
학부 과정에서 배웠던 내용을 전체적으로 정리할 수 있어서 너무 좋은 수업이었다..
새삼 갓영준.. 교수님이 가르쳐주신거 다 나옴
기억이 새록새록이다 .. 🙂↕️
ML
화이트보딩
-
기존 프로그래밍 방식
{input & 프로그램} ⇒ 컴퓨터 ⇒ output
-
머신러닝
{input&output} ⇒ 알고리즘 ⇒ model(프로그램)
: data driven method
-
모델의 목적 : 일반화된 프로그램을 만드는 것
model
와 값의 저장, input 값에 대해 output 값이 정확히 나오도록 와 값을 찾아나가는 과정
파라미터( 와 )를 어떻게 조절해야, 우리가 output이라고 하는 값과 가장 가까운 값이 나올 것인가
-
Loss function : 예측값과 실제값과의 차이
차이가 너무 많이 나면 ⇒ 다시 돌려보내서 최적화를 통해 업데이트
이 과정을 반복하면서, 그 차이가 가장 적게 나는 순간을 찾아내는 것이 ⇒ training
Supervised learning
답이 있는 것 (레이블이 있는 데이터를 쓴다)
- 분류
- 회귀 : 데이터가 연속적으로 가는 경우
- 하지만, 답은 있다. → ex. 2020년엔 1억, 2021년에 2억 … 등
Unsupervised learning
레이블이 없는 데이터를 쓴다 (특징을 가지고 나눠준다고 생각하면 된다)
- 클러스터링
Reinforcement learning
환경 값을 제공하고, 정답을 반환할 때 보상을 줌 (reward)
→ reward가 최대가 되는 길이 최적의 길이 되는 것
주요 용어
parameter
- weight : 가중치, 각기 다른 비중으로 데이터의 중요도를 부여
- bias : 편향, 가중치합 이후에 더해지는 방식 (아무것도 안해도 base로 깔리는 값 or 조정해주는 값)
hyper-parameter
- learning rate : 가중치값을 얼마나 업데이트 할 지 결정하는 파라미터
- epoch : 전체 학습 데이터를 모델 한번 학습
- batch size : 데이터를 특정 크기만큼 잘라서 학습
예를 들어, 10000개 데이터가 있다고 할 때 batch size = 1000 10번 돌아가서 → 전체 10000개가 한번 돌면 ⇒ epoch 1 -
PPT
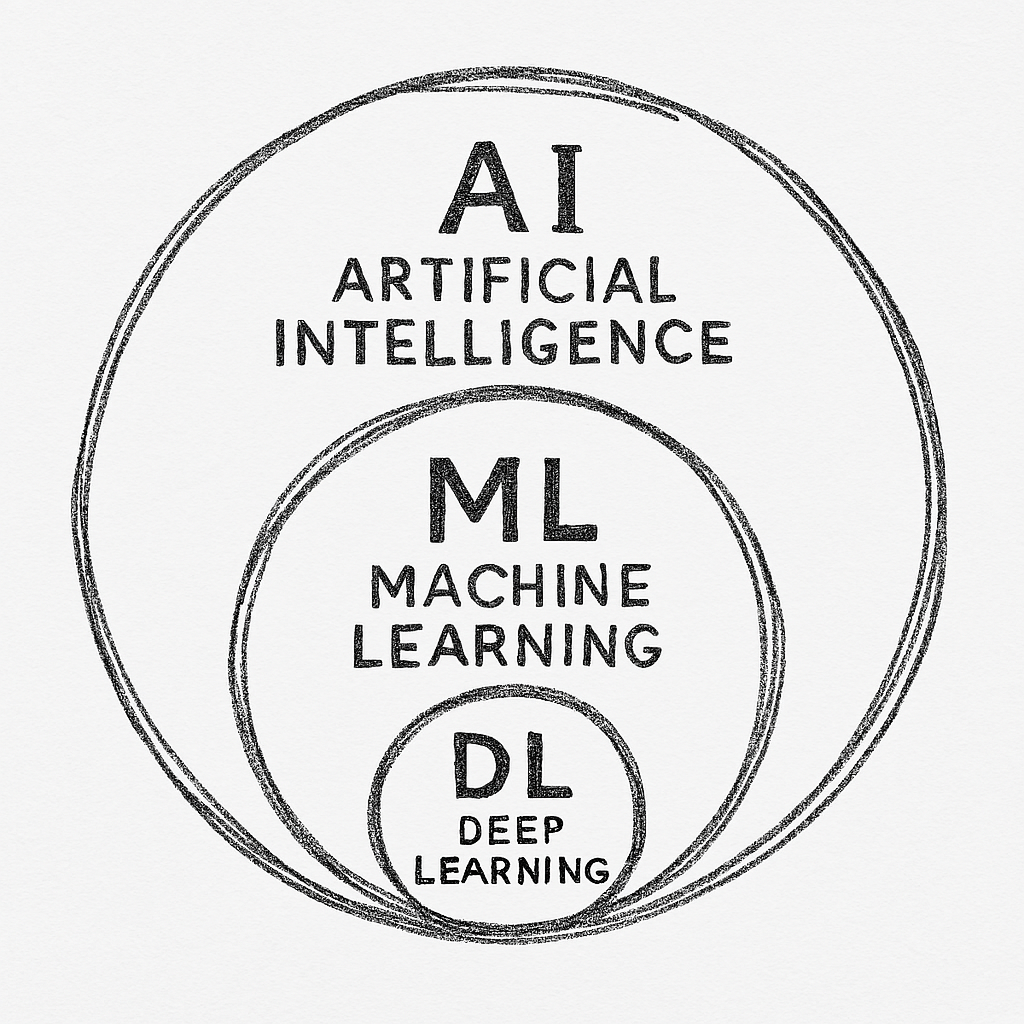
딥러닝 안에, generative AI가 있다
파이프라인
1. 데이터 처리
- 수집 + 정제
2. 훈련
3. 평가
4. 추론AI/ML을 위한 AWS 인프라 정리
(이부분 ppt를 저작권 때문에 가져올 수가 없어서 글로 설명하고자 한다.)
AWS에서는 다양한 AI/ML 서비스를 단계별로 제공한다. 상위에는 Bedrock, Amazon Q와 같은 생성형 AI 서비스가 있고, 그 아래로 Personalize, Forecast, Lex, Rekognition 등 다양한 비즈니스 도메인에 특화된 AI 서비스들이 있다.
모델 개발은 SageMaker를 중심으로 구성되며, Jumpstart, Canvas, Studio IDE, Ground Truth 등을 통해 손쉽게 모델을 만들고 학습부터 배포까지 가능하다.
가장 하단에는 ML 프레임워크 및 인프라 계층이 있는데
-
GPU가 포함된 EC2 인스턴스
-
PyTorch, TensorFlow 등의 프레임워크
-
그리고 AWS 자체 칩인 Trainium(학습용), Inferentia(추론용) 도 함께 제공되어 모델 성능과 비용 최적화를 지원한다.
DL
화이트보딩
머신러닝과 전체 흐름은 동일하나, feature engineering과 algorithm 에서 두번의 정확도 하락이 발생하니까 이 부분을 한번만 일어나게 합쳐주는 알고리즘으로 깊어진 것이다.
Feature engineering
라는 input 값들이 잘 나누어지게, 알고리즘에 넣기 전에 정리해주는 부분
-
selection
-
차원 축소 (변경)
+
algorithm (ML)
- linear regression
- rogistic regression
- decision tree
- SVM / boosting
이 두가지를 한번에 처리하는 알고리즘이 생겨났다 ⇒ 인공신경망
algorithm (DL)
- CNN
- RNN
- seq2seq + attention
- transformer
model
← 활성함수 (activation function)
Activation Function
🧠 인간 :
뉴런 하나가 다른 뉴런 하나로 넘어갈 때 모든 신호를 넘겨주면, 신호가 너무 복잡해져서,
특정 임계값을 넘기는 뉴런만을 살린다
한 레이어 → 다른 레이어로 값을 넘겨줄 때 활성함수를 사용
(레이어마다 activation function을 적용해주는 것이다.)
수식으로 따져서, 계속 값을 넘기고 넘기하면, 어차피 x가 하나인 1차함수로 볼 수 있다.
그래서 우리가 보고자 하는 꼬아진, 복잡한 함수를 볼 수가 없게 된다.
그래서 특정 함수의 값에 넣어서 선형함수를 비선형 함수로 만든다. 좀 더 함수를 복잡하게 만들어주는 것이다.
-
sigmoid
-
tanh
⇒ 이 두가지는 (0,1) or (-1,1)에 도달했을 때 → 기울기가 0으로 되면서 값이 없어지는 기울기 소실 문제가 있음
-
Relu (속도가 빠르다)
⇒ 0 밑으로 값을 날리는 것을 보완한 것이 Leacky Relu
-
Leaky Relu
Loss function
- classification
- BCE
- Cross Entropy
- Regression
- MLE
- MSE
- RMSE
- MSE에서 outlier의 영향을 너무 크게 받는 것을 좀 줄이고자 루트를 씌움
optimization 최적화
- 를 얼마나 바꿀 것인지
- 더할 것이냐 뺄 것이냐
- gradient descent
- 내리막이 나오는 곳으로 계속 가는 것
- SGD
- mini-batch GD
- 내리막이 나오는 곳으로 계속 가는 것
- momentum
- 중간 능선에서 멈추지 않고, 내려 오던 방향으로 조금 더 살펴보는 것
- adagrad
- 시작할 때는 움직이는 폭을 크게, 어느정도 내려왔을 때는 보폭 줄이기
- RMS prop
- Adam
- momentum + ada grad
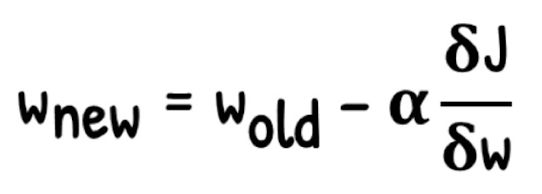
PPT
ANN
과거에는 hidden layer가 하나만 있었다.
지금은 그 은닉층이 많아지고 깊어지면서 → DNN
순전파
우리가 원래 하듯이, 앞에서부터 가중치와 특징을 곱하고 더해가면서 output을 낸다
역전파
output과 실제값의 차이(오차)에 대해서 미분을 하면서 어느부분이 영향을 많이 미쳤는가를 확인하면서 가중치 없데이트를 실행
(순전파 한번 + 역전파 한번) 이게 1 epoch
CNN (Convolution Neural Network)
filter
이미지의 주요 특징이 잘 살아나, 구분할 수 있도록 하는 하는 filter(숫자값)를 만들어줘야 한다.
그 filter를 찾아나가는 과정을 CNN이라고 생각하면 된다.
- Convolution layer input data 에 filter를 행렬 연산 ⇒ feature map 생성
- stride, padding
- Activation layer activation function을 통해 값을 어느정도 정리
- pooling layer 이미지에서, 픽셀과 바로 옆에 있는 픽셀을 거의 유사하므로 그걸 줄여서 계산 속도를 줄이자
- max / average
NLP의 흐름 (NLP : NLU + NLG)
RNN
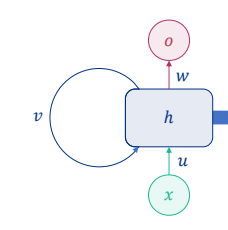
앞에 계산했던 가중치도 뒤의 계산에서 참조해서 뒤의 출력을 계산 (이걸 쭉쭉.. 연결)
ex. 기계 번역 시 나는 강아지를 좋아합니다.
나를 계산할 때 나오는 걸 출력도 하고, 뒷 계산에 넘기는 것
Seq2Seq
- 인코더 : 출력 안내고 정보만 모으는 곳
- 디코더 : 인코더의 출력을 넘겨서 출력을 만들어내는 곳
문제점 : 시퀀스가 길어지면, 앞의 내용이 누락되는 문제가 발생함
Attention
- 인코더 파트에서 → 디코더로 주긴 주는데, 가장 첫번째 출력을 생성하고자 할 때 인코더에서 만들었던 그 해당 부분의 출력을 붙여주는 것
- 내가 지금 생성하려는 부분에 대해, 원본 값을 덧붙여서 보는 것
문제점 : 생성형 AI 시대에서는 너무 텍스트가 길어지니까 계산 시간이 너무 길어지는 문제가 발생
Transformer
- positional encoding을 추가해서, 순서대로 계산한 것을 덧붙여주는데서 오는 문제점을 해결함
- 그래서 순서가 뒤바뀌어도 원래 어느자리인지를 기억할 수 있게 된다.
- 그래서 순차적으로 계산할 필요도 없고, 그래서 한번에 계산이 되고 마지막에 한번에 묶이는 구조라고 생각하기 (병렬처리가 가능해졌다)
Amazon SageMakerAI
- AI 모델을 만들고자 할 때 여기서 만들면 된다. 환경을 모두 만들 수 있는 역할
- 준비, 빌드, 훈련, 배포 관리까지 전부 한큐에 할 수 있게 해준다.
기능
-
데이터 처리 (기능 일부)
- sagemaker data wrangler : 데이터에 공백이 있는지, 잘못된 조건의 데이터가 있는지 UI를 통해서 정리할 수 있게
- sagemaker feature store : 데이터를 앞에서부터 몇개, 뒤에서부터 몇개, 짝수번만, 홀수번만 등 여러 조건으로 저장하고, 그 각각대로 모델을 돌려보고 성능 결과까지 저장해놓고 데이터 feature 확인하고자 할 때 사용
- sagemaker clarify : 데이터 불균형을 찾아주는 기능 (편향된 것을 평가해준다)
- sagemaker ground truth : 데이터에 레이블 달아주는 것
-
모델 개발
- studio lab : 모델 개발 환경을 설정하고 학습 돌려줌
- built - in : import해서 사용
- local mode : 코드 다른데로 빼와서 로컬에서 돌리거나, 로컬에서 돌리던 걸 그대로 올려서 모델 돌려볼 수 있는 것
- autopilot : 알아서 러닝
- jumpstart : 다른 회사에서 만든 모델을 가져와서 fine-tuning 할 수 있게 (사용해볼 수 있는 모델 하나 선택할 수 있게 모아놓음)
-
훈련
- automatic model tuning : 하이퍼파라미터에 대해 범위만 부여해서, 그 범위 안에서 알아서 모델을 돌려보고 최적의 하이퍼파라미터를 선택할 수 있게
- managed spot training : 훈련할 때 노는 스팟 인스턴스 데려와서 돌리다가 뺏기는 것, 근데 얘는 돌리다가 체크포인트를 찍어놓고 인스턴스 뺏기면 다시 노는 애 데려와서 그 부분부터 다시 훈련! (비용 절감 최고)
- sagemaker experiment : 지금까지 돌린 모델 결과를 한 눈에 시각화해서 볼 수 있게
-
배포
- inference
- real-time : 요청이 들어오면 바로 답변 해주는 것
- asynchronous : 바로 답변 받기에는 지연 시간이 좀 있어도 되거나, 사이즈가 큰 경우, 던져놓고 다른거 먼저 처리하고 다 되면 답변 주는 것 (SQS이랑 비슷한 느낌)
- batch : 지금 당장 보지 않아도 되는 경우 (예약 걸어놓는 느낌)
- severless : 트래픽이 거의 없는 경우
- shadow testing : 원래 돌아가던 모델과 새 모델에 대해 둘 다 요청을 던짐 → 기존의 것은 요청을 처리 & 새 모델은 로그만 쌓아서 개발자가 제대로 작동할 수 있는지만 검증할 수 있도록 하는 곳
- inference
domain
우리가 작업을 할 공간을 생성 : 도메인 생성
도메인 하나에 디폴트로 EC2가 최소 두개가 뜨기 때문에 비용이 자동으로 나감
- 주피터 노트북용 하나
- 학습용 하나
data wrangler로 데이터 준비 및 정리
- 여기서 이 데이터로 어떻게 결과가 나올지도 알려줌
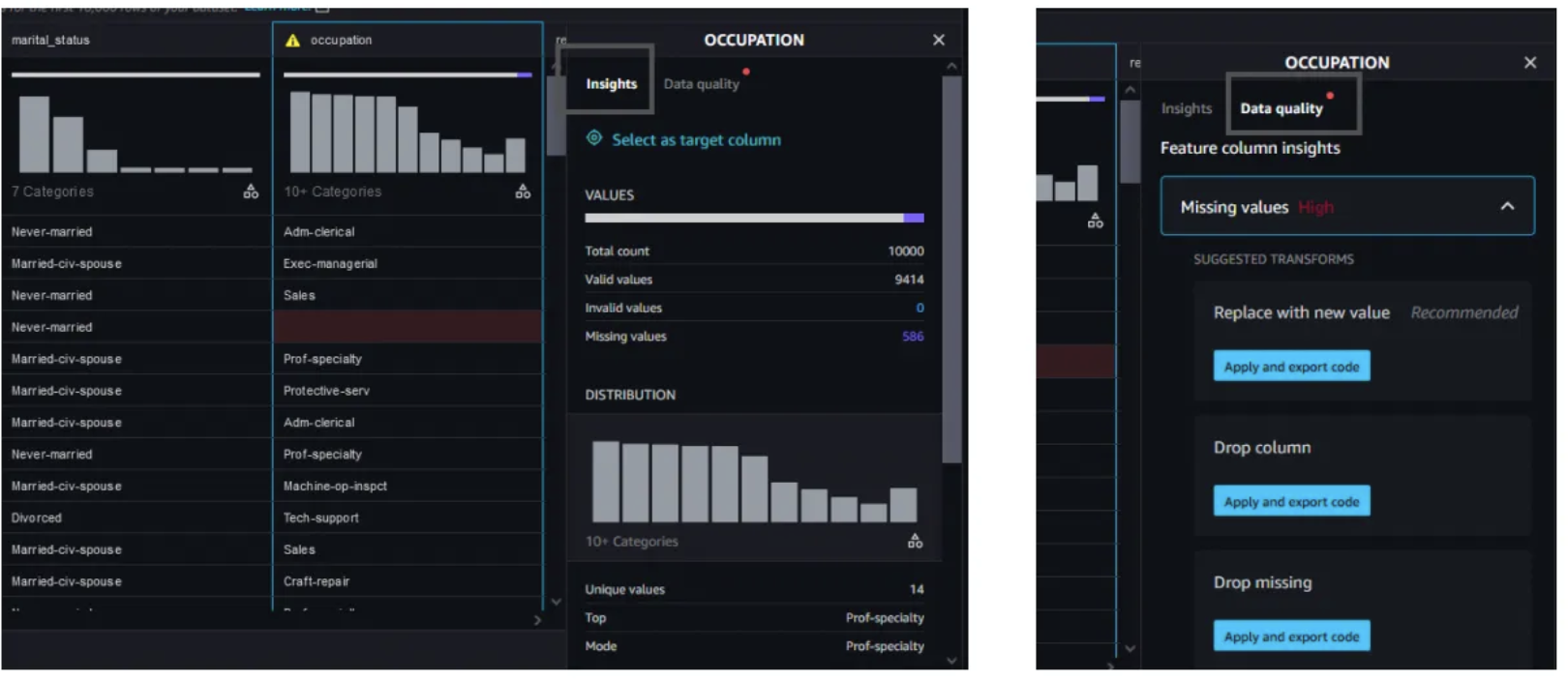 data wrangler와 관련해서는 따로 정리해놓은 실습 글을 확인하면 좋을 것 같다
data wrangler와 관련해서는 따로 정리해놓은 실습 글을 확인하면 좋을 것 같다
훈련
ECR에 자주 사용되는 알고리즘이 들어가 있으므로, 그 내에서 사용하고자 하는 알고리즘을 가져와서 정의만 해주면 사용할 수 있다. (esimator 지정)
직접 코딩
물론, tensorFlow 나 pytorch로 알고리즘 짜서 사용해도 된다 (python 형식)
BYOC
내가 이미지를 만들어 놓았다면, ECR에 이미지 올리고 불러와서 사용할 수도 있다.
학습 fit
배포 deploy
추론 predictorAmazon Sagemaker canvas
지도 학습에 대부분 맞춰서 돌릴 수 있다
이미 있는 모델 가져와서 한다?
❓ studio랑 어떻게 다름..?
- studio는 완전히 처음부터 코딩을 할 수 있는 환경
- canvas는 aws가 가지고 있는 알고리즘 중에 가져와서 모델을 알아서 만들어주는 환경Generative AI
정의 :
- 무엇이 되었든 무언가를 답을 ‘생성’해서 반환해주는 것
- 방대한 데이터를 사용한다
- 과거에는, 원하는 도메인에 관련한 데이터만 모아서 학습시킴
- 목적 대상 없이, 방대한 데이터를 모두 모아서 학습시키는 것이 생성형 AI
문제점:
- 지식의 단절
- 특정 도메인에 집중되지 못한다
- hallucination
이를 해결하기 위하여, 생성형 AI를 foundation model로 깔고 customizing 한다
커스터마이징 방법
-
prompt engineering
: 내가 원하는게 뭔지 정확하게 입력해줘야 한다.
-
RAG
-
Agentic AI
-
Fine-tuning
-
모델 직접 설계
2, 3번은 모델을 바꾸지 않고, 무언가를 연결하는 것
4, 5번은 모델에 무언가를 바꾸는 것prompt engineering
- prompt
- 지시, 컨텍스트, 입력 데이터, 출력 지시자
- one-shot, few-shot, zero-shot prompting
- CoT prompting : 하나하나 생각의 순서를 지시하는 것
- self-consistency
- react
RAG
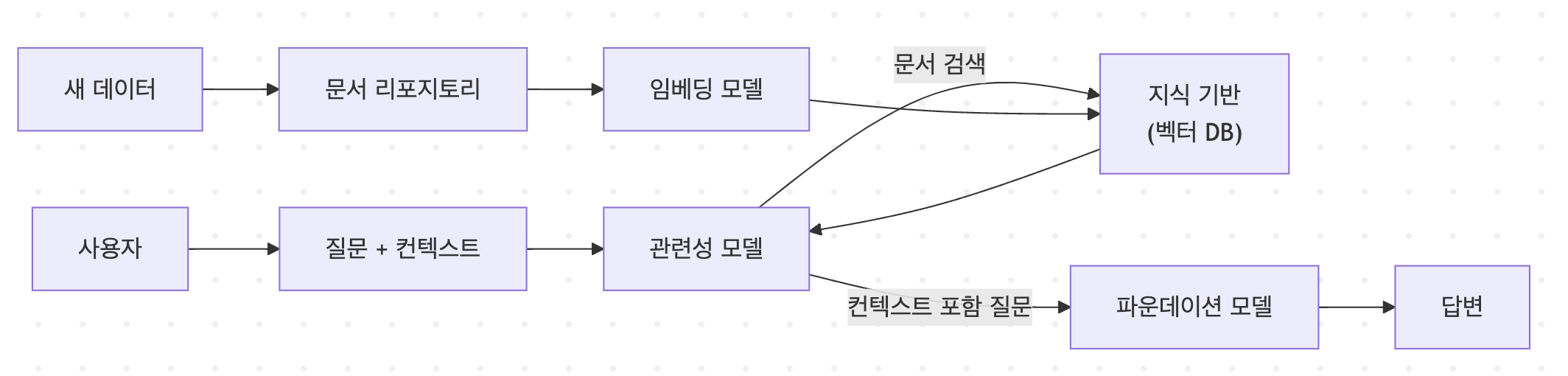
우리 문서를 chunk 단위로 DB에 저장, 저장하기 전에 자연어로 넣으면 컴퓨터는 이해하지 못하기 때문에 자연어를 숫자로 바꾸는 embedding 변환 과정이 필요하다.
그래서 RAG가 잘 작동하려면, embedding 모델이 무엇을 사용하느냐가 매우매우 중요하다.
사용자 요청시,
R : 가장 처음! 우리의 벡터 DB로 가서 질문과 가장 가까운 값을 가지는 값이 있는 chunk를 가져온다
A : 다음, 받은 chunk를 foundation 모델에 준다. 그 모델은 원래 알고 있는 데이터에 그 데이터가 붙는다
G : 마지막에 이제 답변을 생성하지만, 모델이 너무 많이 붙으니까 정확도가 떨어지게 된다
그래서 나온 것이 advanced rag
advanced rag
chunking
- 이제 문자 갯수로 자르지 않고, 의미가 유사한대로 붙은 semantic chunking
- 검색은 자식으로, foundation 모델은 부모를 준다
- 검색은 300씩, 증강으로 줄때는 앞뒤로 100개 더 붙여서 더 많이 정보를 넘겨주기
retrieval
- 단어로 질문이 오는 경우, 알아서 쿼리를 더 추가해서 질문을 받게끔
- 동의어를 추가하는 경우
- 쿼리의 구조를 변경하는 경우
- hybrid
- chunk를 받으면, 이에 받을만한 질ㄹ문을 먼저 만들어 놓고 실제질문이랑 비교함
- hyde
- 질문을 받으면, foundation 모델이 한번 결과값 만들고 chunk랑 비교
- rerank
- chunk를 여러 개 받아온 뒤, 그 중에서 질문과 가장 유사도가 높은 문서를 다시 골라주는 과정
- 시간 비용이 오래 걸린다는 문제가 있음
- cache
- foundation 모델 앞에 캐싱 기능을 붙인다
- 비슷한 질문에 대해서는 캐시된 데이터에서 답변 나가면서 돈과 지연시간을 줄이기 위함
Agentic AI
- foundation model = 에이전트가 되어서 그 옆에 막 애플리케이션을 붙이는 것
- 서드파티 애플리케이션을 붙인다고 생각하면 된다
- 예를들어, 날씨에 대해 물어보면 날씨앱에 보내는 것
- 계산 물어보면 계산기로 보냄
- 에이전트로 rag를 붙일수도 있다
수업을 들으면서, 요즘 가장 유행하는 기술을 무엇인지를 다시 한 번 업데이트할 수 있어서 좋았다. 그리고 지금까지 내가 배워온 이론들이 어떤 흐름으로 적용되는 건지 한 번 더 복습할 수 있는 시간이었다. 덕분에 한층 더 단단히 기본이 다져진 것 같다! 💪
그리고 강사님께서 생성해주신 bedrock을 이용한 rag 챗봇 만들기 워크샵 실습을 진행했다. 아마존 서비스 내에서 손쉽게 클로드를 연결하고, 우리가 가진 문서를 s3 버킷에 업로드하고 그 둘을 연결해 streamlit으로 사용해보는 실습이었다. (그동안은 api 끌고오고.. 이랬는데 그냥 ui 클릭 클릭만으로 만들어지는게 신기하고 편리했다)
이론뿐만이 아니라, 진짜 실무에서 바로 실행할 수 있는 부분이라는 생각이 들어서 열심히 따라갔던 것 같다 ❤️🩹
