
1. 서포트벡터머신(Support Vector Machine)
-
두 카테고리 중 어느 하나에 속한 데이터의 집합이 주어졌을 때, 두 카테고리의 가장 큰 폭의 경계를 찾는 알고리즘
- 초평면: 차원이 p인 공간에서 차원이 p-1인 평평한 아핀(affine) 부분공간
- 마진(Margin): 관측치들에서 초평면까지 가장 짧은 거리
- 서포트 벡터: 양의 초평면과 음의 초평면에 접한 관측값
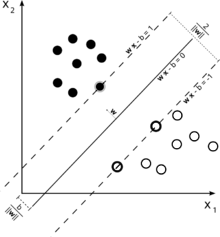
-
클래스의 경계가 비선형인 상황에서는 커널(Kenel)을 활용하여 알고리즘 적용 가능(Kernel Trick)
커널 트릭(Kernel Trick)
저차원의 데이터를 고차원으로 확장한 후 마진을 최대화하는 초평면을 찾는 기법
고차원으로 확장된 벡터를 내적하여 스칼라를 만드는데, 벡터 변환과 내적을 건너뛰고
원 데이터를 바로 스칼라 공식에 대입하여 차원을 확장하는 기법이다. (Wow...) -
장점
- 고차원 데이터에서 좋은 성능을 보임
- 비선형 분류문제 처리 가능
- 고차원 공간에서도 과적합이 덜 발생
-
단점
- 이진분류만 가능(커다란 단점)
- 샘플 수나 변수가 많은 경우 훈련 시간이 오래걸림
- 하이퍼파라미터 튜닝이 복잡함
- 이상치에, 특히 결정 경계 근처의 이상치에 민감함
-
파이썬 코드 예시
from sklearn.svm import SVC model=SVC() model.fit(x, y) -
주요 하이퍼파라미터
C=1.0정규화 파라미터, 작을수록 강한 규제
kernel='rbf'커널 함수 종류 선택, {'linear', 'poly', 'rbf', 'sigmoid', 'precomputed'}, 'rbf'는 random forest를 의미
degree=3커널 함수가 ‘poly’인 경우 차수
gamma='scale'‘{'scale', 'auto'} or float, 커널 함수가 'poly', 'rbf', 'sigmoid'인 경우 커널의 계수
probability=False클래스가 아닌 확률 추정 여부, 5-fold CV를 이용한다.
random_state=Nonedata 혼합 시 radom seed
Probalility=FalseTrue인 경우 분류 라벨이 아닌 확률을 반환한다.
2. 앙상블 배깅 분류모형
-
주어진 자료를 모집단으로 간주하여 주어진 자료에서 여러 개의 붓스트랩 자료를 생성하고 각각의 붓스트랩 자료에 예측모형을 만든 후 결합하여 최종 예측모형을 만드는 방식
배깅(Bagging, Bootstarp Aggregating)과 붓스트랩(Bootstrap)
붓스트랩이란 주어진 자료에서 단순랜덤 복원추출 방법을 활용하여 동일한 크기의 표본을 여러 개 생성하는 샘플링 방법을 의미하며, 배깅은 이러한 붓스트랩 샘플을 이용한 앙상블모델을 의미
- 붓스트래핑(Bootstraping) – 모델링(Modeling) – 보팅(Voting)의 순서로 진행하며 각 붓스트랩에 대해 모델링 과정이 병렬적으로 수행됨
- 보팅(Voting): 여러 개의 모형으로부터 산출된 결과 중 다수결에 의해 최종 결과를 산정하는 과정
- Out of Bag: 붓스트래핑에서 샘플링 시 선택되지 않은 훈련데이터(평균적으로 샘플의 약 37%), 모델의 성능평가를 수행하는 데 활용할 수 있음
Out-Of-Bag 샘플
붓스트랩 샘플링에서 추출되지 않은 나머지 데이터샘플
즉, 붓스트랩 샘플링은 전체 데이터를 'in-the-bag' 샘플과 'out-of-bag' 샘플로 나눠 복원추출한다.
-
장점
- 단일 모델에서 발생할 수 있는 과적합 문제를 완화할 수 있으며 안정성이 증가
- 기본 모델의 종류에 상관없이 적용 가능
- 각 기본모델이 독립적으로 학습되므로 병렬 처리 가능
-
단점
- 기본 모델들이 서로 다른 예측을 내릴 가능성이 있어야 효과적이며 기본 모델들이 매우 유사한 경우 배깅의 이점이 크게 줄어들 수 있음
- 개별 모델이 어떤 의사결정을 내렸는지 추적하기 어려움
- 기본모델의 하이퍼파라미터를 튜닝하고 최적화하는 데 시간과 난이도가 증가
-
파이썬 코드 예시
from sklearn.ensemble import BaggingClassifier model = BaggingClassifier() model.fit(X, y) -
주요 하이퍼파라미터
estimator=None붓스트랩한 샘플을 학습시킬 기본모델, 지정 안하면 의사결정나무(DecisionTreeClassifier)로 자동지정
n_estimators=10앙상블에 들어갈 기본모델의 수
max_samples=1.0각 기본 모델을 추정하기 위해 추출할 샘플의 수
max_features=1.0각 기본 모델을 추정하기 위해 선택할 변수의 수
bootstrap=True데이터를 복원 붓스트래핑을 할지 여부 설정, False 설정하는 경우 비복원 추출
bootstrap_features=False변수를 복원 붓스트래핑을 할지 여부 설정, False 설정하는 경우 비복원 추출
oob_score=Falseout-of-bag 샘플로 score를 계산할지 여부 설정, bootstrap = True인 경우에만 사용 가능
random_state붓스트래핑 시 샘플링 랜덤시드
