abstract
- Objective : Solving the problem of ambiguity
- 하나의 뉴런이 여러개의 의미로 구분되는 상황
- 인간이 신경망 내부를 이해하기 어렵게 만든다
- Solution : Sparse encoder를 통해, 인코딩되는 과정에서 활성화되는 뉴런 수를 제한 → 많은 뉴런이 동시에 활성화되지 않도록
Introduction
- AI의 발전으로 인간이 이해하기 어려운 결정 과정을 가진 AI 시스템이 개발되고 있음
- 시스템의 불투명성 ⇒ 신뢰성, 안전성에 대한 우려 발생
- 신경망 이해/해석의 주요 장애물 → polymorphism : 개별적인 뉴런이 여러 의미로 활성화되는 현상
- 원인 : Superposition
- 신경망이 개별 뉴련이 표현할 수 있는 것보다 더 많은 특징을 표현하는 현상
- 하나의 뉴런이 여러가지 특징을 동시에 표현하려고 시도, 고차원공간에서 여러 방향성을 갖게 됨
- 원인 : Superposition
- Sparse autoencoder를 통해, polysemanticity를 줄이고 interpretability를 강화하고자 함
TAKING FEATURES OUT OF SUPERPOSITION WITH SPARSE DICTIONARY LEARNING
-
Feature dictionary : 신경망이 input data를 표현하기 위해 사용하는 특징들의 모음
-
소수의 뉴런들이 특정 패턴을 나타내도록 선형적으로 조합
- 독립적인 방향을 갖도록 reconstruct하여 하나의 뉴런이 여러 의미를 동시에 갖지 않도록 함
- activation space를 개별적인 특징으로 분해한 feature dictionary를 통해 모델의 내부 동작을 더 잘 이해할 수 있음
- 뉴런 → 하나의 특징만을 가짐
- 특징 → 하나의 의미 또는 역할을 가짐
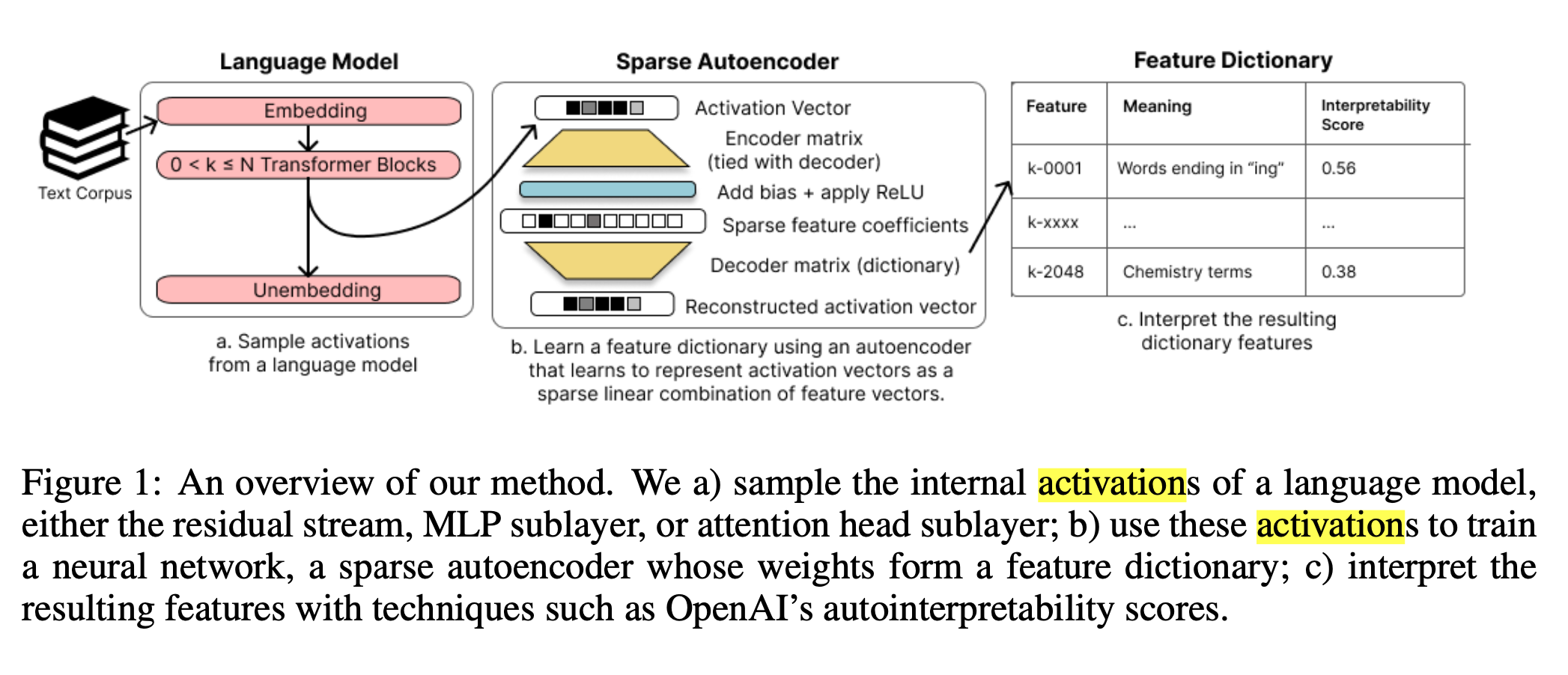

- → 중요한 feature만을 강조하는 벡터들의 집합, 가 특정 feature를 얼마나 강하게 표현하는지는 나타냄
- → 하나의 의미만을 가지는 뉴런(벡터) 집합
- Reconstruction loss : 원본 벡터와 reconstruct 벡터 간의 차이를 최소화
- Sparsity loss : 위에서 구한 의 요소들이 0이 되도록 유도 → 중요한 요소만 activate 되게끔 하기 위함
INTERPRETING DICTIONARY FEATURES
- https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html 에서 제안한 자동화된 해석 가능성 측정 방식을 활용

- LLM을 이용하여 각 feature에 대해 사람이 읽을 수 있는 설명을 생성, 이 설명을 통해 다른 text sample에서의 feature activation을 예측
- 예측한 activation ↔ 실제 activation 간의 관계를 통해 각 feature의 interpertability score 반환
- score가 높을수록, 해당 뉴런이 특정 상황에서 일관되게 활성화됨을 확인

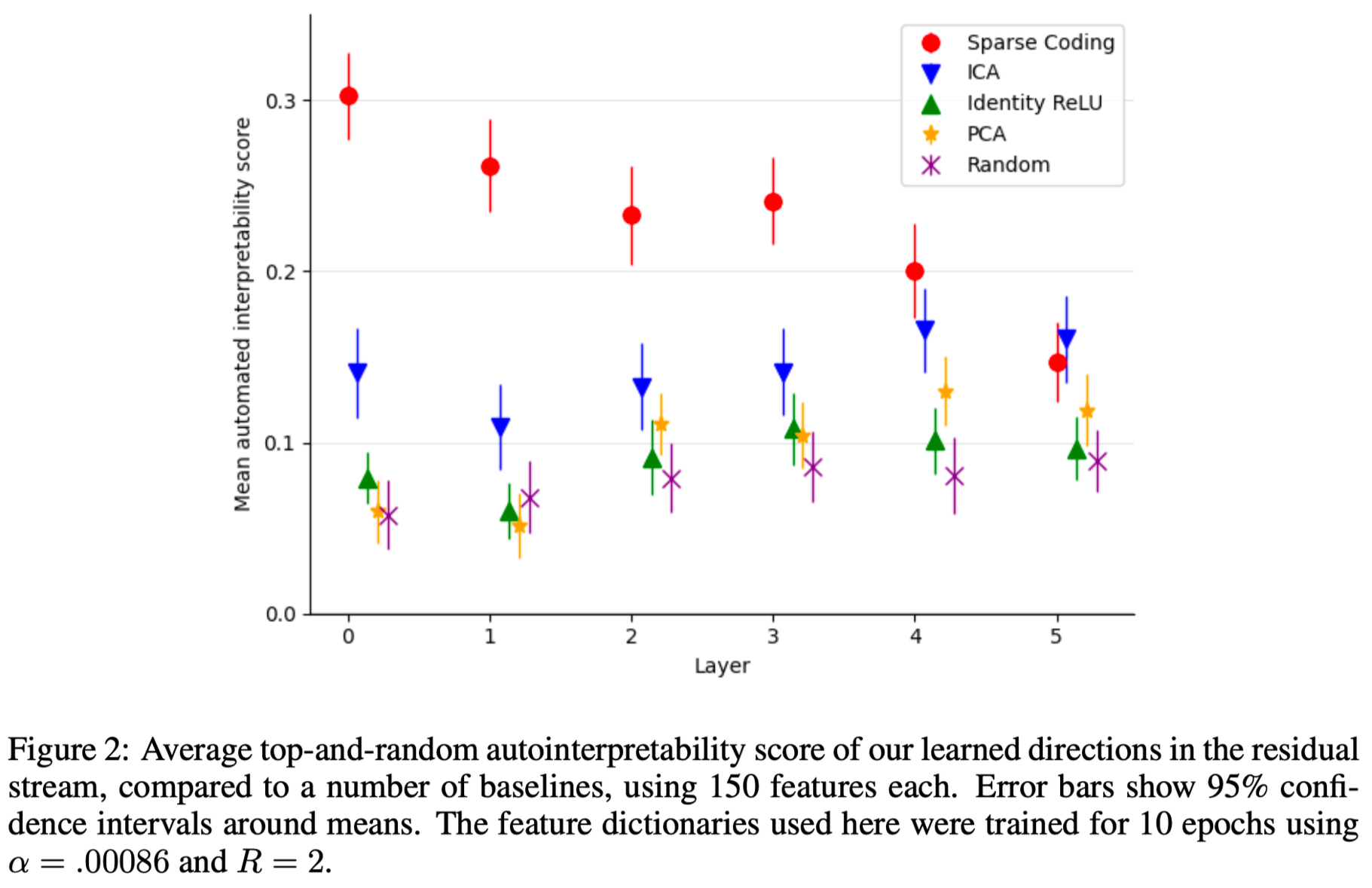
-
Sparse coding이 초기 레이어에 대해 특징을 명확하게 분리하고 이해하는 성능을 보여줌
-
하지만, 후반부 레이어로 갈 수록 특징이 복잡해지기 때문에 성능이 떨어진다고 할 수 있음
-
GPT가 인간이 생성한 설명과 매우 비슷한 설명을 생성할 수 있음을 보여줌
-
하지만, LLM이 찾을 수 있는 패턴은 제한되어 있고, 다음 혹은 이전 token을 중심으로 하는 패턴을 찾아내는데 어려움을 겪음
-
스스로 평가하고 검증하는 능력이 부족함
IDENTIFYING CAUSALLY-IMPORTANT DICTIONARY FEATURES FOR INDIRECT OBJECT IDENTIFICATION
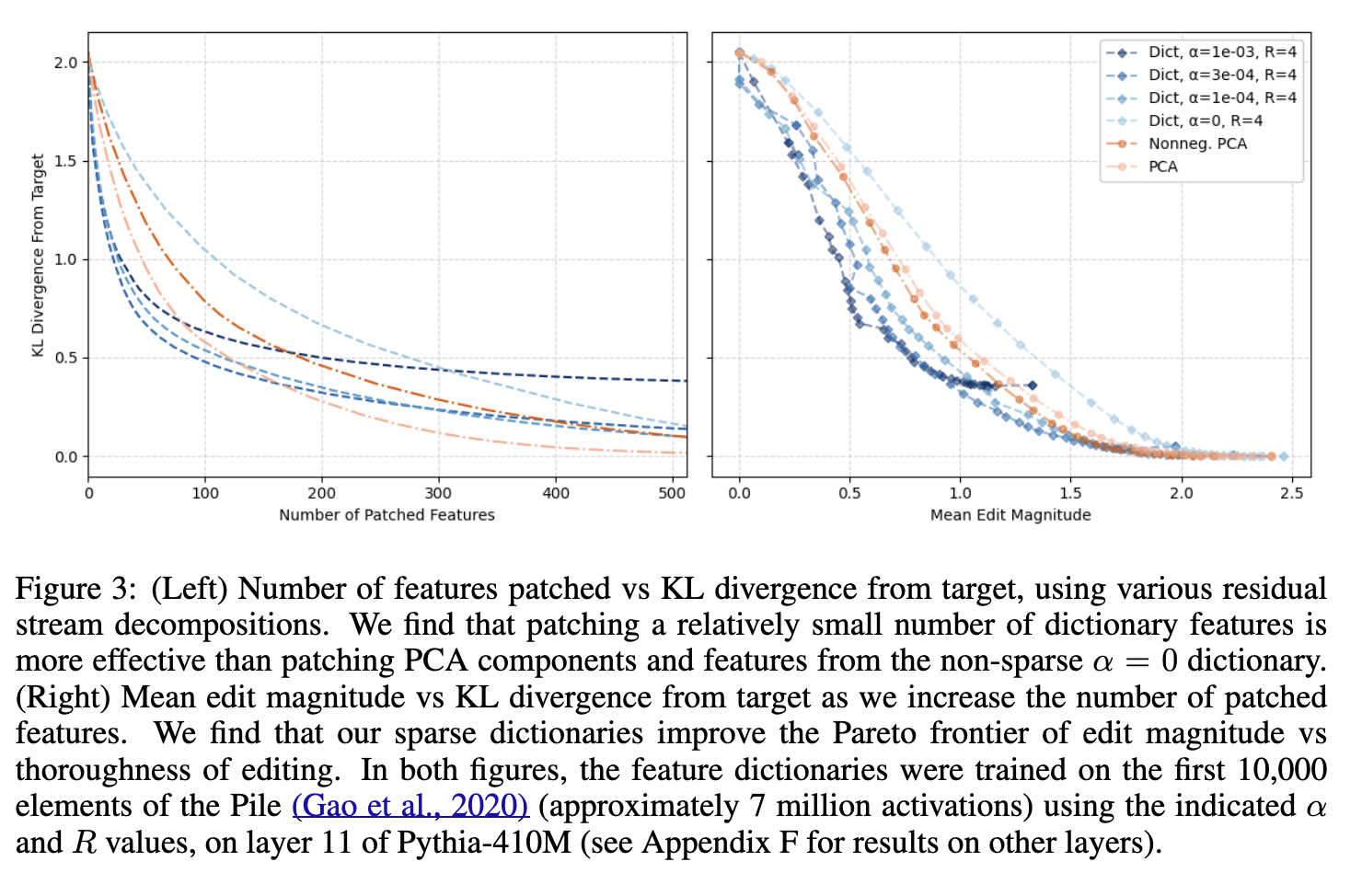
- IOI (Indirect Object Identification) 작업 중 모델 동작을 분석하기 위해 causal mediation analysis를 수행함
- 원본 문장에서 간접 목적어를 변경 → (대체 문장 생성)
- 대체 문장에 대해 model을 적용하여 feature의 activation value 저장
- 다시 원본 문장에 대해 model을 적용하되, 앞서 구한 activation value에 맞추어 feature 수정
- feature 수정은 ACDC(Automated Circuit Discovery) 알고리즘을 기반으로 함
- 수정된 feature를 기반으로, 다시 간접목적어 식별 수행 → 얼마만큼의 수정이 이루어졌을 때 대체 문장에 가까운 답을 내는지를 확인 (KL divergence)
- : 수정된 모델에 기본 문장을 입력했을 때의 output
- : 기본 모델에 대체 문장을 입력했을 때의 output
- 특정 레이어에서 학습된 feature를 편집 → 출력 변화를 측정하여 feature가 모델이 동작하는데 미치는 영향을 평가
- Sparse feature dictionary PCA : 더 적은 수정으로 원하는 출력에 도달할 수 있음
Case Studies
-
Analysis of Individual Features
-
input : 특정 특징이 어떤 토큰과 컨텍스트에서 활성화되는지를 분석하여 해당 특징의 의미를 이해
-
output : 특징을 제거하거나 수정하면서 모델의 출력 로짓에 어떤 변화가 발생하는지를 관찰 + feature의 역할, 영향 이해
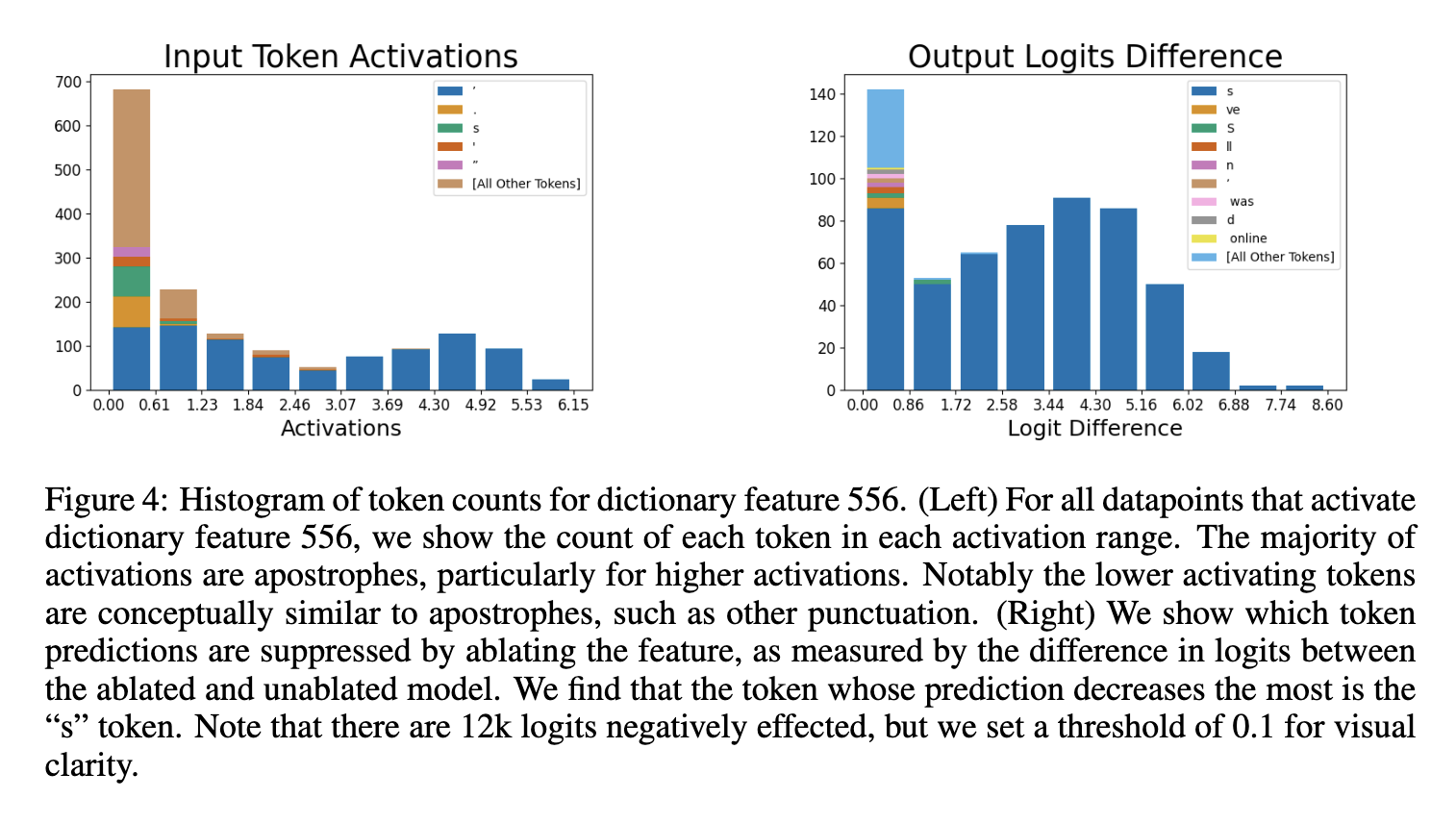
- (left) x축: 특정 token이 입력되었을 때 feature가 얼마나 activate 되는지, y축: token 등장 횟수
- [ ‘ ] 가 높은 활성화를 유발한다는 것을 보아, 556 feature는 [ ‘ ] 와 관련된 토큰에 반응함
- (right) x축: feature 제거후 logit 값의 차이, y축: 범위에 해당하는 토큰 개수 해당 특징이 제거되었을 때 ‘s’ token 예측 확률이 크게 감소 → 토큰 예측에 중요한 역할을 하는 feature임을 알 수 있음
- (left) x축: 특정 token이 입력되었을 때 feature가 얼마나 activate 되는지, y축: token 등장 횟수
-
Inter-Feature Relationship : 특정 특징이 이전 및 이후 레이어의 어떤 특징들과 연관되어 있는지를 탐색 + feature 간의 인과관계 파악
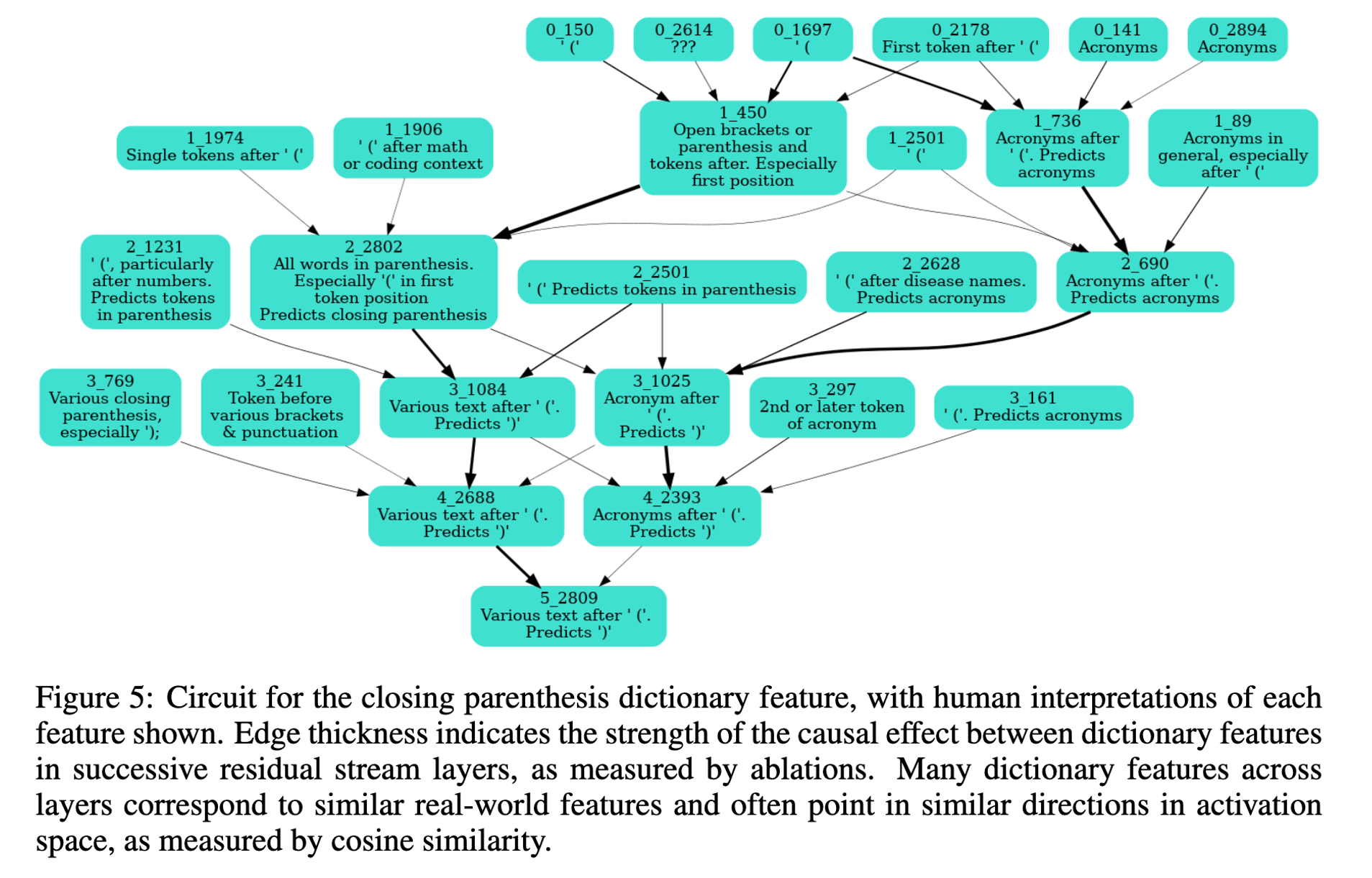
-
박스 : 특징, 특정 상황에서 각 특징들이 어떤 의미를 갖게 되는지 설명
-
Discussion
- Related work
- 기존 : 훈련 중에 데이터를 학습 + 가중치를 최적화. 이 과정에서 sparsity를 넣으려면 훈련 과정 자체를 변경하거나 특별한 제약을 추가해야 함
- 본 연구 : 모델이 완전히 훈련된 후, 훈련된 가중치나 뉴런의 활성화 값들을 분석하여 불필요한 부분을 제거하거나 특정 뉴런만 활성화되도록 하는 방법을 사용함
- Limitation & Future work
- layer 간의 정보 손실이 발생 → 다른 유형의 autoencoder 사용 / 훈련 과정에서의 조정 고려
- residual stream 이외의 다른 아키텍쳐에 대한 적용 어려움
- Transformer의 MLP에 적용한 결과 : interpretability가 높은 feature도 발견할 수 있었지만, dead features 라는 문제가 발생 → 추가 연구 필요
- conclusion
- Sparse autoencoder를 활용하여 superposition 문제를 해결할 수 있고, 모델의 interpretability를 향상시킬 수 있음
- 학습된 feature는 더 해석하기 쉽고, monosemantic하기 때문에 모델이 동작하는 데 있어 세밀하게 분석하고 조정할 수 있음
