
1. CatBoost 모형
-
범주형 변수 처리에 특화된 boosting 기반 알고리즘이며 Level-wise 방식의 트리 확장기법 및 Ordered Boosting 방식을 사용하는 특징이 있음
-
Level-wise 트리 확장기법: 대칭적인 트리 구조로 트리를 확장해나감(XGBoost의 ‘depthwise’와 동일
level-wise 트리 확장기법
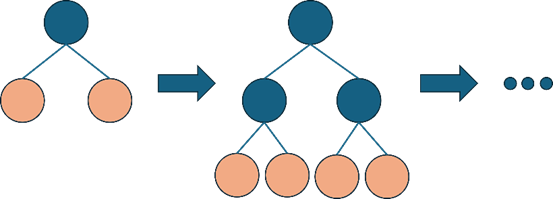
-
Ordered Boosting: 일부 데이터만 가지고 잔차계산을 한 뒤, 모델을 만들어 나머지 데이터의 잔차를 이 모델로 예측한 값을 활용
-
-
장점
- 범주형 데이터를 라벨 인코딩하지 않아도 자동으로 인코딩하며 카테고리형 변수가 많은 데이터셋에서 다른 알고리즘에 비해 좋은 성능을 보임
- 하이퍼파라미터 튜닝 없이도 기본값으로 좋은 성능을 냄
- 순열 기반 학습 및 다른 정규화 기술을 이용하므로 다른 부스팅 알고리즘들보다 과적합을 잘 방지하는 것으로 알려짐
-
단점
- 결측치를 처리해주지 않음
- Sparse Matrix, 즉 결측치가 매우 많은 데이터셋에는 매우 부적합
- 데이터 대부분이 수치형 변수인 경우 LightGBM보다 학습 속도가 느림
-
주요 하이퍼파라미터
Iterations=500트리의 최대 개수
learning_rate=0.03단계별 모델의 가중치
depth=6개별 트리의 깊이
l2_leaf_reg=3L2 규제의 계수
rsm=None단계별 트리 적합 시 사용할 변수의 비중
feature_border_type='GreedyLogSum'수치형 변수를 이산화할 때 로직
{'Median', 'Uniform', 'UniformAndQuantiles', 'GreedyLogSum', 'MaxLogSum', 'MinEntropy'}
nan_mode=’Min’수치형 변수의 결측치 처리방식
{‘Forbidden’: 결측치 제외, ‘Min’:최소값 대체, ‘Max’: 최대값 대체

의미 있는 한걸음을 추구합니다.