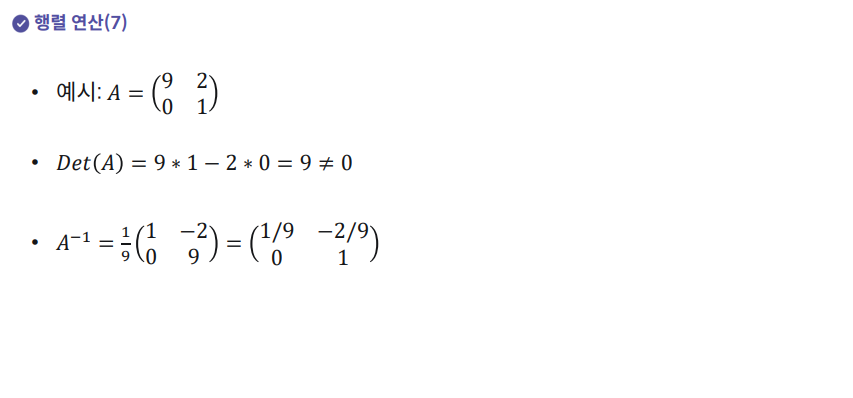
6-1. Norm

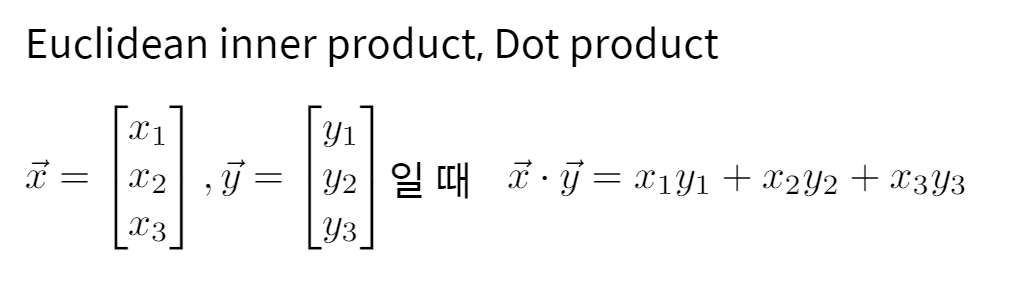
6-2. 내적(Euclidean inner product, Dot product)
여기 공부할 때 딥러닝 논문 스터디때 내가 얼마나 무지했느냐를... 알게됐다는...부끄러운..순간이었다. 왜 고등학교때 공부한 걸 다 까먹은거지?ㅎ
6-3. Matrix
6-4. 전치행렬(Transpose)

7. 실습
7-1. Numpy 벡터 연산하기
벡터 함수의 크기(scale) : np.linalg.norm(data)
def main():
data = [1,2,3]
print(calculate_norm(data))
print(unit_vector(data))
#함수 안에 주어진 데이터 data의 크기(scale) 값을 출력하는 함수
def calculate_norm(data):
return np.linalg.norm(data)
#함수 입력으로 주어진 data 벡터를 단위 벡터(unit vector)로 바꾸어 출력
def unit_vector(data):
return np.array(data) / np.linalg.norm(data)
if __name__ == "__main__":
main()
7-2. Numpy 행렬 연산하기
- 랜덤 행렬 함수
- 크기가 (3,3)인 랜덤 행렬 출력 코드
- np.random.random((3,3))
- 행렬 A의 최대값 = A.max() , 행렬 A의 최소값 : A.min()
지시사항: 함수 안에서 먼저 (5,5)의 랜덤 행렬을 선언하세요.그리고 선언한 행렬의 최대값과 최소값을 기억하고, 이것을 통해 선언했던 랜덤 행렬을 normalize하세요.
def main():
print(normalize())
def normalize():
Z = np.random.random((5,5))
Zmax, Zmin = Z.max(), Z.min()
Z = (Z-Zmin)/(Zmax-Zmin)
return Z
if __name__ == "__main__":
main()
7-3. Numpy 행렬 곱 함수 만들기
[지시사항]
함수 안에 먼저 1으로 채워진 행렬 2개를 선언합니다.
하나는 (5,3)의 크기, 다른 하나는 (3,2)로 합니다. 그리고 앞서 선언한 두 행렬의 곱을 합니다.
def main():
print(multiply())
def multiply():
A = np.ones((5,3)) #1의 값으로만 채워진 (5,3)의 행렬 선언
B = np.ones((3,2))
Z = np.dot(A, B) #두 행렬의 곱
return Z
if __name__ == "__main__":
main()

AI researcher를 꿈꾸는 간호사입니다 :)